
现象与问题
ORDER BY 排序后,用 LIMIT 取前几条,发现返回的结果集的顺序与预期的不一样。


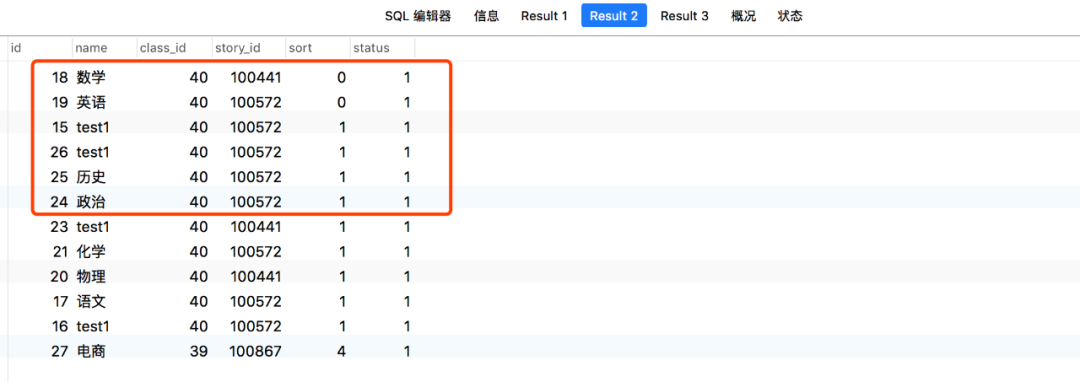

可以看到,带 LIMIT 与不带 LIMIT 的结果与我预期的不一样,而且“很不可思议”,真是百思不得其解。
后来百度了一下,如果 order by 的列有相同的值时,MySQL 会随机选取这些行,为了保证每次都返回的顺序一致可以额外增加一个排序字段(比如:id),用两个字段来尽可能减少重复的概率。
于是,改成 order by status,id:

问题虽然是解决了,但还是看看官方文档上怎么说的吧!
LIMIT 查询优化

摘自“LIMIT 查询优化”
如果你只需要结果集中的指定数量的行,那么请在查询中使用 LIMIT 子句,而不是抓取整个结果集并丢弃剩下那些你不要的数据。
MySQL 有时会优化一个包含 LIMIT 子句并且没有 HAVING 子句的查询:
①MySQL 通常更愿意执行全表扫描,但是如果你用 LIMIT 只查询几行记录的话,MySQL 在某些情况下可能会使用索引。
②如果你将 LIMIT row_count 子句与 ORDER BY 子句组合在一起使用的话,MySQL 会在找到排序结果的个 row_count 行后立即停止排序,而不是对整个结果进行排序。如果使用索引来完成排序,这将非常快。
如果必须执行文件排序,则在找到个 row_count 行之前,选择所有与查询匹配但不包括 LIMIT 子句的行,并对其中大部分或所有行进行排序。
一旦找到个 row_count 之后,MySQL 不会对结果集的任何剩余部分进行排序。
这种行为的一种表现形式是,一个 ORDER BY 查询带或者不带 LIMIT 可能返回行的顺序是不一样的。
③如果 LIMIT row_count 与 DISTINCT 一起使用,一旦找到 row_count 惟一的行,MySQL 就会停止。
④LIMIT 0 可以快速返回一个空的结果集,这是用来检测一个查询是否有效的一种很有用的方法。
⑤如果服务器使用临时表来解析查询,它将使用 LIMIT row_count 子句来计算需要多少空间。
⑥如果 ORDER BY 不走索引,而且后面还带了 LIMIT 的话,那么优化器可能可以避免用一个合并文件,并使用内存中的 filesort 操作对内存中的行进行排序。
⑦如果 ORDER BY 列有多行具有相同的值,服务器可以自由地以任何顺序返回这些行,并且根据总体执行计划可能以不同的方式返回。换句话说,这些行的排序顺序对于无序列是不确定的。
影响执行计划的一个因素是 LIMIT,因此对于一个 ORDER BY 查询而言,带与不带 LIMIT 返回的行的顺序可能是不一样的。
看下面的例子:
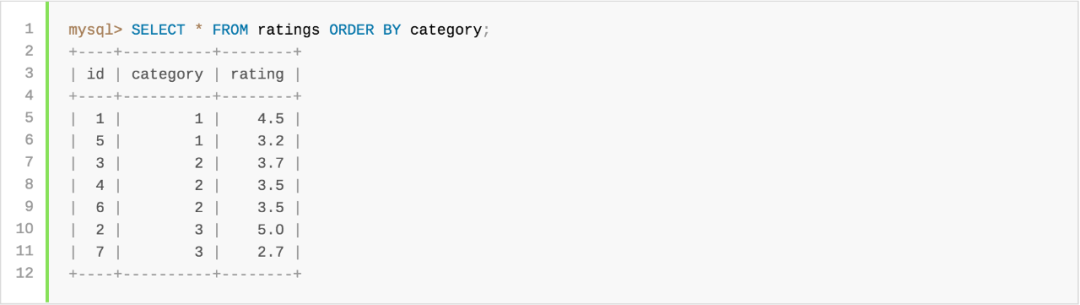

如果你需要确保无论带不带 LIMIT 都要以相同的顺序返回,那么你可以在 ORDER BY 中包含附加列,以使顺序具有确定性。例如:

小结
如果你只需要结果集中的某几行,那么建议使用 limit。这样这样的话可以避免抓取全部结果集,然后再丢弃那些你不要的行。
对于 order by 查询,带或者不带 limit 可能返回行的顺序是不一样的。
如果 limit row_count 与 order by 一起使用,那么在找到个 row_count 就停止排序,直接返回。
如果 order by 列有相同的值,那么 MySQL 可以自由地以任何顺序返回这些行。换言之,只要 order by 列的值不重复,就可以保证返回的顺序。
可以在 order by 子句中包含附加列,以使顺序具有确定性。
https://dev.mysql.com/doc/refman/5.7/en/limit-optimization.html
https://dev.mysql.com/doc/refman/5.7/en/
https://dev.mysql.com/doc/
编辑:陶家龙
出处:cnblogs.com/cjsblog/p/10874938.html
