前面我们介绍了分区表的创建与查询,同时也介绍了分区查询的机制。当q启动会话但是不带salve的时候,这只是一个内存上的提升,但是性能上并没有提升(除非减少所需的数据操作量)。当q启动的时候带有slaves的时候,就可以在性能方面上得到一个替身。
在大型时间序列数据库中,查询通常是I / O绑定的。在这种情况下,在I/O通道较少的情况下,分区查询的多个从属设备大部分时间都是在等待I/O的通道上。该解决方案需要多个I/O通道,以便数据检索和处理可以并行进行。Kdb +提供了另一级数据分解,以便在此方案中启用并行处理。那就是分段的思想。
1. 定义与分段方式
分段表是分区表的一个更别的结构,分段将是将具有相同结构的的根目录的分区表扩展到多个目录下结构。每个段都是一个包含分区目的集合目录。段目录可能位于独立的I / O通道上,因此数据检索可以并行进行。
可以使用任何条件来分解分区切片(但是在分区表中只能采用数字类型的分区指标),只要结果符合表中的数据不相交且分段后记录完整,即重构原始表没有遗漏或重复。分解可以沿着行,沿着分区或者通过它们的某种组合,但是不能仅沿着列来分解,因为所有记录必须符合分解的要求。
重要:须确分段后记录的数据完整,而且不能交叉,因为kdb +在写入数据文件时不会检查这一点。特别是,重叠段将导致查询结果中出现重复记录,不完整分解将导致记录丢失。
可以将分段表看成一个三维的结构:首先是扩展的形式按照列来分割,然后再通过水平进行分区,后在整个物理结构上进行分段。分段的主要目的是能够并行使用多个I/O通道和并发处理。我们可以从下面的结构图来理解分段表。
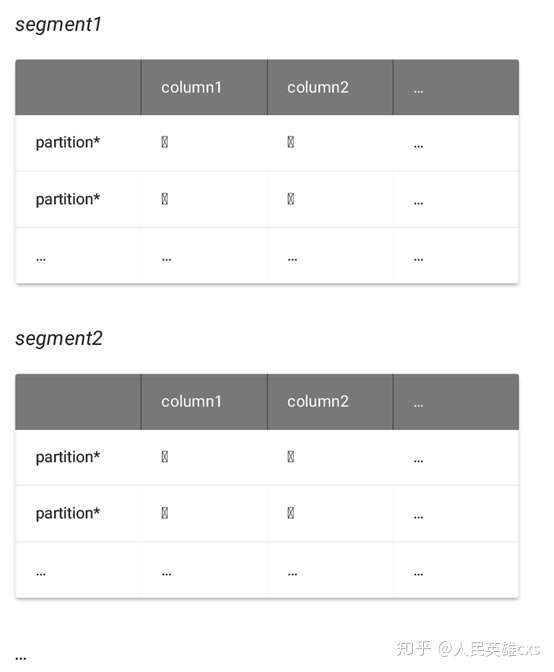
这里的每一个小方框都是一个分区后的实例。
与分区表位于根目录下的布局相反,分段目录不能位于根目录下,根目录下只包含两个文件,一个是par.txt文件,一个是sym文件。par.txt文件中包含段的物理位置的路径,每行一个段路径。
下面的图是本地的文件结构图:
张图是创建好分段表后的文件目录,这里db就是根目录,文件夹1和文件夹2就是我们分段目录。可以看到目录1和目录2不在我们的根目录db下。
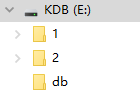
第二张图是我们的层级结构目录,我们可以看到目录1和目录2下面的对应的分区目录和扩展目录。这里分区目录就是2019.01.01等,扩展目录就是t。
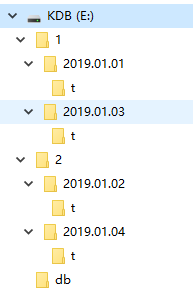
第三张图就是我们的根目录下的文件,根目录下只包含par.txt文件和symbol数据的枚举的sym文件。
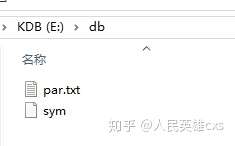
第四张图就是par.txt文件中的内容,可以看到就是我们非分段目录的根目录,每个段是一行。

第五张图就是我们的扩展表t下面的文件,都是包含具体表的数据信息。
我们可以从下面的本地系统目录文件结构中来理解分段表:
/db
[sym]
par.txt
=============== <- 通道 1
/segment1
/partition*
/table*
/table*
…
/partition*
/table*
/table*
…
=============== <- 通道2
/segment2
/partition*
/table*
/table*
…
/partition*
/table*
/table*
…
=============== …下面我们从更具体的形式来展示不同的分段策略,具体的分段策略可以依据自己的数据结构情况与查询操作的方式来建立。
1) 按每日数据交替分段
/1 <- 段1
/2019.01.01
/t <- 日交易数据
/2019.01.03
/t <- 日交易数据
…
=============
/2 <- 段 2
/2019.01.02
/t <- 日交易数据
/2019.01.04
/t <- 日交易数据
…上面这种分段方式,能够将日数据均匀分布在段1和段2的目录下,这样能够提高数据的查询速度,比如我们可以建立5个端,每周一到周五分别在一个段,后所有周一数据在一个段,所有周二数据在一个段,以此类推。
