按照重要程度来说,也许我应该讲一下Snowflake如何做数据分发和共享。但是,在写这部分前,我需要自己真正上传一些数据到Snowflake中,这样才能去体验如何共享数据。
那本文我们先真正上传并分析一些数据吧。
我们知道,随着JSON的流行,半结构化(Semi-Structured)数据对于数据分析也越来越重要,那我们就先来看看Snowflake对于半结构化数据的处理吧。
场景
近恰好了解了一下“易观第四届OLAP算法大赛”(在 Apache DolphinScheduler 社区中熟识了好几位来自易观的朋友),参见
本次大赛的主题是:“事件分析”。“事件分析”功能的使用频次极高。事件分析模型主要用于分析用户打开 APP、注册、支付订单等在应用上的行为,通过触发用户数、触发次数等基础指标度量用户行为,也支持指标运算、构建复杂的指标衡量业务过程。
一共有三道测试题,让我们来分别用Snowflake解决:
- 场景1:多指标多维度分析;
- 场景2:多指标多维度分析,并计算任意维度小计、合计值;
- 场景3:多指标多维度分析,计算任意维度小计、合计值,并支持关联用户属性数据。
了解数据
首先,我们先看看测试数据是什么样子的。
测试数据解压后,一共两个文本文件,分别为:
- olap_2020_profile_test.dat: 用户 profile 数据, 大小为: 161M
- olap_2020_event_test.dat: event数据,大小为: 3G
对于profile数据,其有2列:
- 1、用户ID(distinct_id),Long类型 与event表的对应
- 2、内容明细,json格式,其内容类似于
{
"age": 39,
"fq15": 1,
"fq16": 1,
"fq17": 1,
"fq2": 1,
"fq5": 1,
"fq6": 1,
"total_amount": 10019.16,
"total_visit_days": 184
}对于event数据,其有6列:
- 1、用户ID(distinct_id),Long类型
- 2、时间戳(xwhen),毫秒级别UNIXTIME,Long类型
- 3、事件CODE(xwhat),字符串类型,包含startUp、login、searchGoods等多个事件
- 4、事件ID(xwhat_id) ,与事件code一一对应,Int类型。
- 5、日期(ds),事件发生的日期YYYYMMDD格式
- 6、内容明细,json格式。不同事件、记录包含不同属性,包含字符串、浮点、整形3种类型的数据。总属性个数 30-50个左右,其内容类似于
{
"app_version": "V1.2",
"city": "杭州",
"commodityname": "大闸蟹",
"commoditynumber": 34,
"country": "中国",
"firstcommodity": "生鲜",
"os": "Android",
"os_version": "Android 6.0.1",
"price": 755,
"province": "浙江",
"secondcommodity": "海鲜速食"
}上传数据
接下来我们需要把数据从本地导入到Snowflake中。也许我们反应是写个Java程序来解析文本文件(TSV格式),然后通过JDBC批量插入到Snowflake中。
但是,我们知道,当导入大量数据时,JDBC、ODBC往往是慢的方法。数据库一般都有更快速的批量加载CSV文件的功能。让我们使用这个功能吧。
Snowflake有多种使用方式:
- Web Interface: 前文中用的就是Web上的界面
- SnowSQL: 命令行工具
- Connectors & Drivers: 面向开发的一些连接器
- Snowflake Connector for Python
- Snowflake Connector for Spark
- Snowflake Connector for Kafka
- Node.js Driver
- Go Snowflake Driver
- .NET Driver
- JDBC Driver
- ODBC Driver
今天我们来使用其命令行工具 SnowSQL 来操作。用过一些SQL命令行工具的朋友肯定对SnowSQL不会陌生。不过一个细节是SnowSQL居然在命令行里也做了“自动补全”的功能(如下图):
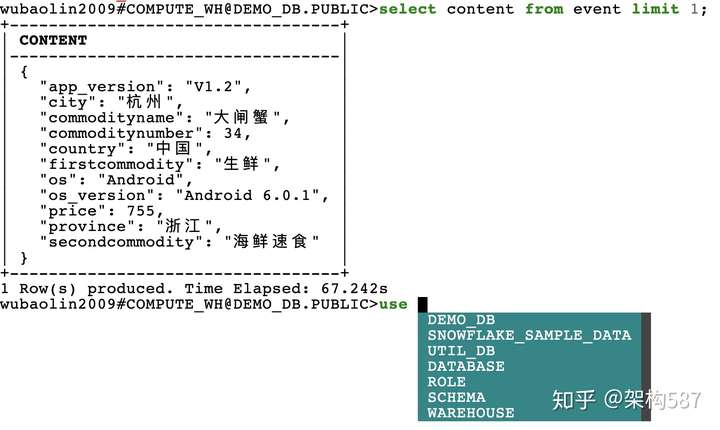
首先,我们把profile文本上传到 Snowflake 的Stage区 (Snowflake中,我们可以使用Snowflake内置的Stage区,也可以挂载外部的Amazon S3等对象存储)
put file:///Users/wubaoqi/Downloads/olap_2020_test/olap_2020_profile_test.dat @~/mytest;返回了结果信息:
