LevelDB是由Google开源的,基于LSM Tree的单机KV数据库,其特点是高效,代码简洁而优美。Rocksdb则是Facebook基于LevelDB改造的,它在level的基础上加了很多实用的功能,例如Column Family等,具体的差别大家可以Google,也可以实际用一下体验一下,这里就不再赘述了。
Rocksdb目前已经运用在许多知名的项目中,例如TiKV,MyRocks,CrockRoach等。
Rocksdb使用上的缺点
rocksdb是通过wal来保证数据的持久性的,当rocksdb出现问题当机后,可以通过重做wal来使rocksdb恢复到当机前的状态。但是这里存在两个问题
1、当你为了读性能把memtable设置的足够大时,WAL也可能变得很大(Flush频率下降),此时如果发生当机,rocksdb需要足够长的时间来恢复。
2、如果机器硬盘出现损坏,wal被破坏,那么会出现数据损坏。即使你做了Raid,也需要很长时间来恢复数据。
因此可用性是个大问题。
另外由于LSM架构,rocksdb的读性能存在问题。
怎么解决?
为了一致性,大部分的解决方案都是将一致性协议置于rocksdb之上,每份数据通过一致性协议提交到多个处于不同机器的rocksdb实例中,以保证数据的可靠性和服务的可用性。
典型如TiKV
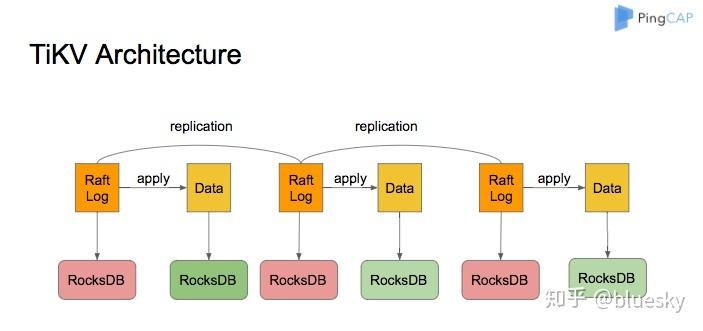
但这也还是有缺点,本身LSM Tree架构的一大问题就是写放大。每个rocksdb为了提高读性能,都会进行Compaction,而似这样的多份(一般3份)写入rocksdb,等于CPU消耗确定会*3,并且写放大由于提高了写的次数,即提高SSD的擦写次数,会显著减少SSD的寿命,提高系统的成本。
来源 https://zhuanlan.zhihu.com/p/162052214