2) 将每日数据按照字母排序的方式进行分段
/am <- 段am
/2019.01.01
/t <- 股票名称中a~m的数据
/2019.01.02
/t <- 股票名称中a~m的数据
…
=============
/nz <- 段nz
/2019.01.01
/t <- 股票名称中n~z的数据
/2019.01.02
/t <- 股票名称中n~z的数据
…上面这种形式是我们基于股票名称的这种symbol数据的一个分段形式,一天的交易数据也会夸多个分段,如2019.01.01这一天的数据就会分布在段am和段nz中。我们也可以按字母分段分的更加细分。
3) 将每日数据按照交易所进行分段
/SHSE <- 上海证券交易所
/2019.01.01
/t <- 上海证券交易所的日数据
/2019.01.02
/t <- 上海证券交易所的日数据
…
=============
/ SZSE <- 深证证券交易所
/2019.01.01
/t <- 深证交易所的日数据
/2019.01.02
/t <- 深证交易所的日数据上面我们是按照交易所来进行分段,分为上海证券交易所与深圳证券交易所段。也可以推广到全球的交易所市场。
4) 将每日数据按照非均匀的方式进行分段
/seg A <- 段A
/2019.01.01
/t <-01.01这一整天的数据
/2019.01.02
/t <- 01.02这一天上午的数据
=============
/seg B <- 段B
/2019.01.02
/t <- 01.02这一天下午的数据
/2019.01.03
/t <- 01.03这一整天的数据
=============
/seg C <- 段C
/2019.01.04
/t <- 01.04这一天的数据上面是按照非均匀的分段方式,有些数据是夸段的,有些数据则不是。如果查询模式在一天内不是均衡的,这种分段可能有用。
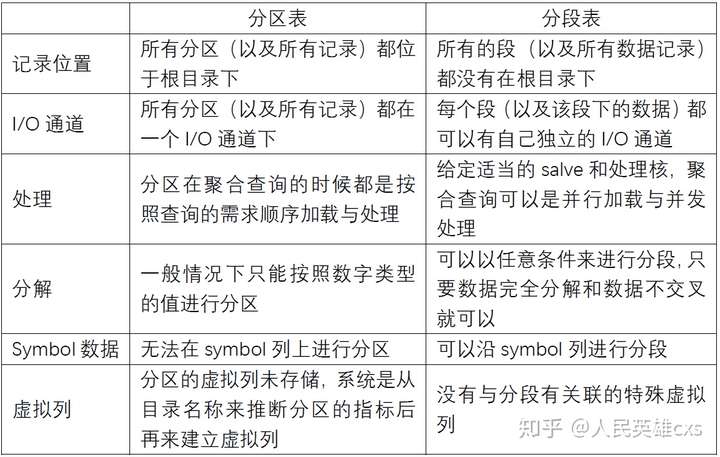
二. 分段表与分区表的区别
三. 创建分段表
分段表的创建是多元化的,根据自己的需求来进行穿件,因此没有一种标准的形式来进行分段。因此你可以自己来写一个q程序来将一个每个分区的子集放到一个段下面。也可以通过在数据加载的脚本中包含创建分段和分区的逻辑结构,来提取分区中的子集放入到对应的分区目录下。
除了创建分区外,也得创建par.txt文件,该文件包含了分的段所在的路径,每一个段对应一个路径,而且占一行,并将该文件放在根目录下。
注意,段的目录和数据一定不能再跟目录下。
接下来开始演示创建前面介绍的几种分段的类型。
1. 按日交替分段
首先是每日数据的交替存储在不同的段下面。这样可以让查询的时候均匀索引本地数据。
伪结构如下:
/1
/2019.01.01
/t
/2019.01.03
/t
/2
/2019.01.02
/t
/2019.01.04
/t对应的par.txt文件内容如下:
/1
/2创建方式如下:
1)首先是对表通过.Q.en进行分区,然后再序列化到分的段的对应目录下
q)`:/1/2019.01.01/t/ set .Q.en[`:/db;] ([] ti:09:30:00 09:31:00; s:`ibm`t; p:101 17f)
`:/1/2019.01.01/t/
q)`:/2/2019.01.02/t/ set .Q.en[`:/db;] ([] ti:09:30:00 09:31:00; s:`ibm`t; p:101.5 17.5)
`:/2/2019.01.02/t/
q)`:/1/2019.01.03/t/ set .Q.en[`:/db;] ([] ti:09:30:00 09:31:00; s:`ibm`t; p:103 16.5f)
`:/1/2019.01.03/t/
q)`:/2/2019.01.04/t/ set .Q.en[`:/db;] ([] ti:09:30:00 09:31:00; s:`ibm`t; p:102 17f)
`:/2/2019.01.04/t/2)然后是创建分段所需的par.txt文件,该文件需要包含分段时对应的分段目录(只需要层,如`:/1/2019.01.01/t/,这里只需要/1就可以,后面是对应的分区目录与扩展目录)
