
在电商领域,推荐的价值在于挖掘用户潜在购买需求,缩短用户到商品的距离,提升用户的购物体验。
京东推荐的演进史是绚丽多彩的。京东的推荐起步于2012年,当时的推荐产品甚至是基于规则匹配做的。整个推荐产品线组合就像一个个松散的原始部落一样,部落与部落之前没有任何工程、算法的交集。2013年,国内大数据时代到来,一方面如果做的事情与大数据不沾边,都显得自己水平不够,另外一方面京东业务在这一年开始飞速发展,所以传统的方式已经跟不上业务的发展了,为此推荐团队专门设计了新的推荐系统。

随着业务的快速发展以及移动互联网的到来,多屏(京东App、京东PC商城、M站、微信、手Q等)互通,推荐类型从传统的商品推荐,逐步扩展到其他类型的推荐,如活动、分类、优惠券、楼层、入口图、文章、清单、好货等。个性化推荐业务需求比较强烈,基于大数据和个性化推荐算法,实现向不同用户展示不同内容的效果。为此,团队于2015年底再次升级推荐系统。2016年618期间,个性化推荐大放异彩,特别是团队开创的“智能卖场”,实现了活动会场的个性化分发,不仅带来GMV的明显提升,也大幅降低了人工成本,大大提高了流量效率和用户体验,从而达到商家和用户双赢,此产品获得了2016年度的集团产品。为了更好地支撑多种个性化场景推荐业务,推荐系统一直在迭代优化升级,未来将朝着“满屏皆智能推荐”的方向发展。
推荐产品
用户从产生购买意向,到经历购买决策,直至后下单的整个过程,在任何一个购物链路上的节点,推荐产品都能在一定程度上帮助用户决策。
1. 推荐产品发展过程
推荐产品发展历程主要经历了几个阶段,由简单的关联推荐过程到个性化推荐,逐步过渡到场景智能推荐。从相关、相似的产品推荐过渡到多特征、多维度、用户实时行为、结合用户场景进行的全方位智能推荐。
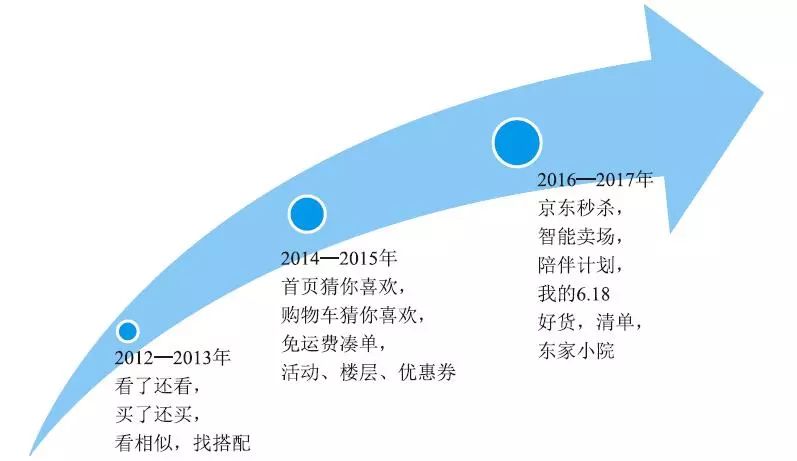 推荐产品发展历程
推荐产品发展历程
2. 多屏多类型产品形态
多类型主要指推荐类型覆盖到多种类型,如商品、活动、分类、优惠券、楼层、入口图、文章、清单、好货等。在移动互联时代,多屏场景非常普遍,整合用户在多屏的信息,能使个性化推荐更精准。多屏整合的背后技术是通过前端埋点,用户行为触发埋点事件,通过点击流系统进行多屏的行为信息收集。这些行为数据通过实时流计算平台来计算用户的兴趣偏好,从而根据用户兴趣偏好对推荐结果进行重排序,
达到个性化推荐的效果。京东多屏终端如下图所示。
推荐系统架构
1. 整体业务架构
