找了一下开源时序数据库,相对门槛较低的有openTSDB,还可以看源码,InfluxDB开源了单机版,集群版是闭源的。
openTSDB 是基于Hbase的,Hbase又要安装java
一:安装JDK1.8 参考教程 https://www.cnblogs.com/justuntil/p/11665540.html
1. 安装前的清理工作。如果以前安装过,给请理干净。
rpm -qa | grep jdk
rpm -qa | grep gcj
yum -y remove java-xxx-xxx
2. 在线下载JDK
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.rpm
添加执行权限:
命令:chmod +x jdk-8u131-linux-x64.rpm
执行rpm进行安装
命令:rpm -ivh jdk-8u131-linux-x64.rpm
查看JDK是否安装成功
命令:java -version
查看JDK的安装路径,(一般默认的路径:/usr/java/jdk1.8.0_131)
3. 配置JDK环境变量
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_131
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}
生效:source /etc/profile
二:安装HBase 参考https://www.cnblogs.com/h--d/p/11580398.html
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
官网地址:http://hbase.apache.org/
文档地址:http://hbase.apache.org/book.html#quickstart
1.下载HBase,可以去官网下载
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/2.2.4/hbase-2.2.4-bin.tar.gz
tar -xzvf hbase-2.2.4-bin.tar.gz
cd hbase-2.2.4
2. 由于HBase依赖JAVA_HOME环境变量,所以要导入Java环境变量,编辑conf/hbase-env.sh-文件,并取消注释以#export JAVA_HOME =开头的行,然后将其设置为Java安装路径。
cd conf
vi hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_131
3. 编辑conf/hbase-site.xml,这是主要的HBase配置文件。这时,您需要在本地文件系统上指定HBase和ZooKeeper写入数据的目录并确认一些风险。默认情况下,在/tmp下创建一个新目录。许多服务器配置为在重新引导时删除/ tmp的内容,因此您应该将数据存储在其他位置。
vi hbase-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | <!-- hbase存放数据目录 --> <property> <name>hbase.rootdir</name> <value>file:///var/www/HBase/hbase-2.2.4/hbase</value> </property> <!-- ZooKeeper数据文件路径 --> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/var/www/HBase/hbase-2.2.4/zookeeper</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> <description> Controls whether HBase will check for stream capabilities (hflush/hsync). Disable this if you intend to run on LocalFileSystem, denoted by a rootdir with the 'file://' scheme, but be mindful of the NOTE below. WARNING: Setting this to false blinds you to potential data loss and inconsistent system state in the event of process and/or node failures. If HBase is complaining of an inability to use hsync or hflush it's most likely not a false positive. </description> </property> |
4. 启动HBase
cd bin
启动
start-hbase.sh
关闭
stop-hbase.sh
使用jps命令查看master是否启动成功
为了方便也可以将hbase也加入了环境变量中,方便使用,在/etc/profile文件中,增加一下内容
