
大家好,我是榕树。
之前我写了缓存和消息队列的一些文章,下面我整理在一起,方便大家阅读。
缓存篇
缓存穿透了,怎么办?
(缓存系列一)你知道哪几种缓存策略?
缓存系列二|你会怎么设计缓存的高可用?
缓存系列三|你会怎么实现客户端的高可用策略呢?
缓存系列四|你知道redis的高可用策略么?
消息队列篇
消息队列一|从秒杀活动开始聊起消息队列
消息队列二|如何避免消息丢失和重复消费?
消息队列三|Kafka 如何做到高可用?
接下来几周,我想聊聊数据库使用相关的内容。对这方面有兴趣的读者可以关注下哈。
今天我们先聊聊如何做主从读写分离。说到读写分离,不管小公司还是大公司,大家在实际工作中,应该也都用过。因此小编这边先抛几个问题,大家可以思考下。
什么时候需要做读写分离呢?
读写分离,怎么做呢?
读写分离会带来什么问题呢?如何解决呢?
如果你觉得有些问题还比较模糊的,那么可以看看我是怎么理解这些问题的。
什么时候需要做读写分离呢?
在我们负责的系统中,大部分是读多写少的请求,就拿小编写公众号文章的场景来举例,大部分读者都是读公众号的文章,写公众号的总是比较少的。因此为应对这种读多写少的场景,我们会想到使用读写分离的方式去分流,但具体要达到什么样的量级才有需要去做读写分离呢?
比较稳妥的方式是,你需要对你的数据库分别做写和读压测,就能知道目前数据库实例能够扛住的大TPS和QPS访问量。
下面给个参考,在 4 核 8G 的机器上运 MySQL 5.7 时,大约可以承受 10000 的 QPS 访问量。
也就是说,如果你的业务是读多写少的,预估到你的系统在高峰期时超过数据库大访问量的一半,比如大的访问量是10000 qps,那你的高峰期访问量超过5000qps,那就需要考虑使用读写分离的方式了。
读写分离,怎么做呢?
敲黑板了!做数据库读写分离,主要有以下两个关键点。
1 数据库层面,主从库的数据复制同步。
2 中间件层面,既要能具备通用性,又要让业务开发像操作单个主库一样,无需太关注主从分离的细节。
考虑做读写分离之后,你的数据库存储架构会变成这样。主库主要负责数据的写入操作,从库主要负责读操作。

图 1
数据库层面,mysql是怎么处理主从同步呢?
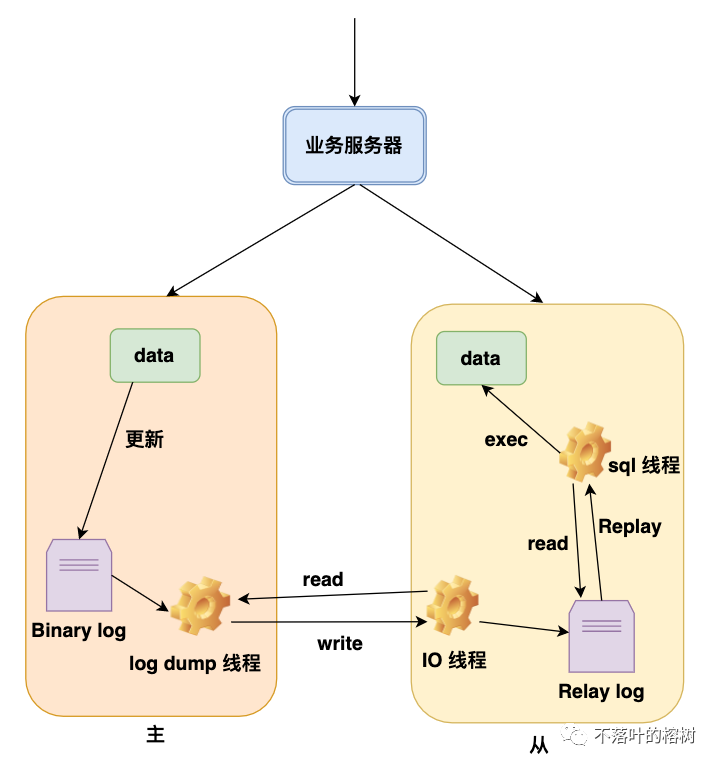
图 2
首先主库上的新增,删除,修改操作都会被记录到一个叫做Binary log(简称binlog)的二进制日志文件文件中。
从库通过IO线程和主库交互,读取binlog文件并写入到的中转日志文件relaylog中。
主库会生成一个 log dump 线程,用来给从库IO线程传binlog日志。
从库的sql线程读取中转日志,解析出日志里的命令,并执行,从而能够同步日志。为了提高写命令的执行效率,mysql还引入了复杂的sql多线程去并发执行。
mysql的同步复制数据的设计,也是值得我们日常工作借鉴,比如说在第2步骤中,为什么还要搞一个中转日志,而不是IO线程直接执行该命令?