推荐系统的目标是通过全方位的精准数据刻画用户的购买意图,推荐用户有购买意愿的商品,给用户好的体验,提升下单转化率,增强用户黏性。
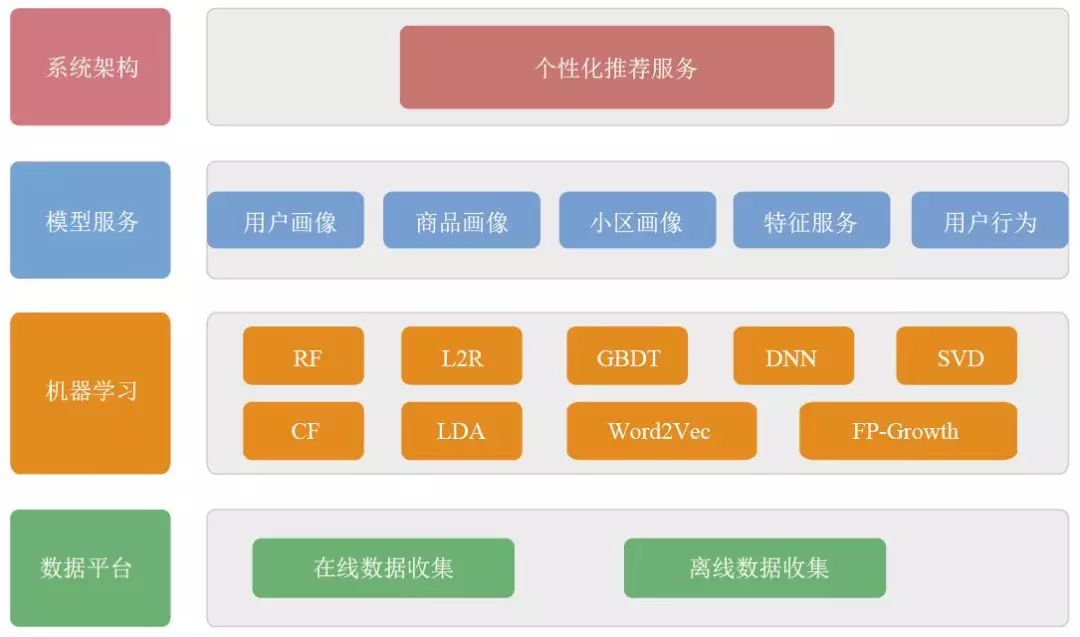
推荐系统的业务架构
系统架构。对外提供统一的 HTTP 推荐服务,服务京东所有终端的推荐业务。
模型服务。为了提高个性化的效果而开发的一系列公共的个性化服务,用户维度有 用户行为服务和用户画像服务,商品维度有商品画像,地域维度有小区画像,特征维度有特征服务。通过这些基础服务,让个性化推荐更简单、更精准。
机器学习。算法模型训练阶段,尝试多种机器学习模型,结合离线测评和在线 A/B, 验证不同场景下的算法模型的效果,提高推荐的转化率。
数据平台。数据是推荐的源泉,包括数据收集和数据计算。数据虽然是整体推荐架 构的底层,却是非常重要的,因为数据直接关系到推荐的健康发展和效果提升。
2. 个性化推荐架构
在起步初期,推荐产品比较简单,每个推荐产品都是独立服务实现。新版推荐系统是一个系统性工程,其依赖数据、架构、算法、人机交互等环节的有机结合。新版推荐系统的目标,是通过个性化数据挖掘、机器学习等技术,将“千人一面”变为“千人千面”,提高用户忠诚度和用户体验,提高用户购物决策的质量和效率;提高网站交叉销售能力,缩短用户购物路径,提高流量转化率(CVR)。目前新版推荐系统支持多类型个性化推荐,包括商品、店铺、品牌、活动、优惠券、楼层等。

新版个性化推荐系统架构
个性化推荐系统架构图中不同的颜色代表不同的业务处理场景:
数据处理部分(底层灰色模块),包括离线数据预处理、机器学习模型训练,以及在线实时行为的接入、实时特征计算。
推荐平台(蓝色模块),主要体现响应用户请求时推荐系统的各服务模块之间的交互关系。推荐系统核心模块:
推荐网关。推荐服务的入口,负责推荐请求的合法性检查、请求分发、在线 Debug 以及组装请求响应的结果。
调度引擎。负责推荐服务按策略调度及流量分发,主要根据配置中心的推荐产品的 实验配置策略进行分流,支持按用户分流、随机分流和按关键参数分流。支持自定义埋点, 收集实时数据;支持应急预案功能,处理紧急情况,秒级生效。
推荐引擎。负责推荐在线算法逻辑实现,主要包括召回、过滤、特征计算、排序、
多样化等处理过程。
个性化基础服务。目前主要个性化基础服务有用户画像、商品画像、用户行为、预 测服务。用户画像包括用户的长期兴趣、短期兴趣、实时兴趣。兴趣主要有性别、品牌偏好、品类偏好、购买力等级、自营偏好、尺码颜色偏好、促销敏感度、家庭情况等。商品画像主要包括商品的产品词、修饰词、品牌词、质量分、价格等级、性别、年龄、标签等。用户行为主要获取用户近期行为,包括用户的搜索、点击、关注、加入购车、下单等。预测服务主要是基于用户的历史行为,使用机器学习训练模型,用于调整召回候选集的权重。
