
起源
在进行架构转型与分库分表之前,我们一直采用非常典型的单体应用架构:主服务是一个 Java WebApp,使用 Nginx 并选择 Session Sticky 分发策略做负载均衡和会话保持;背后是一个 MySQL 主实例,接了若干 Slave 做读写分离。在整个转型开始之前,我们就知道这会是一块难啃的硬骨头:我们要在全线业务飞速地扩张迭代的同时完成架构转型,因为这是实实在在的”给高速行驶的汽车换轮胎”。
为了大限度地减少服务拆分与分库分表给业务带来的影响(不影响业务开发也是架构转型的前提),我们采用了一种温和的渐进式拆分方案:
对于每块需要拆分的领域,首先拆分出子服务,并将所有该领域的数据库操作封装为 RPC 接口; 将其它所有服务中对该领域数据表的操作替换为 RPC 调用; 拆分该领域的数据表,使用数据同步保证旧库中的表与新表数据一致; 将该子服务中的数据库操作逐步迁移到新表,分批上线; 全部迁移完成后,切断同步,该服务拆分结束。
这种方案能够做到平滑迁移,但其中却有几个棘手的问题:
旧表新表的数据一致性如何保证? 如何支持异构迁移?(由于旧表的设计往往非常范式化,因此拆分后的新表会增加很多来自其它表的冗余列) 如何保证数据同步的实时性?(往往会先迁移读操作到新表,这时就要求旧表的写操作必须准实时地同步到新表)
典型的解决方案有两种:
双写(dual write): 即所有写入操作同时写入旧表和新表,这种方式可以完全控制应用代码如何写数据库,听上去简单明了。但它会引入复杂的分布式一致性问题:要保证新旧库中两张表数据一致,双写操作就必须在一个分布式事务中完成,而分布式事务的代价太高了。
数据变更抓取(change data capture, CDC): 通过数据源的事务日志抓取数据源变更,这能解决一致性问题(只要下游能保证变更应用到新库上)。它的问题在于各种数据源的变更抓取没有统一的协议,如 MySQL 用 Binlog,PostgreSQL 用 Logical decoding 机制,MongoDB 里则是 oplog。
终我们选择使用数据变更抓取实现数据同步与迁移,一是因为数据一致性的优先级更高,二是因为开源社区的多种组件能够帮助我们解决没有统一协议带来的 CDC 模块开发困难的问题。在明确要解决的问题和解决方向后,我们就可以着手设计整套架构了。
架构设计
只有一个 CDC 模块当然是不够的,因为下游的消费者不可能随时就位等待 CDC 模块的推送。因此我们还需要引入一个变更分发平台,它的作用是:
提供变更数据的堆积能力; 支持多个下游消费者按不同速度消费; 解耦 CDC 模块与消费者;
另外,我们还需要确定一套统一的数据格式,让整个架构中的所有组件能够高效而安全地通信。
现在我们可以正式介绍 Vimur [ˈviːmər] 了,它是一套实时数据管道,设计目标是通过 CDC 模块抓取业务数据源变更,并以统一的格式发布到变更分发平台,所有消费者通过客户端库接入变更分发平台获取实时数据变更。