原因是如果不是像mysql这么去设计,就是同步写了,从库IO线程执行命令较慢时,就会影响从库响应主库变慢,可能出现长时间占用主库线程的情况。这种情况类似我们平时在工作中两个服务的接口对接,A服务调用B服务的接口,如果你是B服务的开发工程师,你的接口内部需要执行一系列的复杂操作,那么你的服务可能响应较慢,严重时可能会导致A服务那边提示超时,这种情况你就可以借鉴mysql的这个设计,你可以把A服务请求先保存下来,之后在通过异步线程去扫表消费数据,执行对应的处理逻辑,这样就能提高响应速度。
中间件层面,应该怎么做呢?
主要想说两点。
1 架构层面通用性。
2 功能上易用性。
说说架构层面通用性。
如果你们公司只使用一种语言,那么你们的架构应该是【图1】那样,如果你们公司是有不同语言的开发团队,比如有java,有go,有php等,如果按照【图1】的架构,那么各个语言的团队都需要自己去开发对应的中间件客户端,也是算重复造轮子。遇到这种多语言的情况,我们可以调整下【图1】的架构,增加一个proxy层。

图 3
这样架构的优势在于具备多语言通用性,也有一个开源组件mycat就是这样做的,mycat是一个实现了MySQL协议的服务器,前端用户可以把它看作是一个数据库代理,用MySQL客户端工具和命令行访问,而其后端可以用MySQL原生协议与多个MySQL服务器通信。
但是这样的架构也是有一些劣势的:
1 多增加一个proxy层,网络上增加了一跳请求,访问时间增长。
2 proxy 也是要集群部署的,涉及到集群部署,复杂性也就跟着提高了。
因此要按需去选择。
说说功能上的易用性。
易用性的目标是要让业务开发像操作单个主库一样,无需过多关注主从读写分离的细节,只需要把对应的主库的数据库信息和从库的数据库信息配置好,之后业务开发同事写业务代码时,就不用再去考虑写主读从的细节了。因为读的时候,能自动去读从库,写的时候,能自动去写主库。
现在市面上也有一些开源组件的实现,这边我比较推荐 ShardingSphere,在我的项目中,我也是在ShardingSphere的sharding-JDCB基础上,做了简化配置的封装。之后也做过一些压测,性能没问题后,就提供给业务开发童鞋去使用了。
读写分离会带来什么问题?如何解决呢?
上面我们聊了主从复制同步数据的过程,从【图2】我们可以知道,如果主库log dump 线程同步数据给从库出现网络延迟,或者sql线程同步执行命令较慢,都可能导致主库和从库出现数据不一致。
在我过去的开发经验中,也出现过主从延迟导致的问题,比如商家更新一条商品内容,之后刷新页面发现商品信息未更新,如果是延迟时间较短,可能他多刷新两次,就更新了,但是如果延迟时间较长的话,刷新几次之后,还不能更新,用户体验就很差了。类似这样的问题,开发同学如果不知道数据库主从延迟可能带来的问题,排查这类问题也是会一头雾水。
那么主从延迟的问题应该怎么解决呢?
