4.简介:qa_match是58同城推出的一款基于深度学习的轻量级问答匹配工具,V1.0版本于2020年3月9日发布,可参见《qa_match|一款基于深度学习的层级问答匹配工具》,近我们对qa_match进行了升级,新增如下Features:
使用轻量级预训练语言模型(SPTM,Simple Pre-trained Model)来进行问答匹配。 支持基于一层结构知识库的问答(V1.0版本仅支持基于两层结构知识库的问答),提高通用性。
为什么要升级到V1.1 问答知识库介绍 轻量级预训练语言模型(SPTM) 问答匹配 未来规划 如何贡献&问题反馈 作者简介
为什么要升级到V1.1
问答知识库介绍
在实际场景中,知识库一般是通过人工总结、标注、机器挖掘等方式进行构建,知识库中包含大量的标准问题,每个标准问题有一个标准答案和一些扩展问法,我们称这些扩展问法为扩展问题。对于一层结构知识库,仅包含标准问题和扩展问题,我们把标准问题称为意图。对于两层结构知识库,每个标准问题及其扩展问题都有一个类别,我们称为领域,一个领域包含多个意图。两种知识库结构的对比如下图所示:

轻量级预训练语言模型(SPTM)
考虑到实际使用中往往存在大量的无标签数据,在知识库数据有限时,可使用无监督预训练语言模型提升匹配模型的效果。参考BERT预训练过程,2019年4月我们开发了SPTM模型,该模型相对于BERT主要改进了两方面:一是去掉了效果不明显的NSP(Next Sentence Prediction),二是为了提高线上推理性能将Transformer替换成了LSTM,模型原理如下:
1、数据预处理
预训练模型时,生成训练数据需要使用无标签单句作为数据集,并参考了BERT来构建样本:每个单句作为一个样本,句子中15%的字参与预测,参与预测的字中80%进行mask,10%随机替换成词典中一个其他的字,10%不替换。
2、预训练
预训练阶段的模型结构如下图所示:
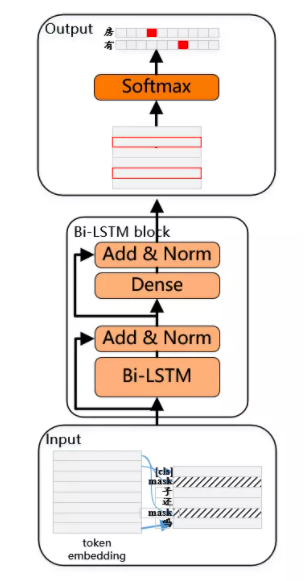
为提升模型的表达能力,保留更多的浅层信息,引入了残差Bi-LSTM网络(Residual LSTM)作为模型主体。该网络将每一层Bi-LSTM的输入和该层输出求和归一化后,结果作为下一层的输入。此外将末层Bi-LSTM输出作为一个全连接层的输入,与全连接层输出求和归一化后,结果作为整个网络的输出。
预训练模型耗时示例如下表所示:
| 指标名称 | 指标值 |
| 预训练数据集大小 | 10Million |
| 预训练资源 | Nvidia P40 / 12G Memory |
| 预训练参数 | step = 500000 / batch size=256 |
| 预训练耗时 | 215.69hour |
问答匹配
1、基于两层结构知识库的自动问答
V1.0版本详细介绍了如何融合LSTM领域分类模型和DSSM意图匹配模型来完成基于两层结构知识库的自动问答,这里不再描述,详细可参见《开源|qa_match:一款基于深度学习的层级问答匹配工具》。
2、基于一层结构知识库的自动问答
对于一层结构知识库,可以使用DSSM和预训练语言模型来完成自动问答。
2.1 基于DSSM模型的自动问答
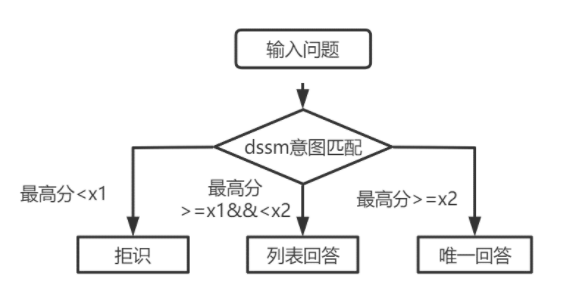
对于一层结构知识库问答,只需用使用V1.0版本中的DSSM意图匹配模型对输入问题进行打分,根据意图匹配的高分值与下图中的x1,x2进行比较决定回答类型(回答、列表回答、拒识)。DSSM原理见之前的文章《开源|qa_match:一款基于深度学习的层级问答匹配工具》。
2.2 基于SPTM模型的自动问答
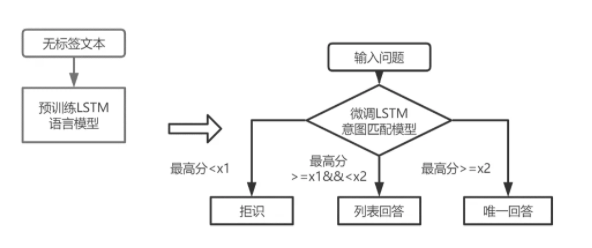
得到微调模型后,需要用模型对输入问题进行打分,再根据与DSSM意图匹配模型相同的策略确定回答类型(回答、列表回答、拒识),整体流程如下图所示:
为了让使用者快速上手qa_match,我们给出了一级知识库、二级知识库的示例数据集(具体见 data_demo),训练了不同模型(模型结果文件见DSSM/SPTM/ LSTM+DSSM融合模型),并评测了不同模型的离线效果和线上推理性能(使用通用深度学习推理服务dl_inference开源项目部署模型来评测推理耗时)
| 数据集 | 模型 | 回答准确率 | 回答召回率 | 回答F1 | CPU机器上推理耗时 |
| 一级知识库数据集 | DSSM | 0.8398 | 0.8326 | 0.8362 | 3ms |
| SPTM | 0.8841 | 0.9002 | 0.8921 | 16ms | |
| 二级知识库数据集 | LSTM+DSSM融合模型 | 0.8957 | 0.9027 | 0.8992 | 18ms |
未来规划
未来我们会继续优化扩展qa_match的能力,计划开源如下:
1、知识库半自动挖掘流程。基于知识库的构建,我们开发了一套结合人工和机器挖掘的算法流程,已经在生产环境使用,并取得了不错的效果。
2、目前tensorflow已发版到2.1版本,后续我们会根据需求发布tensorflow 2.X版本或pytorch版本的qa_match。
如何贡献&问题反馈
本次更新达成了qa_match持续迭代历程中的步,我们诚挚地希望开发者继续向我们提出宝贵的意见。
您可以挑选以下方式向我们反馈建议和问题:
1、在https://github.com/wuba/qa_match.git提交 PR 或者 Issue
2、邮件发送至ailab-opensource@58.com
王勇,58同城 AI Lab 算法架构师,主要负责58智能问答相关算法研发工作。
陈璐,58同城 AI Lab 算法工程师,主要负责58智能质检相关算法研发工作。

