
Splice Machine 是一个可扩展的关系型数据库、数据仓库、机器学习平台,可以无缝将数据分析、AI 的能力集成到应用。
Splice Machine is a scale-out SQL RDBMS, Data Warehouse, and Machine Learning Platform in one, seamlessly integrating analytics and AI into your mission-critical applications.
HTAP Architecture
Splice Machine 采用双引擎架构,来同时支持 OLTP 与 OLAP 混合负载,SQL 引擎会自动根据查询请求来决定查询引擎; Splice Machine 采用 HBase 来支持 OLTP 类的高并发 insert、point query、以及小的范围查询,采用 Spark 来支持高性能的内存数据分析与处理。
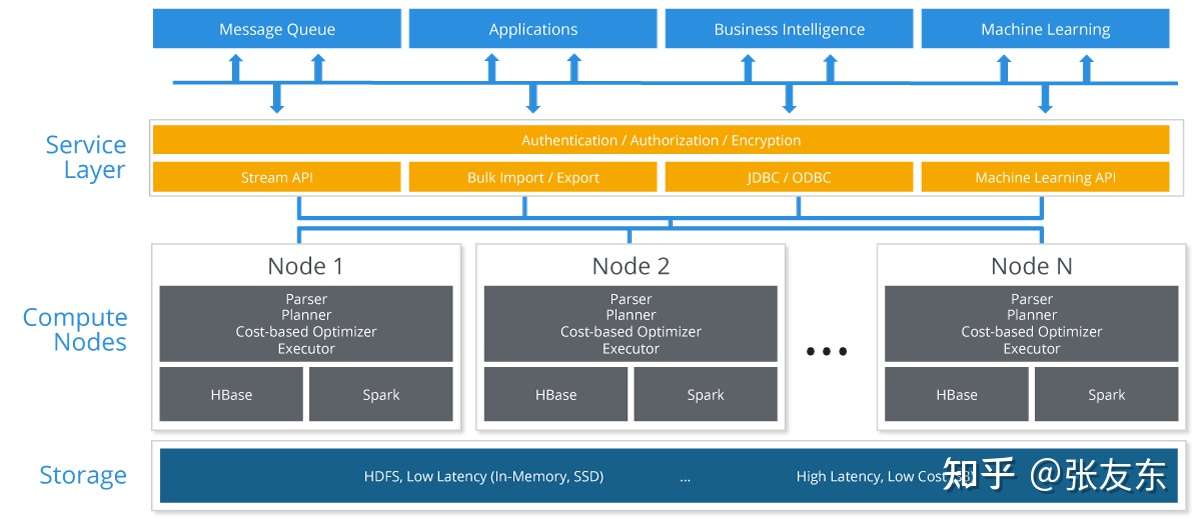
Splice Machine 在 HBase + Spark 的基础上,做了如下工作
- Spark 可以直接访问 HDFS 上的 HFile 来读取数据,绕过 HBase 引擎层。
- 在开源 HBase、Spark 之上,扩展了 ANSI SQL 的支持,作为 Splice Machine 的访问入口,TP、AP 的请求会分别路由到 OLTP 的 HBase 引擎 和 OLAP 的 Spark 引擎。
- 基于数据层 Splice Machine 构建机器学习 feature store,并基于开源 MLFlow 面向数据科学家推出 ML Manager,让机器学习流程更简单。
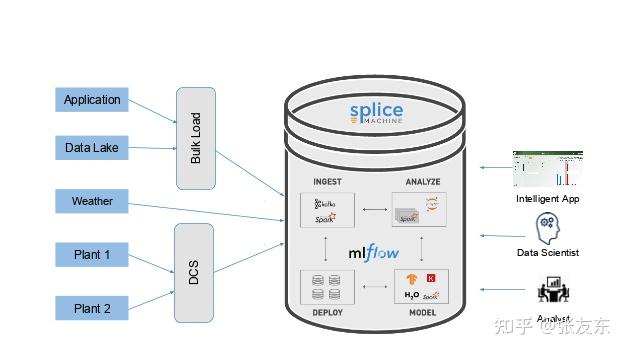
Splice ML Manager
Splice Machine 利用 MLFlow 来管理整个机器学习流程,整个 WorkFlow 包括
- Data Ingestion:实时或批量的方式,从 Kafka、AirFlow、Spark 等平台通过 JDBC 写入数据。