特征服务平台。负责为个性的服务提供特征数据和特征计算,特征服务平台主要针对 特征数据,进行有效的声明、管理,进而达到特征资源的共享,快速支持针对不同的特征进行有效的声明、上线、测试以及A/B 实验效果对比。提供个性化迭代速度。
个性化技术(黄色模块),个性化主要通过特征和算法训练模型来进行重排序,达到精准推荐的目的。特征服务平台主要用于提供大量多维度的特征信息,推荐场景回放技术是指通过用户实时场景特征信息反馈到推荐排序,在线学习(Online-Learning)和深度学习都是大规模特征计算的个性化服务。
个性化推荐系统的主要优势体现为支持多类型推荐和多屏产品形态,支持算法模型A/ B 实验快速迭代,支持系统架构与算法解耦,支持存储资源与推荐引擎计算的解耦,支持预测召回与推荐引擎计算的解耦,支持自定义埋点功能;推荐特征数据服务平台化,支持推荐场景回放。
数据平台
京东拥有庞大的用户量和全品类的商品以及多种促销活动,可以根据用户在京东平台上的行为记录积累数据,如浏览、加购物车、关注、搜索、购买、评论等行为数据,以及商品本身的品牌、品类、描述、价格等属性数据的积累,活动、素材等资源的数据积累。这些数据是大规模机器学习的基础,也是更地进行个性化推荐的前提。
1. 数据收集
用户行为数据收集流程一般是用户在京东平台(京东App、京东PC 网站、微信手Q) 上相关操作,都会触发埋点请求点击流系统(专门用于收集行为数据的平台系统)。点击流系统接到请求后,进行实时消息发送(用于实时计算业务消费)和落本地日志(用于离线模型计算),定时自动抽取行为日志到大数据平台中心。算法人员在数据集市上通过机器学习训练模型,这些算法模型应用于推荐服务,推荐服务辅助用户决策,进一步影响用户的购物行为,购物行为数据再发送到点击流,从而达到数据收集闭环。
2. 离线计算
目前离线计算平台涉及的计算内容主要有离线模型、离线特征、用户画像、商品画像、用户行为,离线计算主要在Hadoop 上运行MapReduce,也有部分在Spark 平台上计算,计算的结果通过公共导数工具导入存储库。团队考虑到业务种类繁多、类型复杂以及存储类型多样,开发了插件化导数工具,降低离线数据开发及维护的成本。
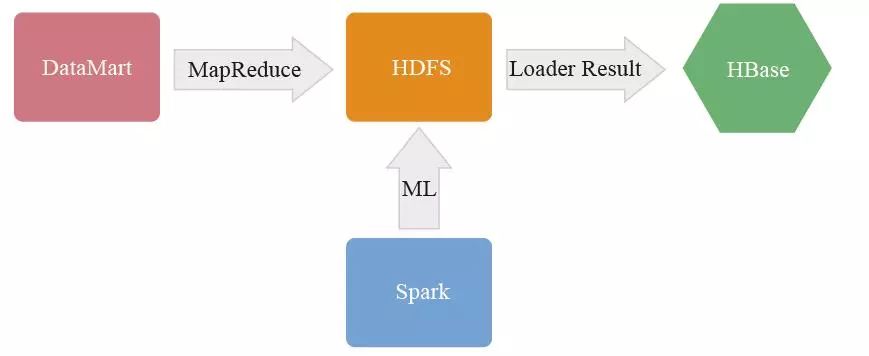
数据离线计算架构
