
背 景
58同城APP是一个生活服务信息平台,用户可以在平台上寻找自己所需要的服务,商家可以在平台上展示自己可提供的服务。58本地服务主要为用户提供生活中的基础服务信息,58本地服务推荐场景主要包括大类页推荐、猜你喜欢和猜你想找等,本文主要介绍猜你想找的技术迭代。58本地服务大部分的流量来自于搜索入口,但是在搜索落地页会有空白需要补充情况,如图1所示,为了提高这部分流量的转化,我们在用户搜索少无结果的情况下增加了猜你想找模块,旨在解决用户搜索少无结果的推荐问题,提升用户体验,降低少无结果率,并且达到提升58本地服务用户转化的目的。

图1 猜你想找示意图
整体框架

召回层
召回层作为漏斗从海量帖子中滤出用户可能感兴趣的帖子交给后续排序技术处理,它直接决定着后续推荐结果的效果上限。在猜你想找场景中需要扩大召回,尽可能多的召回相关帖子,为后续的排序提供充足的候选集。因此采用多路召回模式,如图3所示,用户意图召回主要是为了提高召回集的类目多样性,向量召回和标签召回主要是召回与用户搜索语义相关的帖子,另外防止其他召回策略均没有结果,我们还添加了热门帖的召回作为补充策略。下面分别介绍每一路召回策略。
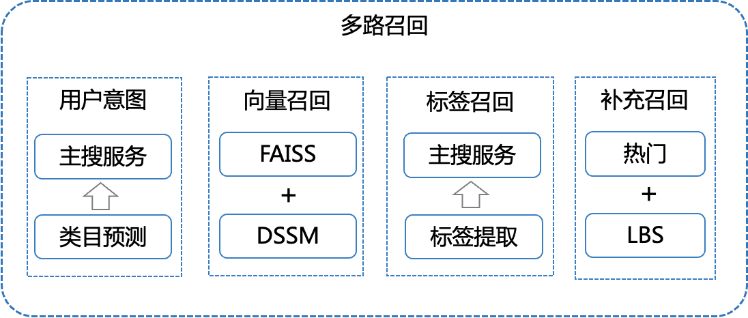
图3 多路召回
一、基于用户意图召回
基于用户意图的召回,旨在提高类目多样性。首先根据用户查询文本进行意图类目的预测,然后根据预测的多个类目进行帖子召回。
在进行意图类目预测时,由于58本地服务类目体系复杂,二级类目有200多个,如果直接进行二级类目预测准确率不高,模型效果差。而一级类目仅有十几个,并且每个一级类目下属的二级类目也在二十个左右,因此我们考虑结合一级类目体系,采用分级预测的方式,先进行一级类目的预测,然后在该一级类目下再进行二级类目的预测。类目预测的流程如图4所示,包括样本数据准备和模型训练两部分。
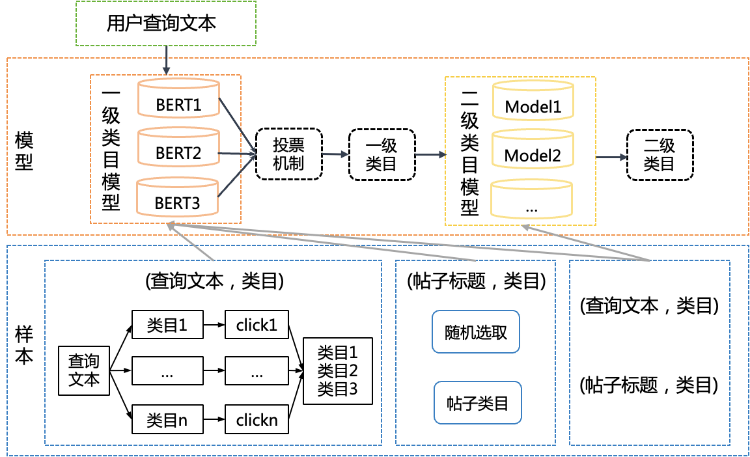
图4 类目预测
1、样本数据
模型训练首先要准备样本数据,为减少人工标注成本,利用用户历史搜索行为以及58本地服务帖子信息,包括三类样本数据:
样本1:利用搜索场景中用户点击数据构造训练数据。首先统计用户搜索并产生点击行为的帖子集合,取帖子集合中头部类目作为当前搜索词的检索意图,生成样本(查询,类目)
样本2:利用帖子自身的标题信息,获取帖子标题及对应类目,作为样本(标题,类目)
样本3:结合1)和2)的样本数据,生成样本(查询,类目)+(标题,类目)
样本1基于用户的历史行为生成,可以较好的体现用户真实查询行为,但是可能会存在查询串与帖子类目不匹配的错误数据,同时在真实的用户查询数据中,多为短查询,长查询样本数据较少。而样本2基于帖子自身的标题及类目信息,标题及类目的对应更为准确,同时可以对长查询样本数据进行补充。另外在样本数据准备中我们对样本进行了去噪处理,在样本数据中会存在一些无意义的文本,如单字查询,我们对这部分查询文本进行了过滤。同时为保证样本均衡,对样本数据量多的类目随机抽取进行降采样,对样本数据量少的类目进行数据增强。在数据增强时对查询文本进行以下操作:替换(用同义词替换文本中的部分词语)、删除(删除一个词语)、插入(随机选择一个原句的词语的同义词插入)、交换(随机抽取词语交换顺序),从而达到样本增强的目的。