vi /etc/profile
export HBASE_HOME=/var/www/HBase/hbase-2.2.4
export PATH=$HBASE_HOME/bin:$PATH
source /etc/profile
5. 浏览器访问 127.0.0.1:16010/master-status,(默认端口:16010)
三:HBase的使用
1. 在bin目录下,连接到HBase,输入hbase shell

2. 显示HBase Shell帮助文本。键入help并按Enter键,以显示HBase Shell的一些基本用法信息以及一些示例命令。注意,表名,行,列都必须用引号引起来。
3. 创建一个表,使用create命令创建一个新表。您必须指定表名称和ColumnFamily名称。 命令:create 'test', 'cf'
4. 列出有关表的信息,使用list命令确认您的表存在 命令:list 'test'
5. 使用describe命令查看详细信息,包括配置默认值 命令:describe 'test'
6. 将数据放入表中。要将数据放入表中,请使用put命令。命令:put 'test', 'row1', 'cf:a', 'value1'
7. 一次扫描表中的所有数据,从HBase获取数据的一种方法是扫描。使用scan命令扫描表中的数据。您可以限制扫描范围,但是现在,所有数据都已获取。scan 'test'
8. 获取单行数据。要一次获取一行数据 命令:get 'test', 'row1'
9. 禁用表格。如果要删除表或更改其设置,以及在某些其他情况下,则需要先使用disable命令禁用该表。您可以使用enable命令重新启用它。禁用命令:disable 'test' 启用命令:enable 'test'
10. 要删除(删除)表,使用drop命令 命令:drop 'test'
11. 退出HBase Shell。要退出HBase Shell并从群集断开连接,请使用以下quit命令。HBase仍在后台运行。命令:quit 或者exit()
四:HBase的使用 https://www.cnblogs.com/yybrhr/p/11156792.html
首先创建四个表
# 这张表数据会很大,考虑到读写效率,我们注意到这张表就一个列族
create 'tsdb',{NAME => 't', VERSIONS => 1, BLOOMFILTER => 'ROW'}
# opentsdb中建立metric name、tagK、tagV字面量与uid一一对应的表
# opentsdb不会存储实际的字符串字面值
# 比如system.cpu.util的metric,会将system.cpu.util转化为id(默认自增,后面介绍部分源码的时候会有讲到)后,存入HBase
# 这张表有id、name两个列族,可通过id找到name,也可以通过name找到id
create 'tsdb-uid',{NAME => 'id', BLOOMFILTER => 'ROW'},{NAME => 'name', BLOOMFILTER => 'ROW'}
# 下面两张表暂时可不必太关心,先创建出来就好
create 'tsdb-tree',{NAME => 't', VERSIONS => 1, BLOOMFILTER => 'ROW'}
create 'tsdb-meta',{NAME => 'name', BLOOMFILTER => 'ROW'}
# 备份表:tsdb,本地存放路径/opt/soft/hbase/hbase_bak/hbase_bak_1562252298
hbase org.apache.hadoop.hbase.mapreduce.Export -Dhbase.export.scanner.batch=2000 -D mapred.output.compress=true tsdb file:///opt/soft/hbase/hbase_bak/hbase_bak_1562252298
五:OpenTSDB介绍 参考:https://www.jianshu.com/p/14a6f2dbff50
安装包下载地址:https://github.com/OpenTSDB/opentsdb/releases
再安利一下。
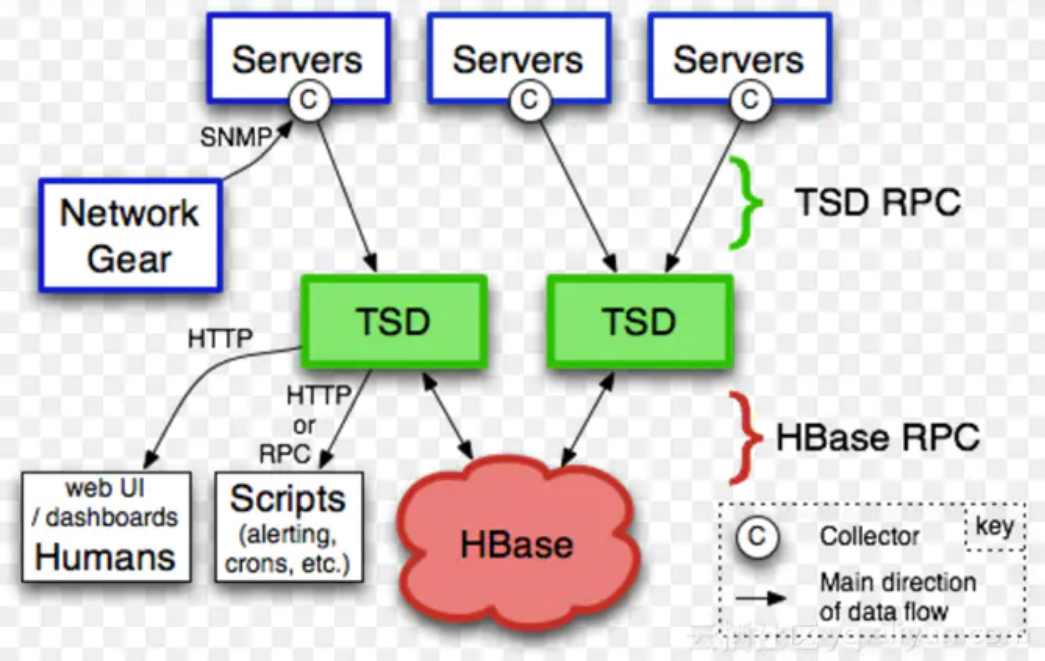
如图是OpenTSDB的架构,核心组成部分就是TSD和HBase。TSD是一组无状态的节点,可以任意的扩展,除了依赖HBase外没有其他的依赖。
TSD对外暴露HTTP和Telnet的接口,支持数据的写入和查询。TSD本身的部署和运维是很简单的,得益于它无状态的设计,
不过HBase的运维就没那么简单了,这也是扩展支持BigTable和Cassandra的原因之一吧。
1. 数据模型
OpenTSDB采用按指标建模的方式,一个数据点会包含以下组成部分:
1. metric:时序数据指标的名称,例如sys.cpu.user,stock.quote等。(类似于table表名吧)
2. timestamp:秒级或毫秒级的Unix时间戳,代表该时间点的具体时间。