q)`:/db/par.txt 0: ("/1"; "/2")
`:/db/par.txt3)后就可以加载查询了,但是不建议\l /db这种加载形式,因为这样会加载所有数据,那就失去了分段,分区和扩展的意义了。这里只是测试,所以全部加载了。
q)\l /db
q)select from t where date within 2019.01.01 2019.01.02
date ti s p
-----------------------------
2019.01.01 09:30:00 ibm 101
2019.01.01 09:31:00 t 17
2019.01.02 09:30:00 ibm 101.5
2019.01.02 09:31:00 t 17.52. 按照股票名称分段
接下来介绍按照股票名称的首字母分段的方式,分为a~m和n~z。其伪代码逻辑结构如下:
/am
/2019.01.01
/t
/2019.01.02
/t
/nz
/2019.01.01
/t
/2019.01.02
/t相应的par.txt的文件内容如下:
/am
/nz创建方式如下:
1) 首先我们可以自定义个函数,该函数可以按照股票名称首字母来从相应的表中检索出对应的记录。这里(`$1#'string sym)表示从sym字段中提取每个symbol类型数据的首字母,由于一个symbol类型是一个整体,因此我们先要将symbol类型数据转换为字符串,然后提取字符串的个字符,再将该字符转换为symbol类型。
extr:{[t;r] select from t where (`$1#'string sym) within r}2) 然后是对表通过.Q.en进行分区,然后再序列化到分的段的对应目录下
t1:.Q.en[`:/db;] ([] ti:09:30:00 09:31:00; sym:`ibm`t; p:101 17f)
/这一步操作有两个目的,一是将表中的sym字段的symbol类型数据序列化到根目录db下;
二是将表赋值给t1,方便后面分段使用。
q)`:/am/2019.01.01/t/ set extr[t1;`a`m]
`:/am/2019.01.01/t/
q)`:/nz/2019.01.01/t/ set extr[t1;`n`z]
`:/nz/2019.01.01/t/
q)t2:.Q.en[`:/db;] ([] ti:09:30:00 09:31:00; sym:`ibm`t; p:101.5 17.5)
q)`:/am/2019.01.02/t/ set extr[t2;`a`m]
`:/am/2019.01.02/t/
q)`:/nz/2019.01.02/t/ set extr[t2;`n`z]
`:/nz/2019.01.02/t/3) 然后是创建分段所需的par.txt文件,该文件需要包含分段时对应的分段目录(只需要层,如`:/am/2019.01.01/t/,这里只需要/am就可以,后面是对应的分区目录与扩展目录)
q)`:/db/par.txt 0: ("/am";"/nz")
`:/db/par.txt4) 后就可以加载查询了,但是不建议\l /db这种加载形式,因为这样会加载所有数据,那就失去了分段,分区和扩展的意义了。这里只是测试,所以全部加载了。
q)\l /db
q)select from t where date within 2019.01.01 2019.01.02
date ti sym p
-----------------------------
2019.01.01 09:30:00 ibm 101
2019.01.01 09:31:00 t 17
2019.01.02 09:30:00 ibm 101.5
2019.01.02 09:31:00 t 17.53. 按交易所分段
下面介绍按照交易所分段的方式,分为SHSE(上海证券交易所)和SZSE(深证证券交易所)。其伪代码逻辑结构如下:
/SHSE <- 上海证券交易所
/2019.01.01