2、模型设计
类目预测模型训练中我们使用BERT模型,BERT预训练使用了大量语料,通用语义表征能力更好, Transformer 结构特征提取能力更强。中文 BERT 基于字粒度预训练,可以减少未登录词的影响。此外,BERT 中使用位置向量建模文本位置信息,可以解决语义匹配的结构局限。
如图4所示我们需要训练两类模型,使用样本1、样本2、样本3分别进行一级类目模型的训练,得到一级类目模型:BERT1、BERT2和BERT3,使用样本3针对每一个一级类目训练一个二级类目预测模型:Model1、Model2...。
对于用户的查询文本首先使用一级类目模型(BERT1,BERT2,BERT3)进行一级类目预测,然后利用投票机制对三个模型预测出的类目及相应概率,按照一定的人工规则进行计算,终完成一级类目的预测,得到一级类目后,选取该一级类目对应的二级类目预测模型,终得到所属二级类目。
我们借助wpai模型训练平台进行模型的训练,为了保证线上性能,我们在保证效果的情况下,使用2层小网络。后我们结合用户查询文本及类目预测的多个二级类目,利用主搜服务进行多个类目下的帖子召回。
二、基于搜索词向量的召回
基于搜索词的向量召回,旨在召回与用户查询文本语义相关的帖子。如图5所示,离线部分采用DSSM模型进行查询向量embedding,然后将embedding向量灌入FAISS中建立索引。在线部分,将用户查询文本生成embedding向量,在FAISS中查找近的向量,将对应的帖子作为召回结果返回。
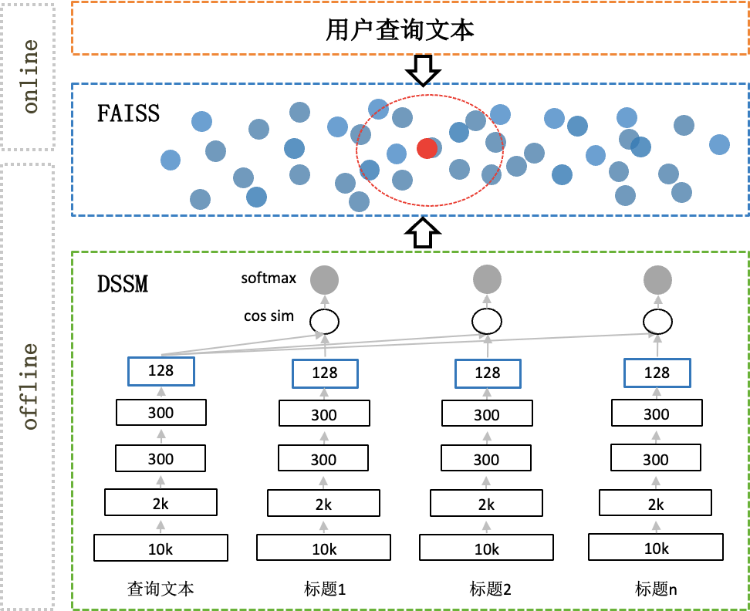
图5 向量召回
我们这里采用DSSM模型建立用户历史查询与帖子标题之间的相关性。网络结构比较简单,如图5所示,由几层全连接组成网络,将用户查询文本和对应的帖子标题输入到网络,进行模型训练,终得到embedding向量。
训练模型时首先要准备样本数据,在样本数据选择中,基于排序模型的经验将有转化的帖子作为正样本,将曝光无转化的帖子作为负样本,发现模型效果不理想,因此我们对负样本进行分析发现,使用曝光无转换的帖子作为负样本是不合适的,具体原因如下:
1、排序是优中选优,召回算法面对的候选样本太多,鱼龙混杂,更需要具备在更大的数据集中增加自己的“见识”,也就是更需要见见那些曝光没那么高的样本
2、曝光未转化的样本已经是经过召回,排序选出来的认为的用户喜欢的物品,也就是说这些样本已经是上一个版本召回模型选出来正样本了,如果我们把这些样本当作新召回模型的负样本,是相互矛盾的
3、如果选择曝光未转化的样本作为负样本,曝光帖子仅为一小部分,线上预测时在整个数据集进行预测,存在样本偏差问题
所以我们在负样本的选择时,对一个正样本通过随机采样的方法选取k个帖子,作为负样本。我们对负样本的选择进行了不同模型的训练,离线效果数据如表1,结果显示随机选取负样本的离线效果是优的。