- source: olap_2020_profile_test.dat
- target: olap_2020_profile_test.dat.gz
- source_size: 168441847
- target_size: 18826148
- target_compression: GZIP
- status: UPLOADED
可以看出Snowflake对我们上传的文本文件,先做了GZIP压缩后再存储。
第二步,创建Snowflake中的表
create table profile (
distinct_id BIGINT,
content OBJECT
)这里注意,Snowflake中支持3种类型的半结构化数据,其类型分别是:
- VARIANT
- OBJECT
- ARRAY
VARIANT可以存储其它数据类型,包含OBJECT或ARRAY本身,只要其大小压缩后小于16MB就可以。OBJECT和ARRAY是VARIANT的一种特例,类似于JSON中的对象和数组。而且VARIANT、OBJECT、ARRAY都支持嵌套。所以,其表达能力是很强的。
关于半结构化的数据类型,详细可以参考: https://docs.snowflake.com/en/sql-reference/>
第三步,把数据从Stage存储中加载到表格中。
copy into profile from @~/mytest/olap_2020_profile_test.dat file_format = (type=csv, FIELD_DELIMITER='\t');得到了:629,612 行数据,耗时63秒(注意:这里使用了Snowflake小的计算VW,所以会慢些)
同样的过程,我们导入 event 表, 得到 12,444,499 行数据,耗时 173 秒
场景1:多指标多维度分析
题目: 查询20200701-20200707 的行为数据,按ds进行分组统计uv、pv,并计算合计值。
这个不需要读取json中的内容,所以比较简单:
select ds,
count(distinct distinct_id) as uv,
count(distinct_id) as pv
from event
where ds between '20200701' and '20200707'
group by grouping sets ((), ds)
order by ds asc获得结果 (8 Rows produced. Time Elapsed: 3.056s), 注: NULL值代表该行为小计或总计
场景2:多指标多维度分析,并计算任意维度小计、合计值
题目: 查询20200701-20200707 的行为数据,按ds +os+os_version 进行分组统计uv,pv ,并计算总计以及os的小计值与合计值。
这个只涉及 event 表中的OBJECT字段。
select content:os::string as os,
content:os_version::string as os_version,
ds,
count(distinct distinct_id) as uv,
count(distinct_id) as pv
from event
where ds between '20200701' and '20200707'
group by grouping sets (
(content:os::string, content:os_version::string, ds),
(content:os::string, ds),
content:os::string,
()
)
order by os asc, os_version asc, ds asc获得结果 (45 Rows produced. Time Elapsed: 4.190s), 注: NULL值代表该行为小计或总计
这里可以得知,Snowflake中,如果想取出OBJECT类型中的某个值,可以用“:”这个操作符,比如 “content:os” 获取OBJECT的key为os的值。 注意这里返回的仍然是一个类似 JsValue 的值,如果我们需要转化为字符串类型,我们可以写为: content:os::string
场景3:多指标多维度分析,计算任意维度小计、合计值,并支持关联用户属性数据
题目: 计算20200701-20200707行为数据中事件=’addtoshoppingcart’.按 ds+用户表的lib进行分组统计UV以及price的汇总值。
select profile.content:lib::STRING as lib,
event.ds,
count(distinct event.distinct_id) as uv,
sum(event.content:price::NUMBER(35, 3)) as "sum(price)"