/t <- 上海证券交易所的日数据
/2019.01.02
/t <- 上海证券交易所的日数据
…
=============
/ SZSE <- 深证证券交易所
/2019.01.01
/t <- 深证交易所的日数据
/2019.01.02
/t <- 深证交易所的日数据创建步骤如下:
1) 首先也是自定义一个extr函数,该函数将每日数据按照交易所进行提取。
extr:{[t;e] select from t where ex=e}2) 然后是对表通过.Q.en进行分区,然后再序列化到分的段的对应目录下
q)t1:.Q.en[`:/db;] ([] ti:09:30:00 09:31:00; s:`ibm`aapl; p:101 17f;ex:`SHSE`SZSE)
q)`:/SHSE/2019.01.01/t/ set extr[t1;`SHSE]
`:/SHSE/2019.01.01/t/
q)`:/SZSE/2019.01.01/t/ set extr[t1;`SZSE]
`:/SZSE/2019.01.01/t/
q)t2:.Q.en[`:/db] ([] ti:09:30:00 09:31:00; s:`aapl`ibm;p:143 102f; ex:`SHSE`SZSE)
q)`:/SHSE/2019.01.02/t/ set extr[t2;`SHSE]
`:/SHSE/2019.01.02/t/
q)`:/SZSE/2019.01.02/t/ set extr[t2;`SZSE]
`:/SZSE/2019.01.02/t/3) 然后是创建分段所需的par.txt文件,该文件需要包含分段时对应的分段目录(只需要层,如`:/SHSE/2019.01.01/t/,这里只需要/SHSE就可以,后面是对应的分区目录与扩展目录)
q)`:/db/par.txt 0: ("/SHSE";"/SZSE")
`:/db/par.txt4) 后就可以加载查询了,但是不建议\l /db这种加载形式,因为这样会加载所有数据,那就失去了分段,分区和扩展的意义了。这里只是测试,所以全部加载了。
q)\l /db
q)select from t where date within 2019.01.01 2019.01.02
date ti s p ex
---------------------------------
2019.01.01 09:30:00 ibm 101 SHSE
2019.01.01 09:31:00 aapl 17 SZSE
2019.01.02 09:30:00 aapl 143 SHSE
2019.01.02 09:31:00 ibm 102 SZSE4. 自由分段
后就是介绍将每日数据按照非均匀的方式进行分段:
/seg A <- 段A
/2019.01.01
/t <-01.01这一整天的数据
/2019.01.02
/t <- 01.02这一天上午的数据
=============
/seg B <- 段B
/2019.01.02
/t <- 01.02这一天下午的数据
/2019.01.03
/t <- 01.03这一整天的数据
=============
/seg C <- 段C
/2019.01.04
/t <- 01.04这一天的数据对应的par.txt文件内容如下:
/seg A
/seg B
/seg C创建方式如下:
1)首先是对表通过.Q.en进行分区,然后再序列化到分的段的对应目录下
q)t1:.Q.en[`:/db;] ([] ti:09:30:00 12:31:00; s:`ibm`t; p:101 17f)
q)`:/A/2019.01.01/t/ set t1
`:/A/2019.01.01/t/
q)t2:.Q.en[`:/db;] ([] ti:09:31:00 12:32:00; s:`ibm`t; p:102 18f)
q)`:/A/2019.01.02/t/ set select from t2 where ti<=12:00:00
`:/A/2019.01.02/t/
q)`:/B/2019.01.02/t/ set select from t2 where ti>12:00:00