表1 负样本auc对比

使用准备好的样本进行DSSM模型训练,生成embedding向量,利用FAISS索引技术建立相应索引。FAISS可以对向量进行相似搜索,根据给定的向量,在所有已知的向量库中找出与其相似度高的一些向量,并且具有查询速度快、占用空间小的优点,同时可以根据实际业务需要选择合适的索引:IndexFlatL2,IndexIVFFlat和IndexIVFPQ。在保证召回相关性的前提下,我们采用了IndexIVFFlat索引。
三、基于扩展标签召回
为了更多的召回与用户查询文本相关的帖子,我们还进行了标签召回,如图6所示。58本地服务标签系统中有大量优质的相关业务标签,系统较为完备,因此我们利用标签系统对用户查询文本进行扩展,从用户的查询文本中提取相关的标签,得到与业务相贴合的标签词,后结合标签词,利用主搜服务召回相关帖子。
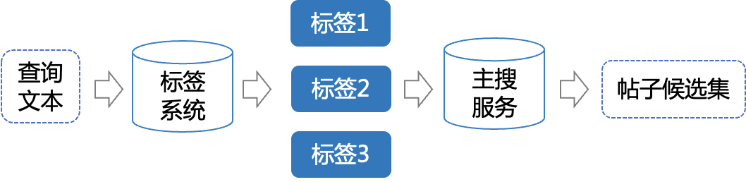
图6 标签召回
四、补充召回
补充召回目的是在其他召回策略均无结果的情况下,进行策略兜底,主要包括根据用户查询文本进行相关热门帖的召回,如图7所示。

图7 补充召回
在热门帖的召回策略中,由于我们优化的目标是提升连接数,因此我们离线统计历史帖子的call/uv,然后按照城市和类目的维度将top帖子作为热门帖进行离线存储方便线上使用。在线上召回时,首先对用户搜索文本进行类目预测,然后根据类目预测的结果进行该城市类目下的热门帖。
排序层
在排序层中,主要是对召回结果进行排序,将用户可能感兴趣的内容展现在前面。另外我们希望少无结果推荐的优化迭代可以提升用户连接数,进而提高转化率,因此我们结合业务场景尝试了不同的排序模型,下面介绍下排序模型的演进过程。
在模型训练中特征的选择尤为重要。我们主要采用了用户特征、帖子特征、商家特征和上下文特征。用户特征包括历史行为如查询文本等,帖子属性特征包括点击率、转化率以及帖子自身的属性特征如标题、图片等,商家特征主要包含商家等级、是否为58会员等。上下文特征主要有城市、类目、lbs等。这些特征大多数为连续特征(点击率、商家分等)和离散特征(城市、类目等),其中用户历史查询文本和帖子标题为文本特征,我们先将其进行embedding,然后与其他特征拼接后作为模型的输入。
初始模型我们采用树模型:XGBoost,该模型实现了非线性和自动的特征组合。树节点的分裂实现了特征的非线性,树的层次结构实现了特征的自动组合,而且树模型对特征的包容性非常好,树的分裂通过判断相对大小来实现,不需要对特征做特殊处理,为了快速上线我们首先考虑了树模型,并将其作为baseline。