我们先看一看这套模型要如何才解决上面的三个问题:
一致性:数据变更分发给下游应用后,下游应用可以不断重试保证变更成功应用到目标数据源——这个过程要真正实现一致性还要满足两个前提,一是从数据变更抓取模块投递到下游应用并消费这个过程不能丢数据,也就是要保证至少一次交付;二是下游应用的消费必须是幂等的。 异构迁移:异构包含多种含义:表的 Schema 不同、表的物理结构不同(单表到分片表)、数据库不同(如 MySQL -> EleasticSearch) ,后两者只要下游消费端实现对应的写入接口就能解决;而 Schema 不同,尤其是当新库的表聚合了多张旧库的表信息时,就要用反查源数据库或 Stream Join 等手段实现。 实时性:只要保证各模块的数据传输与写入的效率,该模型便能保证实时性。
可以看到,这套模型本身对各个组件是有一些要求的,我们下面的设计选型也会参照这些要求。
开源方案对比
在设计阶段,我们调研对比了多个开源解决方案:
databus: Linkedin 的分布式数据变更抓取系统; Yelp’s data pipeline: Yelp 的数据管道; Otter: 阿里开源的分布式数据库同步系统; Debezium: Redhat 开源的数据变更抓取组件;
这些解决方案关注的重点各有不同,但基本思想是一致的:使用变更抓取模块实时订阅数据库变更,并分发到一个中间存储供下游应用消费。下面是四个解决方案的对比矩阵:

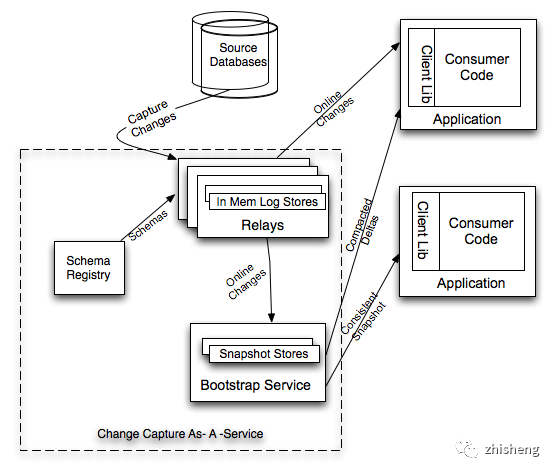
Linkedin databus 的论文有很强的指导性,但它的 MySQL 变更抓取模块很不成熟,官方支持的是 Oracle,MySQL 只是使用另一个开源组件 OpenReplicator 做了一个 demo。另一个不利因素 databus 使用了自己实现的一个 Relay 作为变更分发平台,相比于使用开源消息队列的方案,这对维护和外部集成都不友好。
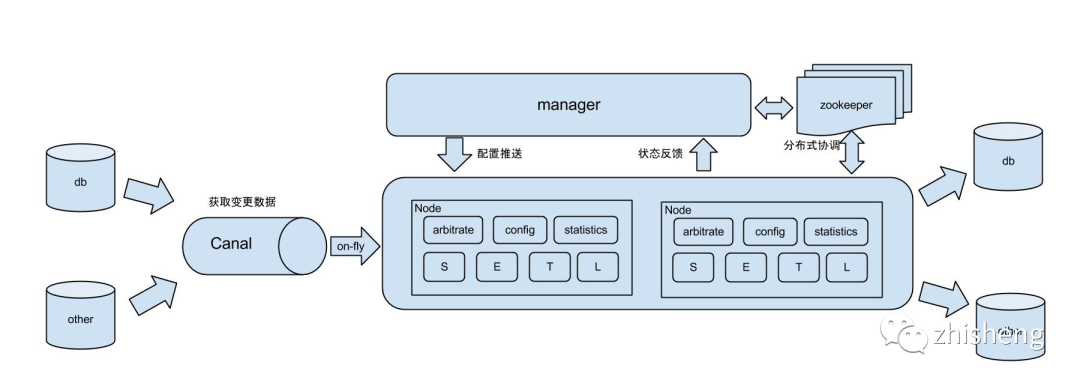
Otter 和 Canal 在国内相当知名,Canal 还支持了阿里云 DRDS 的二级索引构建和小表同步,工程稳定性上有保障。但 Otter 本身无法很好地支持多表聚合到新表,开源版本也不支持同步到分片表当中,能够采取的一个折衷方案是直接将 Canal 订阅的变更写入消息队列,自己写下游程序实现聚合同步等逻辑。该方案也是我们的候选方案。
Yelp’s data pipeline 是一个大而全的解决方案。它使用 Mysql-Streamer(一个通过 binlog 实现的 MySQL CDC 模块)将所有的数据库变更写入 Kafka,并提供了 Schematizer 这样的 Schema 注册中心和定制化的 Python 客户端库解决通信问题。遗憾的是该方案是 Python 构建的,与我们的 Java 技术栈相性不佳。