`:/B/2019.01.02/t/
q)t3:.Q.en[`:/db;] ([] ti:09:33:00 12:33:00; s:`ibm`t; p:103 19f)
q)`:/B/2019.01.03/t/ set t3
`:/B/2019.01.03/t/
q)t4:.Q.en[`:/db;] ([] ti:09:34:00 12:35:00; s:`ibm`t; p:104 20f)
q)`:/C/2019.01.04/t/ set t4
`:/C/2019.01.04/t/2)然后是创建分段所需的par.txt文件,该文件需要包含分段时对应的分段目录(只需要层,如`:/A/2019.01.01/t/,这里只需要/A就可以,后面是对应的分区目录与扩展目录)
q)`:/db/par.txt 0: ("/A";"/B";"/C")
`:/db/par.txt3)后就可以加载查询了,但是不建议\l /db这种加载形式,因为这样会加载所有数据,那就失去了分段,分区和扩展的意义了。这里只是测试,所以全部加载了。
q)\l /db
q)select from t where date within 2019.01.01 2019.01.04
date ti s p
---------------------------
2019.01.01 09:30:00 ibm 101
2019.01.01 12:31:00 t 17
2019.01.02 09:31:00 ibm 102
2019.01.02 12:32:00 t 18
2019.01.03 09:33:00 ibm 103
2019.01.03 12:33:00 t 19
2019.01.04 09:34:00 ibm 104
2019.01.04 12:35:00 t 20四. 多个表的分段表
前面我们都是将一个表放在不同的段结构下,那我们其实在整个分段结构下放置多个表来共享这个分段结构。虽然没有要求在每个段中的表的结构分布是相似的,但是如果后面涉及使用链接等则应该在每个段结构中表使用相似的分布。接下来将演示将报价表和交易表来放在一个分段结构中,这样可以使用非等值连接(aj)查询。
下面是多个分段表的一个伪结构:
/a_m <- 段1
/2015.01.01 <- 分区1
/t <- 交易表中股票名称首字母为a~m之间的数据
/q <- 报价表中股票名称首字母为a~m之间的数据
/2015.01.02 <- 分区2
/t <- 交易表中股票名称首字母为a~m之间的数据
/q <- 报价表中股票名称首字母为a~m之间的数据
=================
/n_z <- 段2
/2015.01.01 <- 分区1
/t <- 交易表中股票名称首字母为n~z之间的数据
/q <- 报价表中股票名称首字母为n~z之间的数据
/2015.01.02 <- 分区2
/t <- 交易表中股票名称首字母为n~z之间的数据
/q <- 报价表中股票名称首字母为n~z之间的数据 相应的par.txt文件内容为:
/a_m
/n_z 下面就是具体来创建多个表共享一个分段结构的实践(具体步骤与前面单个表创建分段是一样的,就不赘述了):
q)extr:{[t;r] select from t where (`$1#'string sym) within r}
q)t:.Q.en[`:/db;] ([] ti:09:30:00 09:31:00; sym:`ibm`t; p:101 17f)
q)q:.Q.en[`:/db;] ([] ti:09:29:59 09:29:59 09:30:00; sym:`ibm`t`ibm; p:100.5 17 101)
q)`:/am/2019.01.01/t/ set extr[t;`a`m]
`:/am/2019.01.01/t/
q)`:/nz/2019.01.01/t/ set extr[t;`n`z]
`:/nz/2019.01.01/t/
q)`:/am/2019.01.01/q/ set extr[q;`a`m]
`:/am/2019.01.01/q/
q)`:/nz/2019.01.01/q/ set extr[q;`n`z]