XGBoost擅长处理连续特征,对离散特征不太友好,另外XGBoost具有很强的记忆行为,为防止过拟合需要剪枝,限制树的深度,这就导致特征组合的能力有限。而DNN类的模型有很强的模型表达能力,能够学习高阶特征,同时容易扩充其他类别的特征,因此我们考虑DeepFM模型,如图8所示,该模型结合了FM算法和DNN算法,可以同时提取低阶特征和高阶特征。DeepFM模型将输入的id类稀疏特征如城市、类目等先通过embedding层转化低维稠密的向量,左边的FM子网络用它们计算二阶交叉分数,右边的DNN子网络把它们和其他连续型特征拼接起来输入一个MLP获取其后一层输出,后将FM一阶、二阶分数和DNN的后一层拼接在一起,做一个投影得到终的打分。
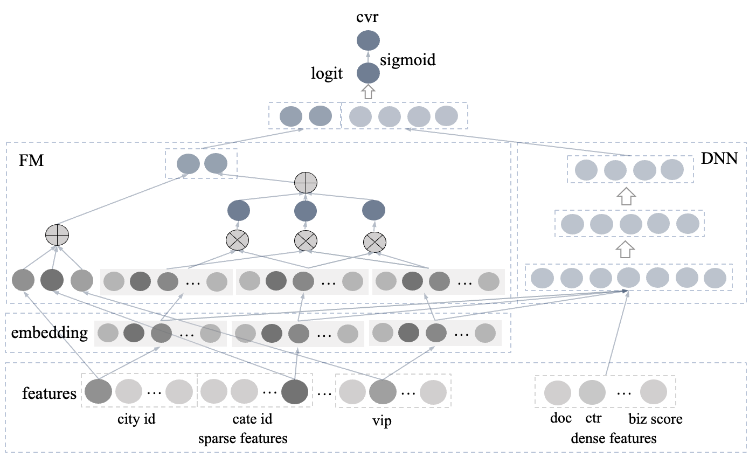
图8 DeepFM模型框
DeepFM上线后,电话量有所提升,但是我们期望在提升连接数的同时优化转化率,因此我们引入多任务模型MMoE。该模型引入了多个专家子网络和门控结构,通过门控用不同的专家组合分别去学习不同的目标,使得各个目标能被更好地学习。图9是MMoE模型结构示意图,输入向量分别输入到两个专家网络Expert 1和Expert 2中,每个专家是一个DNN子网络,DNN的后一层为专家的输出向量。输入向量和各个专家的输出向量会传入门控,门控的内部结构如图6(b)所示,输入向量首先经过一个MLP,后一层softmax得到各个专家的权重,然后以此权重对各个专家的输出做一个加权求和,得到该门控下的输出向量。在MMoE中,专家网络是所有目标共享的,每个目标有一个自己的门控,用于确定该目标下各个专家的权重。MMoE中的门控,可以被看成是一个分类器,每个目标的门控会根据当前样本的特征,判别它由哪些专家来拟合会更好,预估出每个专家的权重。MMoE不同目标不一样的动态输入为各目标的拟合提供了更大的自由度。

(a) MMoE结构图

(b) 门控结构图
图9 MMoE模型
MMoE虽然可以同时学习ctr和cvr,但是并没有过多的考虑任务之间的联系,而ctr、cvr存在关联,用户的转化行为产生于点击行为之后。在58本地服务推荐场景中曝光的帖子量是很大的, 用户点击的帖子只是其中的一小部分,用户进行转化的帖子又只是有点击帖子的一部分,这就导致正负样本极度不均衡,加大了模型训练的难度,同样带来了泛化性问题。另外,由于训练和预测数据的范围不一致,还存在样本偏差的问题。为缓解上述问题,我们采用ESMM 模型,该模型可以利用用户行为序列数据,结合ctr和cvr的关联信息,在完整的样本数据空间同时学习点击率和转化率。
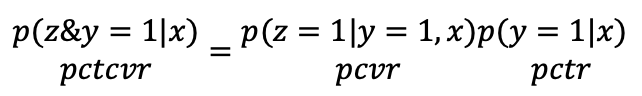
ESMM利用上式中的关联关系,通过学习ctr和ctcvr两个任务,隐式地学习cvr任务,具体结构如图10所示。左边的子网络用来拟合 pcvr,右边的子网络用来拟合 pctr。两个子网络的结构是完全相同的,并且共享 Embedding 参数。两个子网络的输出结果相乘之后即得到 pctcvr,并作为整个任务的输出。
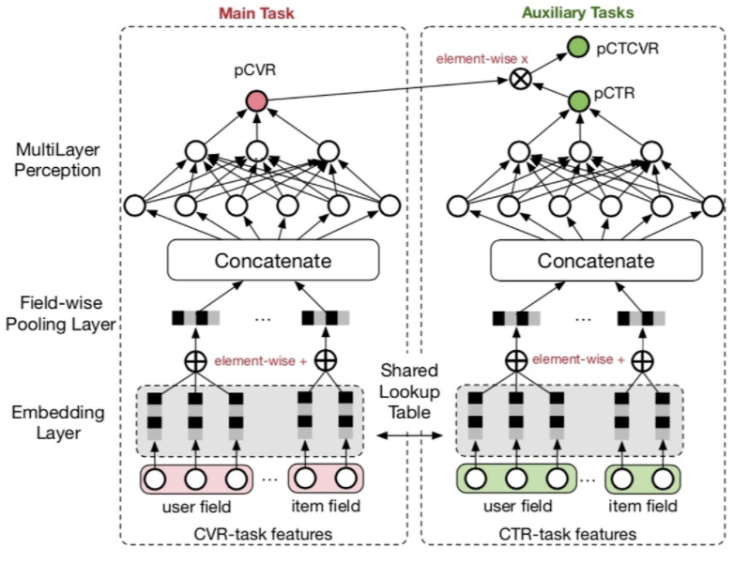
图10 ESMM模型图