from event left outer join profile
on event.distinct_id = profile.distinct_id
where ds between '20200701' and '20200707' and event.xwhat='addtoshoppingcart'
group by 1,2
order by lib asc nulls first, ds asc这里稍微复杂的有了一个JOIN语句,得到结果:(42 Rows produced. Time Elapsed: 2.041s), 注: NULL值代表该行为小计或总计
场景小结
至此,顺利完成该场景的测试验证。整个过程还是比较快和方便的,而且使用Snowflake来处理JSON确实挺方便的(后面会比较和Spark的JSON处理区别)
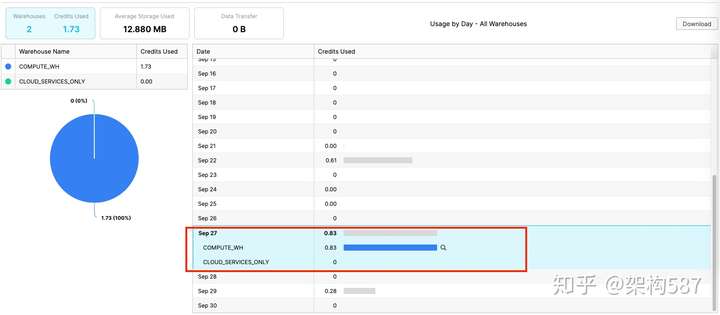
然后,还是看看Snowflake的账单情况 (用了 0.83 credit)
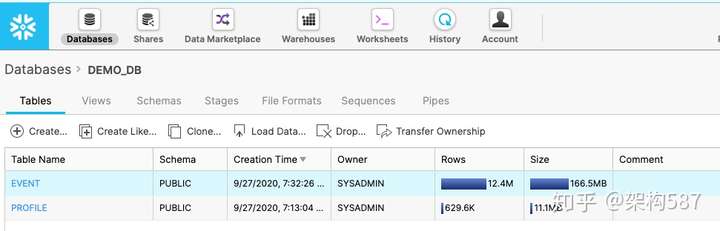
然后看一下这两个表的存储空间使用 (共占用了177MB,看来是算的压缩后的占用空间)
对比Apache Spark的JSON相关语法
对于JSON数据的处理,我们看到当Snowflake加载CSV时,我们可以直接设置目标列为 OBJECT 类型,然后就可以使用类似于: content:os::string 的方式来获取值了。
对于Spark来说,一般我们都是把JSON数据存为 STRING 类型。然后,我们可以使用 GET_JSON_OBJECT() 函数来获取
对于event表中的json:
{
"app_version": "V1.2",
"city": "杭州",
"commodityname": "大闸蟹",
"commoditynumber": 34,
"country": "中国",
"firstcommodity": "生鲜",
"os": "Android",
"os_version": "Android 6.0.1",
"price": 755,
"province": "浙江",
"secondcommodity": "海鲜速食"
}
我们可以用
SELECT GET_JSON_OBJECT(content, '$.os') AS `os`
FROM event可以看到:我们需要用类似 JSON Path的语法来定位到对应元素, 另外,这里看着不需要额外加入 CAST AS STRING 语句, 是因为这个函数返回的内容都变为String了,当我们要获取price这个数值时,我们则需要额外的CAST
SELECT GET_JSON_OBJECT(content, '$.os') AS `os`,
CAST(GET_JSON_OBJECT(content, '$.price') AS LONG) AS `price`
FROM event也许你会说, Snowflake加载CSV时,指定了 OBJECT 类型,而不是先存为STRING。 那我们看看SPARK是否能同样的把STRING存为 MAP 等类型?
首先尝试:
SELECT CAST(content AS MAP) AS content
FROM event报错: DataType map is not supported. 发现,我们需要明确指定 MAP的具体key 和 value的类型。
尝试二:
SELECT CAST(content AS MAP<STRING, STRING>) AS content
FROM event报错: cannot resolve `content`' due to data type mismatch: cannot cast string to map<string,string>。 哦,原来我的数据里,有的value是数值类型,不全是STRING类型,导致错误。而Spark中并没有一种类型能直接同时代表 INT 和 STRING。
换个思路,如果我们不能用MAP,是否可以用STRUCT 这种自定义类型? 但是我又不知道该把这个JSON写为啥 STRUCT 结构。幸好,spark 2.4以后的版本加入了: SCHEMA_OF_JSON 这个函数来获取该列可能的数据结构。
SELECT SCHEMA_OF_JSON(content) AS content
FROM event仍然出错,报错误:
cannot resolve 'schemaofjson(`content`)' due to data type mismatch: The input json should be a string literal and not null; however, got `content`.