后是 Debezium , 不同于上面的解决方案,它只专注于 CDC,它的亮点有:
支持 MySQL、MongoDB、PostgreSQL 三种数据源的变更抓取,并且社区正在开发 Oracle 与 Cassandra 支持; Snapshot Mode 可以将表中的现有数据全部导入 Kafka,并且全量数据与增量数据形式一致,可以统一处理; 利用了 Kafka 的 Log Compaction 特性,变更数据可以实现”不过期”保存; 利用了 Kafka Connect,自动拥有高可用与开箱即用的调度接口; 社区活跃:Debezium 很年轻,面世不到1年,但它的 Gitter上每天都有百余条技术讨论,并且有两位 Redhat 全职工程师进行维护;
终我们选择了 Debezium + Kafka 作为整套架构的基础组件,并以 Apache Avro 作为统一数据格式,下面我们将结合各个模块的目标与设计阐释选型动机。
CDC 模块
变更数据抓取通常需要针对不同数据源订制实现,而针对特定数据源,实现方式一般有两种:
基于自增列或上次修改时间做增量查询; 利用数据源本身的事务日志或 Slave 同步等机制实时订阅变更;
种方式实现简单,以 SQL 为例:相信大家都写过类似的 SQL, 每次查询时,查询 [last_query_time, now) 区间内的增量数据,lastmodified 列也可以用自增主键来替代。这种方式的缺点是实时性差,对数据库带来了额外压力,并且侵入了表设计 —— 所有要实现变更抓取的表都必须有用于增量查询的列并且在该列上构建索引。另外,这种方式无法感知物理删除(Delete), 删除逻辑只能用一个 delete 列作为 flag 来实现。
第二种方式实现起来相对困难,但它很好地解决了种方式的问题,因此前文提到的开源方案也都采用了这种方式。下面我们着重分析在 MySQL 中如何实现基于事务日志的实时变更抓取。
MySQL 的事务日志称为 binlog,常见的 MySQL 主从同步就是使用 Binlog 实现的:

我们把 Slave 替换成 CDC 模块,CDC 模块模拟 MySQL Slave 的交互协议,便能收到 Master 的 binlog 推送:

CDC 模块解析 binlog,产生特定格式的变更消息,也就完成了一次变更抓取。但这还不够,CDC 模块本身也可能挂掉,那么恢复之后如何保证不丢数据又是一个问题。这个问题的解决方案也是要针对不同数据源进行设计的,就 MySQL 而言,通常会持久化已经消费的 binlog 位点或 Gtid(MySQL 5.6之后引入)来标记上次消费位置。其中更好的选择是 Gtid,因为该位点对于一套 MySQL 体系(主从或多主)是全局的,而 binlog 位点是单机的,无法支持主备或多主架构。
那为什么后选择了 Debezium 呢?