`:/nz/2019.01.01/q/
q)t:.Q.en[`:/db;] ([] ti:09:30:00 09:31:00; sym:`t`ibm; p:17.1 100.9)
q)q:.Q.en[`:/db;] ([] ti:09:29:59 09:29:59 09:30:00; sym:`t`ibm`t;p:17 100.8 17.1)
q)`:/am/2019.01.02/t/ set extr[t;`a`m]
`:/am/2019.01.02/t/
q)`:/nz/2019.01.02/t/ set extr[t;`n`z]
`:/nz/2019.01.02/t/
q)`:/am/2019.01.02/q/ set extr[q;`a`m]
`:/am/2019.01.02/q/
q)`:/nz/2019.01.02/q/ set extr[q;`n`z]
`:/nz/2019.01.02/q/
q)`:/db/par.txt 0: ("/am"; "/nz")
`:/db/par.txt
q)\l /db
q)dr:2019.01.01 2019.01.02
q)select from t where date within dr
date ti sym p
-----------------------------
2019.01.01 09:30:00 ibm 101
2019.01.01 09:31:00 t 17
2019.01.02 09:31:00 ibm 100.9
2019.01.02 09:30:00 t 17.1
q)select from q where date within dr
date ti sym p
-----------------------------
2019.01.01 09:29:59 ibm 100.5
2019.01.01 09:30:00 ibm 101
2019.01.01 09:29:59 t 17
2019.01.02 09:29:59 ibm 100.8
2019.01.02 09:29:59 t 17
2019.01.02 09:30:00 t 17.1下面就是我们使用非等值连接aj来进行查询:
q)aj[`date`sym`ti; select from t where date within dr; select from q where date within dr]
date ti sym p
-----------------------------
2019.01.01 09:30:00 ibm 101
2019.01.01 09:31:00 t 17
2019.01.02 09:31:00 ibm 100.8
2019.01.02 09:30:00 t 17.1
/这里第三条数据为什么更新为108.1可以去查询aj连接的查询机制上面这种查询方式没有什么问题,但是并没有体现出我们的分段表在性能上的一个提升,我们可以使用salve的形式来进行查询,从而提高运行效率。具体方式如下:
首先我们重新打开一个会话,比打开两个slave。
C:\Users\caoxi>q -s 2
KDB+ 3.6 2018.12.06 Copyright (C) 1993-2018 Kx Systems然后开始使用peach来进行查询,peach就可以调度我们两个slave来进行并行查询和并发处理。
q)aj1:{[d] aj[`sym`ti;select from t where date=d; select from q where date=d]}
q)raze aj1 peach 2019.01.01 2019.01.02
date ti sym p
-----------------------------
2019.01.01 09:30:00 ibm 101
2019.01.01 09:31:00 t 17
2019.01.02 09:31:00 ibm 100.8
2019.01.02 09:30:00 t 17.1五. 分段表的创建策略与优化策略