- Data exploration and analysis:通过 Jupter notebooks 来进数据处理
- Data investigation and engineering:
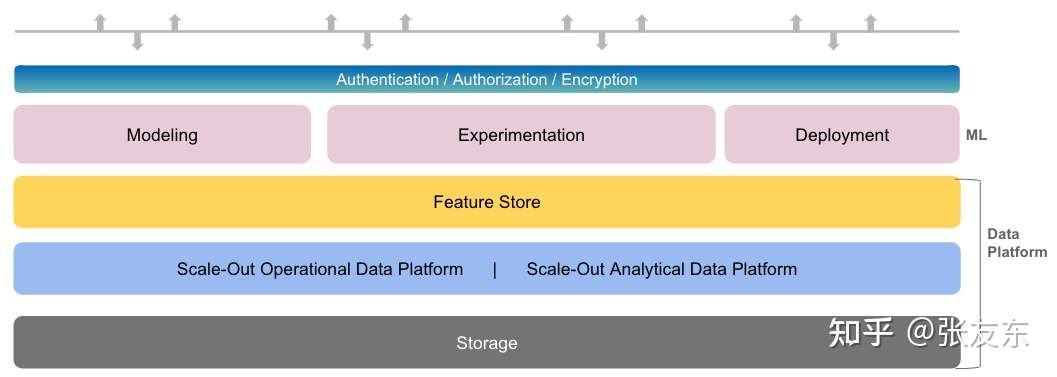
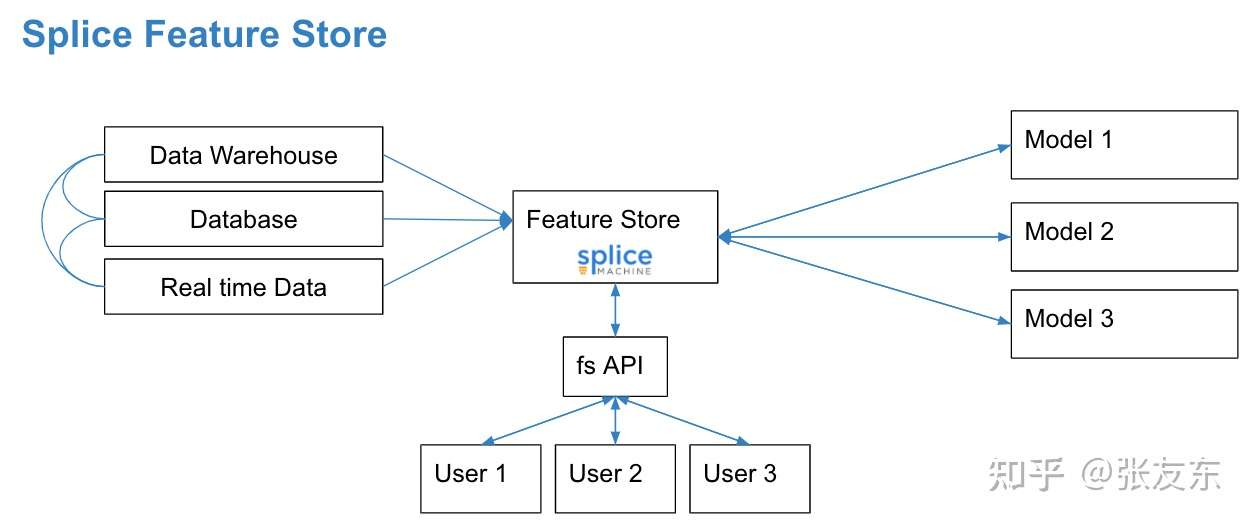
Splice Feature Store
Splice Feature Store 与底层的数据存储紧密结合,同时支持 Online、Offline 的特征存储;并支持自动存储特征的历史版本简化训练数据的管理。
Splice Machine 的问题
我个人理解,Splice Machine 存在的主要问题
- 缺乏核心技术: HBase、Spark、MLFlow 均为第三方的开源技术,Splice 的核心竞争力在于把三者进行整合提供解决方案,类似于同样没发展起来的 Cloudera 模式?
- 产品定位不清晰:Splice Machine 是一个可扩展的关系型数据库、数据仓库、机器学习平台,从这几个角色定位看,基于 HBase 构建的 RDBMS 竞争力不如专业的 OLTP 数据库,基于 Spark 构建数据仓库,相比 Hudi、Iceburg、Delta Lake 湖仓一体的方案也缺乏竞争力;而作为机器学习平台,也是基于开源 MLFlow 开发了 ML Manager,面向的使用者是数据科学家,跟关系型数据库、数据仓库面向的使用者定位也不一样,所以系统很难把这几个角色很好的统一起来。
- 关于 ML 的能力,对于大的企业,通常有较大的投入,算法工程、数据工程、ML流程上通常有完备的投入;而对于小的企业,能力虽有需求,但通常没有专职的投入;ML 的能力建设可能更多的往两个极端,一个是完全掌控的灵活性,适用于大规模业务场景;一个是完全不需要关注的易用性,比如在数据系统里内置 ML 的能力,让用户能轻松的使用起来,至于中间状态(简化 MLFlow 里的部分步骤)当前的市场需求并不清晰。