MySQL CDC 模块的一个挑战是如何在 binlog 变更事件中加入表的 Schema 信息(如标记哪些字段为主键,哪些字段可为 null)。Debezium 在这点上处理得很漂亮,它在内存中维护了数据库每张表的 Schema,并且全部写入一个 backup 的 Kafka Topic 中,每当 binlog 中出现 DDL 语句,便应用这条 DDL 来更新 Schema。而在节点宕机,Debezium 实例被调度到另一个节点上后,又会通过 backup topic 恢复 Schema 信息,并从上次消费位点继续解析 Binlog。
在我们的场景下,另一个挑战是,我们数据库已经有大量的现存数据,数据迁移时的现存数据要如何处理。这时,Debezium 独特的 Snapshot 功能就能帮上忙,它可以实现将现有数据作为一次”插入变更”捕捉到 Kafka 中,因此只要编写一次客户端就能一并处理全量数据与后续的增量数据。
变更分发平台
变更分发平台可以有很多种形式,本质上它只是一个存储变更的中间件,那么如何进行选型呢?首先由于变更数据数据量级大,且操作时没有事务需求,所以先排除了关系型数据库, 剩下的 NoSQL 如 Cassandra,mq 如 Kafka、RabbitMQ 都可以胜任。其区别在于,消费端到分发平台拉取变更时,假如是 NoSQL 的实现,那么就能很容易地实现条件过滤等操作(比如某个客户端只对特定字段为 true 的消息感兴趣); 但 NoSQL 的实现往往会在吞吐量和一致性上输给 mq。这里就是一个设计抉择的问题,终我们选择了 mq,主要考虑的点是:消费端往往是无状态应用,很容易进行水平扩展,因此假如有条件过滤这样的需求,我们更希望把这样的计算压力放在消费端上。
而在 mq 里,Kafka 则显得具有压倒性优势。Kafka 本身就有大数据的基因,通常被认为是目前吞吐量大的消息队列,同时,使用 Kafka 有一项很适合该场景的特性:Log Compaction。Kafka 默认的过期清理策略(log.cleanup.policy)是delete,也就是删除过期消息,配置为compact则可以启用 Log Compaction 特性,这时 Kafka 不再删除过期消息,而是对所有过期消息进行”折叠” —— 对于 key 相同的所有消息会,保留新的一条。
举个例子,我们对一张表执行下面这样的操作:对应的在 mq 中的流总共会产生 4 条变更消息,而下面两条分别是 id:1 id:2 下的新记录,在它们之前的两条 INSERT 引起的变更就会被 Kafka 删除,终我们在 Kafka 中看到的就是两行记录的新状态,而一个持续订阅该流的消费者则能收到全部4条记录。