kdb+的性能提升是通过利用并行I/O查询和并发处理来进行延展。在理想情况下,希望能够实现I/O利用和的每个处理器内核的使用。在server端如何来实现这些条件呢?kdb+的设计和调优的关键是:由于内存中的计算比从存储的磁盘中检索数据要快的多,那么我们就要提高检索的速度。这表明可以遵循如下两个原则:
1)大化独立I/O通道的数量,以并行检索数据;
2)大化服务器内存,以便为每个从属线程分配所需的内存。
假设可以通过n个独立的I/O通道将存储设备连接到server来满足这两个目标,在这种情况下,则可以进一步进行优化。优化思路如下:
3)创建n个分段以分布在n个通道上来数据检索,以便大I/O并行化处理。
为确保可以同时能够处理从n个通道返回的数据,并且没有两个线程争用数据,则可以从以下方式进行优化:
4)创建n个salve线程。
上述所有n的具体是多少根据我们实际的表的结构情况与查询的情况。
上述的环境满足以后,kdb +就可以在n段和n个slave的场景中对分段表执行查询。从本质上讲,它通过map-reduce将符合条件的查询分解为两个步骤:
map:将原始的查询通过处理,映射到每个段上查询;
reduce:将每个段查询返回的结果进行聚合操作。
首先,kdb +将查询所必需分区与par.txt文件中的段布局进行比较,然后确定所需要的分区在哪个段上。返回的结果是一个嵌套列表,嵌套列表中的每个元素包含了一个段中查询的信息。
为了执行映射步骤,kdb +创建一个修改后的查询,其中包含原始查询中的map子操作,并通过peach将该查询将其分派给n个salve。会为每个slave提供一个段的分区列表,并计算其段的修订查询结果。例如,一般会将avg修订为——计算该slave下的sum值与涉及的总数。
有了这些了解后,那我们研究一下一个slave如何执行的修订后的应用到段上的查询。这里kdb +是在目标分区上顺序地应用原始查询的映射子操作,以获得分区结果表,然后将其收集到表示一个段结果的列表中。
原始查询的映射到n个slave并行检索段数据并计算段结果。一旦所有slave都完成,后得到一个嵌套的结果,通过对嵌套的结果根据每个分区的值进行排序。
后,kdb +使用原始查询reduce步骤将有序分区结果的完整列表组合到查询结果表中,然后返回终结果。
六. 如何平衡I/O与CPU
为了实现100%的I/O和CPU饱和度,考虑如何优化slave和内核的使用。如上一节所示,通过map-reduce的查询为我们初的I/O饱和目标提供了良好的思路。slave设备可以并行加载来自所有n个通道的数据而不会发生争用。
我们现在调查通道和核心利用率。由于kdb +将只使用尽可能多的slave来处理查询,我们考虑两种情况:
1)I/O绑定:假设查询中计算量小于检索量,则n个核上对应n 个slave佳,大多数情况下,所有n个slave设备都将等待数据检索。当分区加载完成时,将会有一个短暂的计算突发,然后是另一个长负载。所以我们总结一下这个场景:
n个通道=> n个段 => n个从站=> n个核心
2)平衡I/O计算:考虑I/O通道使用和计算都很密集的情况。当一个slave正在等待数据时,同一CPU核上的另一个slave可能正在处理; 相反,当一个salve正在处理该核上的另一个slave可能正在加载数据。因此,为了大化通道和CPU核利用率,我们实际上需要n核上的2n个slave。在这种情况下,我们应该有2n个分段,每个通道两个段。平均而言,每个核有一个slave加载数据,有一个slave处理刚刚加载的数据。
n个通道=> 2n个段 => 2n个从站=> n个核心
这些结论只是一个假设。在实践中,可以将它们视为指南,目标是尽可能快地将数据提供给kdb+。后根据数据情况与查询情况来搭建自己佳的配置。例如,执行VWAP计算的查询更接近个场景,而执行回归分析的查询更接近第二个场景。
一个好的策略是使用上述场景之一构建初始配置。然后加载预期的数据和查询组合的良好近似值,并模拟真实的用户负载。观察I/O饱和度和CPU利用率,并相应地调整分配给q进程的slave和CPU核数。
七. 分段表查询机制
(这一段比较复杂,等我研究明白底层处理再补上)
来源 https://zhuanlan.zhihu.com/p/71662979