3. tags:一个或多个标签,也就是描述主体的不同的维度。Tag由TagKey和TagValue组成,TagKey就是维度,TagValue就是该维度的值。
4. value:该指标的值,目前只支持数值类型的值。
OpenTSDB底层存储的优化思想,简单总结就是以下这几个关键的优化思路:
1. 对数据的优化:为Metric、TagKey和TagValue分配UniqueID,建立原始值与UniqueID的索引,数据表存储Metric、TagKey和TagValue对应的UniqueID而不是原始值。
2. 对KeyValue数的优化:如果对HBase底层存储模型十分了解的话,就知道行中的每一列在存储时对应一个KeyValue,减少行数和列数,能极大的节省存储空间以及提升查询效率。
3. 对查询的优化:利用HBase的Server Side Filter来优化多维查询,利用Pre-aggregation和Rollup来优化GroupBy和降精度查询。
3. UIDTable
接下来看一下OpenTSDB在HBase上的几个关键的表结构的设计,首先是tsdb-uid表,结构如下:

Metric、TagKey和TagValue都会被分配一个相同的固定长度的UniqueID,默认是三个字节。tsdb-uid表使用两个ColumnFamily,
存储了Metric、TagKey和TagValue与UniqueID的映射和反向映射,总共是6个Map的数据。
从图中的例子可以解读出:
1. TagKey为'host',对应的UniqueID为'001'
2. TagValue为'static',对应的UniqueId为'001'
3. Metric为'proc.loadavg.1m',对应的UniqueID为'052'
为每一个Metric、TagKey和TagValue都分配UniqueID的好处,一是大大降低了存储空间和传输数据量,每个值都只需要3个字节就可以表示,这个压缩率是很客观的;二是采用固定长度的字节,可以很方便的从row key中解析出所需要的值,并且能够大大减少Java堆内的内存占用(bytes相比String能节省很多的内存占用),降低GC的压力。
不过采用固定字节的UID编码后,对于UID的个数是有上限要求的,3个字节多只允许有16777216个不同的值,不过在大部分场景下都是够用的。当然这个长度是可以调整的,不过不支持动态更改。
4. DataTable
第二张关键的表是数据表,结构如下:

该表中,同一个小时内的数据会存储在同一行,行中的每一列代表一个数据点。如果是秒级精度,那一行多会有3600个点,如果是毫秒级精度,那一行多会有3600000个点。
这张表设计的精妙之处在于row key和qualifier(列名)的设计,以及对整行数据的compaction策略。row key格式为:

其中metric、tagk和tagv都是用uid来表示,由于uid固定字节长度的特性,所以在解析row key的时候,可以很方便的通过字节偏移来提取对应的值。Qualifier的取值为数据点的时间戳在这个小时的时间偏差,例如如果你是秒级精度数据,第30秒的数据对应的时间偏差就是30,所以列名取值就是30。列名采用时间偏差值的好处,主要在于能大大节省存储空间,秒级精度的数据只要占用2个字节,毫秒精度的数据只要占用4个字节,而若存储完整时间戳则要6个字节。整行数据写入后,OpenTSDB还会采取compaction的策略,将一行内的所有列合并成一列,这样做的主要目的是减少KeyValue数目。
5. 查询优化
HBase仅提供简单的查询操作,包括单行查询和范围查询。单行查询必须提供完整的RowKey,范围查询必须提供RowKey的范围,扫描获得该范围下的所有数据。通常来说,单行查询的速度是很快的,而范围查询则是取决于扫描范围的大小,扫描个几千几万行问题不大,但是若扫描个十万上百万行,那读取的延迟就会高很多。
OpenTSDB提供丰富的查询功能,支持任意TagKey上的过滤,支持GroupBy以及降精度。TagKey的过滤属于查询的一部分,GroupBy和降精度属于对查询后的结果的计算部分。在查询条件中,主要的参数会包括:metric名称、tag key过滤条件以及时间范围。
我们具体看一下OpenTSDB对查询的优化措施:
1. Server side filter
HBase提供了丰富和可扩展的filter,filter的工作原理是在server端扫描得到数据后,先经过filter的过滤后再将结果返回给客户端。Server side filter的优化策略无法减少扫描的数据量,但是可以大大减少传输的数据量。OpenTSDB会将某些条件的tag key filter转换为底层HBase的server side filter,不过该优化带来的效果有限,因为影响查询关键的因素还是底层范围扫描的效率而不是传输的效率。
2. 减少范围查询内扫描的数据量
要想真正提高查询效率,还是得从根本上减少范围扫描的数据量。注意这里不是减小查询的范围,而是减少该范围内扫描的数据量。这里用到了HBase一个很关键的filter,即FuzzyRowFilter,FuzzyRowFilter能够根据指定的条件,在执行范围扫描时,动态的跳过一定数据量。但不是所有OpenTSDB提供的查询条件都能够应用该优化,需要符合一定的条件,具体要符合哪些条件就不在这里说明了,有兴趣的可以去了解下FuzzyRowFilter的原理。