这种行为有一个有趣的名字,流表二相性(Stream Table Durability):Topic 中有无尽的变更消息不断被写入,这是流的特质;而 Topic 某一时刻的状态,恰恰是该时刻对应的数据表的一个快照(参见上面的例子),每条新消息的到来相当于一次 Upsert,这又是表的特性。落到实践中来讲,Log Compaction 对于我们的场景有一个重要应用:全量数据迁移与数据补偿,我们可以直接编写针对每条变更数据的处理程序,就能兼顾全量迁移与之后的增量同步两个过程;而在数据异常时,我们可以重新回放整个 Kafka Topic —— 该 Topic 就是对应表的快照,针对上面的例子,我们回放时只会读到新的两条消息,不需要读全部四条消息也能保证数据正确。
关于 Kafka 作为变更分发平台,后要说的就是消费顺序的问题。大家都知道 Kafka 只能保证单个 Partition 内消息有序,而对于整个 Topic,消息是无序的。一般的认知是,数据变更的消费为了逻辑的正确性,必须按序消费。按着这个逻辑,我们的 Topic 只能有单个 Partition,这就大大牺牲了 Kafka 的扩展性与吞吐量。其实这里有一个误区,对于数据库变更抓取,我们只要保证 同一行记录的变更有序 就足够了。还是上面的例子,我们只需要保证对id:2 这行的 insert 消息先于 update 消息,该行数据后就是正确的。而实现”同一行记录变更有序”就简单多了,Kafka Producer 对带 key 的消息默认使用 key 的 hash 决定分片,因此只要用数据行的主键作为消息的 key,所有该行的变更都会落到同一个 Parition 上,自然也就有序了。这有一个要求就是 CDC 模块必须解析出变更数据的主键 —— 而这点 Debezium 已经帮助我们解决了。
统一数据格式
数据格式的选择同样十分重要。首先想到的当然是 json, 目前常见的消息格式,不仅易读,开发也都对它十分熟悉。但 json 本身有一个很大的不足,那就是契约性太弱,它的结构可以随意更改:试想假如有一个接口返回 String,注释上说这是个json,那我们该怎么编写对应的调用代码呢?是不是需要翻接口文档,提前获知这段 json 的 schema,然后才能开始编写代码,并且这段代码随时可能会因为这段 json 的格式改变而 break。
在规模不大的系统中,这个问题并不显著。但假如在一个拥有上千种数据格式的数据管道上工作,这个问题就会很麻烦,首先当你订阅一个变更 topic 时,你完全处于懵逼状态——不知道这个 topic 会给你什么,当你经过文档的洗礼与不断地调试终于写完了客户端代码,它又随时会因为 topic 中的消息格式变更而挂掉。
参考 Yelp 和 Linkedin 的选择,我们决定使用 Apache Avro 作为统一的数据格式。Avro 依赖模式 Schema 来实现数据结构定义,而 Schema 通常使用 json 格式进行定义,一个典型的 Schema 如下:这里要介绍一点背景知识,Avro 的一个重要特性就是支持 Schema 演化,它定义了一系列的演化规则,只要符合该规则,使用不同的 Schema 也能够正常通信。也就是说,使用 Avro 作为数据格式进行通信的双方是有自由更迭 Schema 的空间的。