这个错误有点费解,后来终于明白, SCHEMA_OF_JSON 这个函数的参数只能是STRING常量,不能是STRING类型的列。
SELECT schema_of_Json('{"app_version": "V1.2", "city": "杭州", "commodityname": "大闸蟹", "commoditynumber": 34, "country": "中国", "firstcommodity": "生鲜", "os": "Android", "os_version": "Android 6.0.1", "price": 755, "province": "浙江", "secondcommodity": "海鲜速食"}')
FROM eventOK,终,得到了这个JSON String对应的Schema应该为:
struct<
app_version:string,
city:string,
commodityname:string,
commoditynumber:bigint,
country:string,
firstcommodity:string,
os:string,
os_version:string,
price:bigint,
province:string,
secondcommodity:string
>哇,不容易。那接下来我们终于可以像Snowflake那样来访问数据了(直接把content由STRING CAST 为这个复杂的STRUCT是无法成功的,这里用了一个 Spark的专用函数 FROM_JSON)。
SELECT content.os, content.price
FROM (
SELECT FROM_JSON(content, 'struct<app_version:string,city:string,commodityname:string,commoditynumber:bigint,country:string,firstcommodity:string,os:string,os_version:string,price:bigint,province:string,secondcommodity:string>') as content
FROM event
)终,我们终于把JSON转为了Spark中的Struct,然后终于可以像Snowflake那么来方便操作半结构数据了。但是整个过程却总有人有一种:从入门到放弃的感觉。
Snowflake自动索引半结构化数据,加速查询速度
上面,我们只是说了Snowflake对于半结构化数据处理的语法非常方便。但是光语法方便并不能说其是 JSON Native 的。因为我们也可以通过一些辅助程序,把这种语法转为通过上面SPARK/Hive等的 GET_JSON_OBJECT来实现。但是调用这么多 GET_JSON_OBJECT,以及冗余的类型转化,对于性能影响巨大,所以,不能期望SPARK中的 GET_JSON_OBJECT 能有多快。
而对于Snowflake,其理念是:为客户省心。这意味着,尽可能的让客户少操心一些细节。所以,Snowflake中是不会让客户手工指定主键,也不会需要手工建立索引的。但是这些索引又是使得终查询更快的关键。那怎么办呢? Snowflake自动替客户建立合适的索引,对于半结构化数据也不例外。
对于这些实现细节,我们可以参考一下Snowflake的论文《The Snowflake Elastic Data Warehouse》: http://pages.cs.wisc.edu/~yxy/cs839-s20/papers/snowflake.pdf
文中有介绍其对于半结构化数据的支持:
存取部分,利用内部存储格式使得从 VARIANT(以及OBJECT、ARRAY)中存取数据都非常高效,
- 无需额外的复制
- A child element is just a pointer inside the parent element
- Extraction is often followed by a cast of the resulting VARIANT value to a standard SQL type。 同时,其内部存储格式也使得这些类型转化非常高效
Snowflake在存储Variant数据时,会大量利用算法来统计Variant数据中的模式信息,并利用历史查询记录,推算出该Variant列中,哪些访问路径是常见的,把这些列单独存为物理列(列式存储),而当查询的时候,则再把这些列合并到VARIANT中。
值得借鉴的是其测试方法: Snowflake为了测试其对半结构化数据的自动类型推导和自动索引是有效的,其对于TPC-H同样的测试数据集做了两个不同的存储实验: 一种是各个列都存为原始的数据类型,另一种是把所有的列组装成一个 VARIANT(OBJECT) 类型,然后测试其性能区别。 据论文数据,大多数查询的性能区别都小于 10% ! Very Impressive!
总结
半结构数据(比如JSON)等越来越流行,也越来越重要,而对于JSON类型的数据分析,我们能做些什么?
当我们使用Spark中的GET_JSON_OBJECT来处理JSON数据时,其实我们也没有觉得有啥不妥。但是,没有对比就没有伤害。我们要时常多了解一下业界是否有更好的处理方式。
在细节方面,我们不能只是一味问客户:您需要什么? 而也要向Snowflake学习,更多的问自己:如果我们的目标就是更好为客户服务,我们能为客户做些什么?
来源 https://zhuanlan.zhihu.com/p/260686089