有如下三板斧:
1 主从延迟的监控告警
2 业务层面去解决
3 数据库层面去解决
主从延迟的监控告警
刚刚说到排查主从延迟的问题,对开发同学来说是一个难题,因此要解决主从延迟的前提是,怎么知道是不是主从延迟的问题。
因此我们需要做一些对应的监控,发现延迟也可以告警通知出来。
有以下两种方法:
1 通过对从库发起 show slave status 命令输出的 Seconds_Behind_Master 参数的值来判断。
值有以下几种:
NULL , 表示io 线程或是sql 线程至少有一个发生故障。
0 ,该值为零,表示主从复制良好
正数 ,表示主从已经出现延时,数字越大表示从库落后主库越多。
Seconds_Behind_Master是通过比较从库的sql 线程执行的event的timestamp和 io 线程复制好的event的timestamp(简写为ts)进行比较,而得到的这么一个差值。因此这种方式是要在主库和从库网络良好的情况下,该值才有价值的。
2 使用Maatkit的mk-heartbeat工具
它需要在主库上创建一个heartbeat的表,里面至少有id与ts两个字段,id为server_id,ts就是当前的时间戳 now(),该结构也会被复制到从库上。表建好以后,会在主库上以后台进程的模式去执行一行更新操作的命令,定期去向表中的插入数据,这个周期默认为1秒,同时从库也会在后台执行一个监控命令,与主库保持一致的周期去比较,复制过来记录的ts值与主库上的同一条ts值,差值为0表示无延时,差值越大表示延时的秒数越多。
这种方式被认为可以准确判断复制延时的方法。
业务层面有哪些办法呢?
1 通过页面缓存写入的数据来解决,比如在我们刚刚提到的商家更新商品内容的案例,我们可以将商品内容记录缓存一份在页面,更新完商品直接使用该缓存的记录,而不是直接去查数据库。
2 通过nosql(memory cache或者redis)缓存数据库的方式去解决,更新数据库时,同时也更新缓存,查询时可以直接查询nosql缓存。
3 对读写一致性要求高的业务,在写操作后的读操作时可以直接查询主库,不过这种要做好对主库的监控,确认查询量是主库可以支撑的才能这么做,如果主库实在是支撑不住,我们可以再考虑分库去解决(我们下一篇文章中,再详细聊一聊分库分表)。
数据库层面有哪些方法呢?
我主要推荐以下两种:
1 半同步复制的方案,就是 semi-sync replication。
这种方式就是数据写入主库后,主库需要将bin log 同步到从库,收到从库的ack回复才能告知业务客户端数据写入成功了。也就是双写机制,需要主从库都写入成功才确定是成功的。这种方式就是针对一主一从的方式,如果是一主多就无法保证了。
很多公司其实数据量并没有那么大,有时候一个主库一个从库就能支撑业务了,遇到这种情况可以使用半同步复制的方式。
2 GTID方案
MySQL 5.7.6 版本开始,允许在执行完更新类事务后,把这个事务的 GTID 返回给客户端,为了能获得这个GTID,需要将主库参数 session_track_gtids 设置为 OWN_GTID,然后通过 API 接口mysql_session_track_get_first 从返回包解析出 GTID 的值。
MySQL 5.7.6 版本还提供了这样一个命令:
select wait_for_executed_gtid_set(gtid_set, 1);
这条命令的执行逻辑是:
等待,直到这个库执行的事务中包含传入的 gtid_set,返回 0;超时返回 1。
我们执行写入和查询的流程就是这样:
写入主库的事务更新完成后,从返回包直接获取这个事务的GTID
查询从库时,执行 select wait_for_executed_gtid_set(GTID, 1);
如果返回是0,则可以执行从库查询语句,否则,到主库执行查询语句。
总结
本篇文章中,我分析了什么时候要做读写分离,以及如何读写分离,后我针对读写分离可能带来的主从延迟问题,提出要先做好监控告警,之后再给一些针对主从延迟的解决方法。在我们日常的开发中,读写分离带来的主从延迟偶尔还是会发生的,因此我这边给一个建议,在你拿到需求做设计时,就要把数据库的主从延迟问题考虑进去,因为在数据读写一致性要求高的业务中,如果延迟太久,对用户很不友好,比如我在某商城购物,商品加入购物车之后发现购物车竟然没展示出来,体验还是不太好的。当然如果是对读写一致性要求不高的场景,比如我更新一篇公众号,读者晚一些时候看到,倒也是还能接受的。这种情况我们可以不用去针对主从延迟做特殊的处理,毕竟也会带来复杂度。因此要不要处理主从延迟的问题,还是要根据具体业务做一些权衡。
这边留个比较有意思的问题,之前我们聊到Kafka的高可用,Kafka的生产端和消费端都是直接和leader(主)节点交互的,那Kafka为什么不支持主从读写分离呢?
欢迎关注公众号,评论交流,如果您觉得小编写的还行,文章下方可以点击【分享】【在看】让更多人看到。

因个人能力有限,读者如发现错误或有更好的建议,欢迎留言批评指正,非常感激。
参考
1 《高性能MySql》--Baron Scbwartz等著,宁海元等译
2 读写分离有哪些坑? --林晓斌
3