在我们的场景中,数据库表的 Schema 变更会引起对应的变更数据 Schema 变更,而每次进行数据库表 Schema 变更就更新下游消费端显然是不可能的。所以这时候 Avro 的 Schema 演化机制就很重要了。我们做出约定,同一个 Topic 上传输的消息,其 Avro Schema 的变化必须符合演化规则,这么一来,消费者一旦开始正常消费之后就不会因为消息的 Schema 变化而挂掉。
应用总结
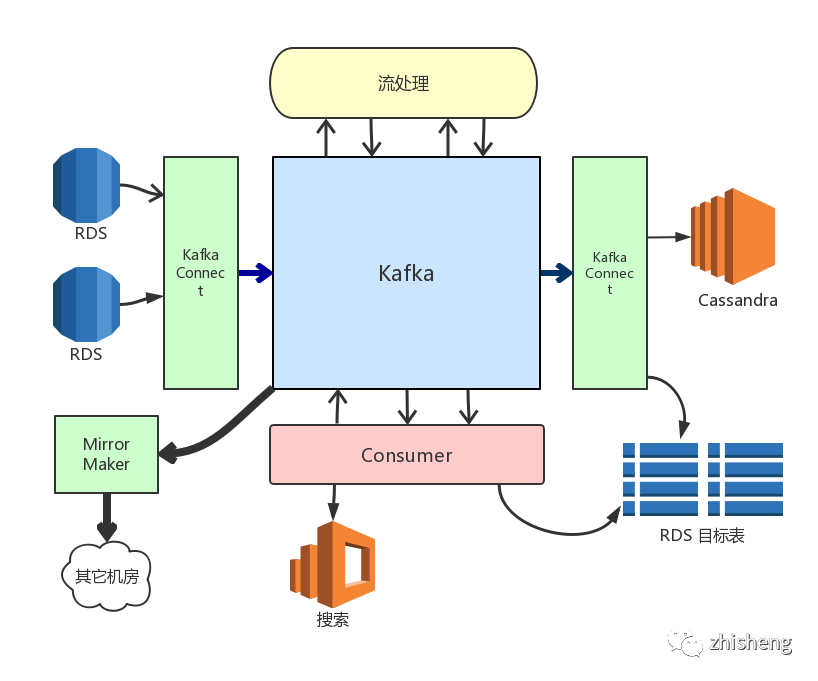
上图展现了以变更分发平台(Kafka) 为中心的系统拓扑。其中有一些上面没有涉及的点:我们使用 Kafka 的 MirrorMaker 解决了跨数据中心问题,使用 Kafka Connect 集群运行 Debezium 任务实现了高可用与调度能力。
我们再看看 Vimur 是如何解决数据迁移与同步问题的,下图展示了一次典型的数据同步过程:
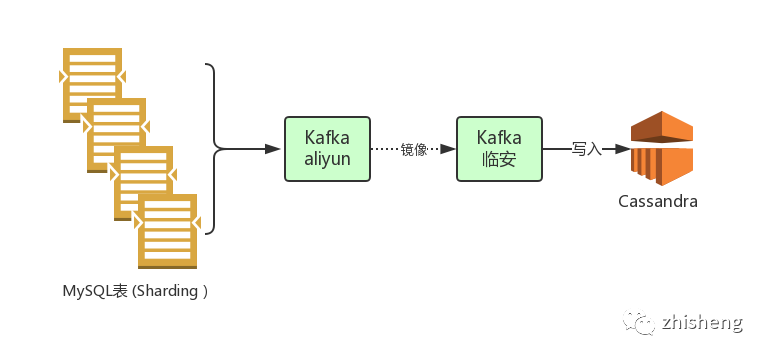
下图是一次典型的数据迁移过程,数据迁移通常伴随着服务拆分与分库分表:
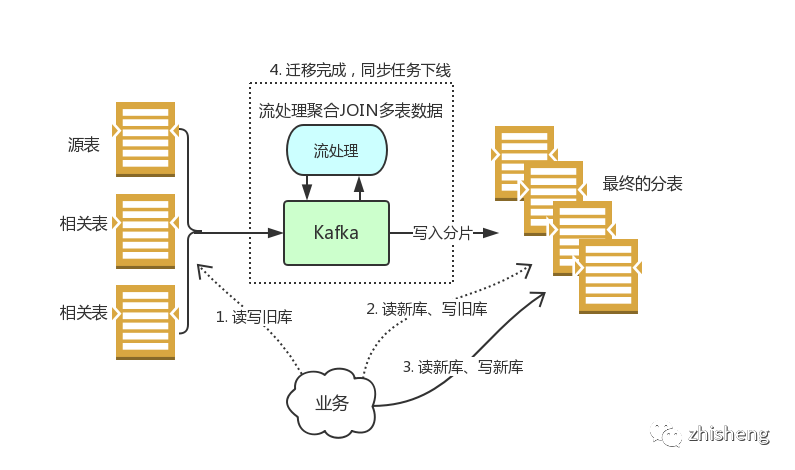
这里其实同步任务的编写是颇有讲究的,因为我们一般需要冗余很多新的列到新表上,所以单个流中的数据是不够的,这时有两种方案:
反查数据库:逻辑简单,只要查询所需要的冗余列即可,但所有相关的列变动都要执行一次反查会对源库造成额外压力;Stream Join:Stream Join 通常需要额外存储的支持,无论用什么框架实现,终效果是把反查压力放到了框架依赖的额外存储上;这两种方案见仁见智,Stream Join 逻辑虽然更复杂,但框架本身如 Flink、Kafka Stream 都提供了 DSL 简化编写。终的选型实际上取决于需不需要把反查的压力分散出去。
Vimur 的另一个深度应用是解决跨库查询,分库分表后数据表 JOIN 操作将很难实现,通常我们都会查询多个数据库,然后在代码中进行 JOIN。这种办法虽然麻烦,但却不是不采取的妥协策略(框架来做跨库 JOIN ,可行但有害,因为有很多性能陷阱必须手动编码去避免)。然而有些场景这种办法也很难解决,比如多表 INNER JOIN 后的分页。这时我们采取的解决方案就是利用 Vimur 的变更数据,将需要 JOIN 的表聚合到搜索引擎或 NoSQL 中,以文档的形式提供查询。
除了上面的应用外,Vimur 还被我们应用于搜索索引的实时构建、业务事件通知等场景,并计划服务于缓存刷新、响应式架构等场景。回顾当初的探索历程,很多选择可能不是好的,但一定是反复实践后我们认为适合我们的。假如你也面临复杂数据层中的数据同步、数据迁移、缓存刷新、二级索引构建等问题,不妨尝试一下基于 CDC 的实时数据管道方案。
本文转自:https://aleiwu.com/post/vimur.cn/
作者:Aylei
