更新--案例讲解框架用法:玩点好玩的--100行代码抓取NBA全部球员的全部赛季数据
=============================================================
虽然不是专业的爬虫工程师,但作为一个Pythoner,一直对爬虫情有独钟。
Python有很多爬虫框架,比如Scrapy、PySpider等。我不是一个特别喜欢用轮子的人,所以根据有限的爬虫知识,结合其他框架架构,自己造了一个用起来特别顺手的轮子:PSpider,也加深了自己对爬虫框架、多线程、多进程等概念的理解。
PSpider框架的Github地址:xianhu/PSpider · GitHub,欢迎大家拍砖点赞。
从开始设计这个框架,就坚持“简洁”的原则,尽量不去使用一些的第三方库,同时保证代码量也比较少。所以这个框架完全可以当做自己练手写爬虫框架的参考。
先说一下PSpider都帮我做过哪些抓取工作吧。
- 抓取国内某融资平台网站的全部创业公司信息超过10万条
- 抓取国内某科技类新闻网站的全部新闻数据7万条左右
- 抓取某猎头公司的全部内部数据几十万条左右(数据是什么你应该懂,一直没公开)
- 抓取国内四大主流手机应用市场的全部信息,并以天为单位进行更新,每天20万条左右
- 抓取新浪微博、搜狗微信公众号等数据,几百万量级
- 抓取中国裁判文书网上的法律判决文书,1000万条左右
- 抓取教育类APP的题库数据,包括题目、答案、解析,20万条左右
- 还抓取过很多小网站、小应用,这里就不一一列举了
从开始着手PSpider到现在,也有将近两年的时间了。两年时间内,几乎每周都会对其进行修改,包括添加功能、修改Bug、更改接口等,以应对不同的应用场景。到了近半年PSpider才开始慢慢趋于成型和稳定,并应用在公司实际项目中。
PSpider的代码量非常少,只看代码的话都不足700行。当然另外还有相当一部分的注释和docstring,下图是这个框架代码方面的一些概览:

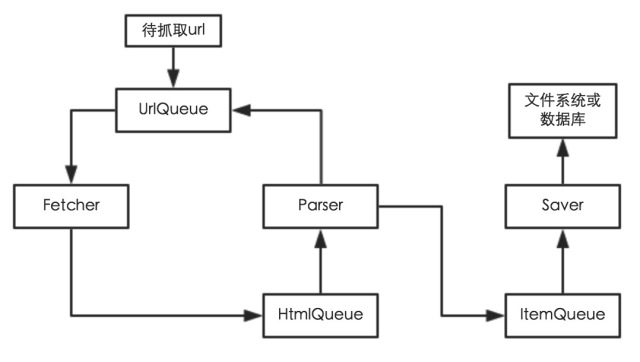
这里简单说一下框架的结构和功能,有什么不明白的,可以自己去读一下源码,应该很容易理解。PSpider框架主要有三个Module,分别为utilities、instances和concurrent。
- utilities模块:主要定义了一些工具函数、工具类等,即抽象出爬虫工作中的具体流程、通用流程等做成函数或者类,目的是为了节省爬虫工程师的时间。比如定义UrlFilter类用于过滤Url,定义params_chack装饰器用于检查函数输入参数等。该模块中的函数较多,大概有15个左右,具体可以去代码中查看,函数命名都比较规范,注释也都还算详细。
- instances模块:主要定义了Fetcher、Parser、Saver三个工作类,即爬虫在工作过程中真正干活的流程。如果把爬虫框架比作一个工厂,则concurrent模块定义多个车间并做相应的调度、信息同步等,instances模块定义每个车间中工人的工作流程,utilities模块定义一些生产过程需要的工具、机器等。使用框架时,一般都需要继承并改写上边的三个类,特别是Parser类,即三者都需要定制化,框架在这一步还做不到完全通用。Fetcher类根据url进行简单的抓取,并返回抓取内容。Parser类根据抓取内容进行解析,生成待保存的Item及待抓取的Url列表。Saver类进行Item的保存。(具体可查看上文中的流程图)。另外,三者都不需要改写每个类中的work函数,该函数会充分考虑流程中会遇到的问题,并作出正确的“回应”。
- concurrent模块:主要定义了一个线程池,以及一个进程、线程组合池,用于爬虫过程中线程/进程安全合理调度、进程线程之间数据共享同步等。如果解析类比较简单,不太消耗cpu资源,可以使用线程池ThreadPool,它会根据参数生成相应个数的抓取、解析、保存子线程。但是如果解析类比较复杂,是一个cpu密集型任务,由于Python中GIL的问题,如果单纯的使用多线程,可能效率会比较低,这时可以考虑使用ProcessPool,它会在主进程中开启多个抓取线程,而解析过程则放到不同的进程中,提高爬虫抓取、解析的效率。另外,该模块定义了一个监视线程,在爬虫工作过程中不断监视任务状态。
除了三个目的性比较强的模块之外,该框架还定义了比较详细的debug日志规范,同时使用了其他一些Python中的技巧(比如装饰器、动态类等)。能作为Python爬虫框架的同时,也是比较好的Python入门资源。更多功能、配置、参数等,可以查看代码学习。
框架的主要目的就是为了让爬虫工程师在编写爬虫时更专注于构造合理的request、解析网页以及存储网页,而不是浪费时间在如何写工具函数、如何进行线程调度、如何进行进程通讯、如何保证线程、进程正常退出等等。没有哪个框架十全十美,也没有哪个框架完全通用,顺手、稳定才是硬道理。这个框架目前还不够完善,我还会不断思考、更新它,基本会保持在每周更新一次。大家有什么功能性建议,或者在架构上有什么其他好的想法,可以给我留言或者在github上提Issues、Pull requests等,我会积极考虑大家建议的。
下一步主要的计划是改写为分布式的爬虫,提高抓取效率。
这里贴两张测试流程中的日志输出:


=============================================================
作者主页:笑虎(Python爱好者,关注爬虫、数据分析、数据挖掘、数据可视化等)
作者专栏主页:撸代码,学知识 - 知乎专栏
作者GitHub主页:撸代码,学知识 - GitHub
欢迎大家拍砖、提意见。相互交流,共同进步!
==============================================================