3. 在线计算
目前在线计算的范围主要有用户实时行为、用户实时画像、用户实时反馈、实时交互特征计算等。在线计算是根据业务需求,快速捕捉用户的兴趣和场景特征,从而实时反馈到用户的推荐结果及排序,给用户专属的个性化体验。在线计算的实现消息主要来源于Kafka 集群的消息订阅和JMQ 消息订阅,通过Storm 集群或Spark 集群实时消费,推送到Redis 集群和HBase 集群存储。

数据在线计算架构
推荐引擎
推荐系统涉及的技术点比较多,考虑到篇幅有限,这里重点介绍个性化推荐中比较重要的部分之一——推荐引擎。
个性化推荐系统的核心是推荐引擎,推荐引擎的一般处理过程是召回候选集,进行规则过滤,使用算法模型打分,模型融合排序,推荐结果多样化展示。主要使用的技术是机器学习模型,结合知识图谱,挖掘商品间的关系,按用户场景,通过高维特征计算和海量召回,大规模排序模型,进行个性化推荐,提升排序效果,给用户的购物体验。
推荐引擎处理逻辑主要包括分配任务,执行推荐器,合并召回结果。推荐器负责召回候选集、业务规则过滤、特征计算、排序等处理。
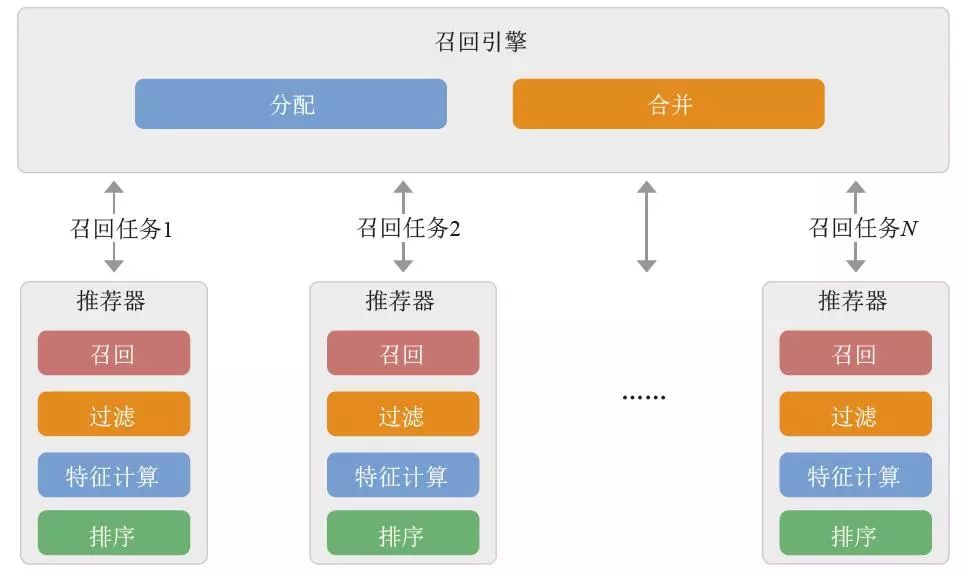
推荐引擎技术架构
分配。根据推荐场景,按召回源进行任务拆分,关键是让分布式任务到达负载均衡。
推荐器。推荐引擎的核心执行组件,获取个性化推荐结果,推荐器的实现如图7-19 所示。
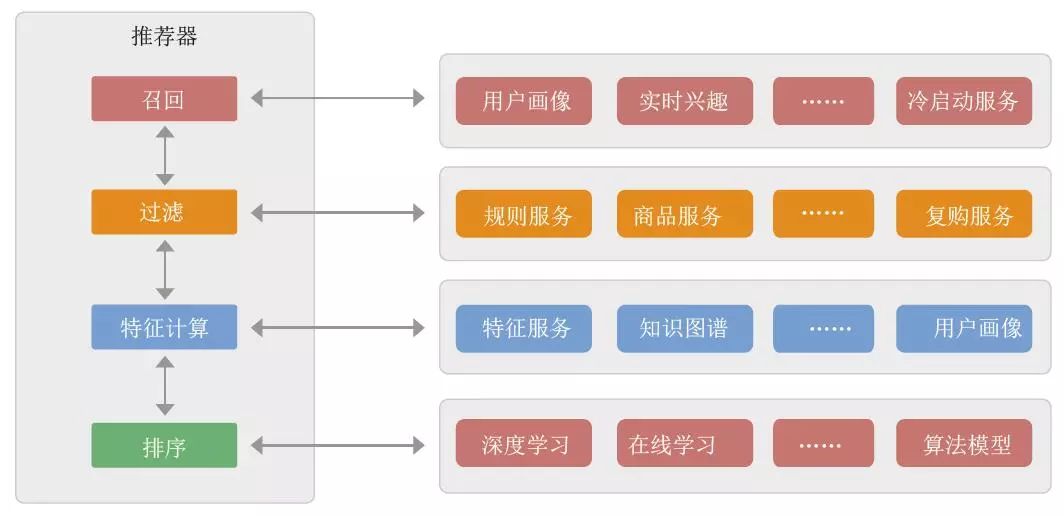
推荐器架构
召回阶段。获取候选集,一般从基于用户画像、用户偏好、地域等维度进行召回, 如果是新用户的召回资源不够,会使用冷启动服务进行召回。
规则过滤阶段。对人工规则、一品多商、子母码、邮差差价等进行过滤。
特征计算阶段。结合用户实时行为、用户画像、知识图谱、特征服务,计算出召回
的候选集的特征向量。
排序阶段。使用算法模型对召回候选集打分,根据召回源和候选集的分值,按一定的策略对候选集进行重新排序。
合并。归并多个推荐器返回的推荐结果,按业务规则进行合并,考虑一定的多样性。
举例来说,京东App首页“猜你喜欢”的实现过程如下图。
首先根据用户画像信息和用户的近期行为及相关反馈信息,选择不同的召回方式,进行业务规则过滤;对满足要求的候选商品集,提取用户特征、商品特征、用户和商品的交叉特征;使用算法模型根据这些特征计算候选商品的得分;根据每个商品的得分对商品进行排序,同时会丰富推荐理由,考虑用户体验,会对终排好序推荐结果进行微调整,如多样性展示。

猜你喜欢实现过程图