3. 范围查询优化成单行查询
这个优化相比上一条,更加的极端。优化思路非常好理解,如果我能够知道要查询的所有数据对应的row key,那就不需要范围扫描了,而是单行查询就行了。这里也不是所有OpenTSDB提供的查询条件都能够应用该优化,同样需要符合一定的条件。单行查询要求给定确定的row key,而数据表中row key的组成部分包括metric名称、timestamp以及tags,metric名称和timestamp是能够确定的,如果tags也能够确定,那我们就能拼出完整的row key。所以很简单,如果要能够应用此优化,你必须提供所有tag key对应的tag value才行。
以上就是OpenTSDB对HBase查询的一些优化措施,但是除了查询,对查询后的数据还需要进行GroupBy和降精度。GroupBy和降精度的计算开销也是非常可观的,取决于查询后的结果的数量级。对GroupBy和降精度的计算的优化,几乎所有的时序数据库都采用了同样的优化措施,那就是pre-aggregation和auto-rollup。思路就是预先进行计算,而不是查询后计算。不过OpenTSDB在已发布的新版本中,还未支持pre-aggregation和rollup。而在开发中的2.4版本中,也只提供了半吊子的方案,它只提供了一个新的接口支持将pre-aggregation和rollup的结果进行写入,但是对数据的pre-aggregation和rollup的计算还需要用户自己在外层实现.
6. 总结:
OpenTSDB的优势在于数据的写入和存储能力,得益于底层依赖的HBase所提供的能力。劣势在于数据查询和分析的能力上的不足,虽然在查询上已经做了很多的优化,但是不是所有的查询场景都能适用。可以说,OpenTSDB在TagValue过滤查询优化,是这次要对比的几个时序数据库中,优化的差的。在GroupBy和Downsampling的查询上,也未提供Pre-aggregation和Auto-rollup的支持。不过在功能丰富程度上,OpenTSDB的API是支持丰富的,这也让OpenTSDB的API成为了一个标杆。
systemctl status/start/stop/restart opentsdb来查看控制1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | [Unit]Description=OpenTSDB Service[Service]Type=forkingPrivateTmp=yesExecStart=/usr/share/opentsdb/etc/init.d/opentsdb startExecStop=/usr/share/opentsdb/etc/init.d/opentsdb stopRestart=on-abort |
systemctl status opentsdb 发现还没启动,dead状态,
注意一下,默认opentsdb配置文件目录:/etc/opentsdb/opentsdb.conf,默认opentsdb日志目录:/var/log/opentsdb
修改配置 /etc/opentsdb/opentsdb.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | tsd.network.port = 4242tsd.http.staticroot = /usr/share/opentsdb/static/tsd.http.cachedir = /tmp/opentsdbtsd.core.auto_create_metrics = truetsd.core.plugin_path = /usr/share/opentsdb/plugins# zookeeper的地址,即hbase依赖的zookeeper的地址,192.168.0.1:2181,192.168.0.2:2181,192.168.0.3:2181tsd.storage.hbase.zk_quorum = localhost:2181tsd.storage.fix_duplicates = truetsd.http.request.enable_chunked = truetsd.http.request.max_chunk = 4096000tsd.storage.max_tags = 16# 这里看到了我们上面在hbase中创建的4张表tsd.storage.hbase.data_table = tsdbtsd.storage.hbase.uid_table = tsdb-uidtsd.storage.hbase.tree_table = tsdb-treetsd.storage.hbase.meta_table = tsdb-meta# 下面几个配置项到部分源码解析的时候会有介绍,暂时可以先忽略# tsd.query.skip_unresolved_tagvs = true# hbase.rpc.timeout = 120000 |
启动opentsdb,systemctl start opentsdb,成功的话,就可以打开opentsdb的界面了http://localhost:4242/