ESMM模型利用不同任务之间的相互联系,进行多个任务的预估,但是任务子网络为简单的DNN结构,而deepFM可以将DNN与FM相结合同时提取高阶特征和低阶特征,我们是否可以将deepFM和ESMM模型相结合,提取低阶高阶特征的同时进行多任务的学习。如图11所示,保留了deepFM中的FM部分,deepFM的DNN部分使用ESMM的结构,ESMM的cvr任务模块和ctr任务模块输出的向量分别与FM的一阶二阶分数拼接在一起,得到两个新的向量,然后分别预估ctr和cvr,ctr和cvr的乘积则可得到ctcvr的预估值。
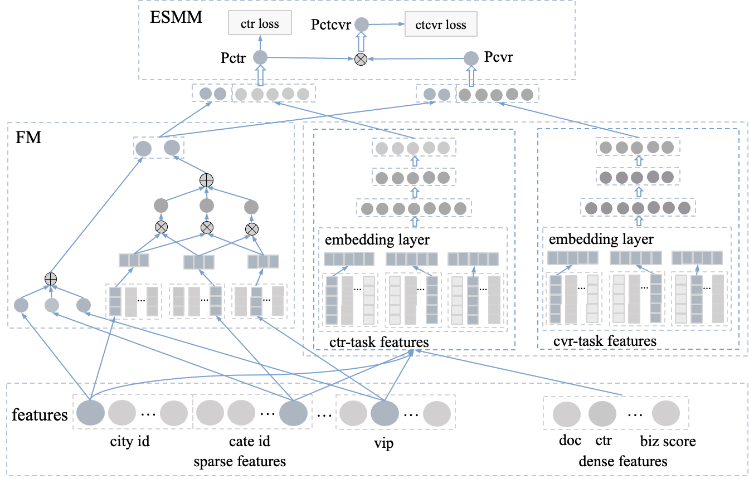
图11 deepFM+ESMM模型
另外我们也考虑过将deepFM、MMoE及ESMM相结合,即将deepFM的DNN模块替换为MMoE,然后再引入ESMM的思想,通过预估ctr和cvr得到ctcvr的预估值,由于模型复杂度较高,并未在线上使用,后续我们将尝试将该模型应用于线上。
总 结
猜你想找针对少无结果进行帖子推荐,有效的降低了少无结果率,并且大幅提升了58本地服务的用户转化。在猜你想找推荐场景中,既要解决搜索的相关性问题,又要解决“千人千面”的排序结果,优化用户体验,还要满足业务需求。我们通过召回和排序两个模块,有效地解决这个问题。在召回层中我们通过多路召回的方式来保证查询的相关性以及召回率,另外在排序中尝不同的模型,一定程度上提高用户的转化。在未来的工作中,我们可以更多的结合业务特点来进行推荐效果的优化。
参考文献:
[1] Devlin, Jacob, et al. “BERT: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[2] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. “Distilling the knowledge in a neural network.” arXiv preprint arXiv:1503.02531 (2015).
[3] Sanh, Victor, et al. “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.” arXiv preprint arXiv:1910.01108 (2019).
[4] Jiao, Xiaoqi, et al. “Tinybert: Distilling bert for natural language understanding.” arXiv preprint arXiv:1909.10351 (2019).
[5] T Chen, C Guestrin. XGBoost: A scalable tree boosting system. KDD2016.
[6] Xiao Ma,et al. ESMM-Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate (2018)
作者简介:
刘静:
原文链接:https://mp.weixin.qq.com/s/c5vt3PKQ3I78vMsC41zn7w
