前言
相比于PostgreSQL,后来了解MySQL(InnoDB),在个人直观感觉上,除了细节上的不同,整体理解起来坡度不大。
而了解RocksDB,由于LSM-tree与b-tree 的不同,很多理念都可以说是换了一种认知方式。就比如说 b-tree 里的常说的BufferPool,一开始直观上理解,RocksDB觉得对应的是Block Cache;但是Block Cache只是针对读的优化,而硬要说RocksDB的BufferPool是什么,觉得应该是WriteBufferManager。
不过纠结这些概念上的对应关系也没什么意义,从使用者的角度,RocksDB也是Transactional Storage Manager;因此,也可以划分为四类子模块,但是具体实现就不像同为Btree的PgSQL和MySQL那样的了。
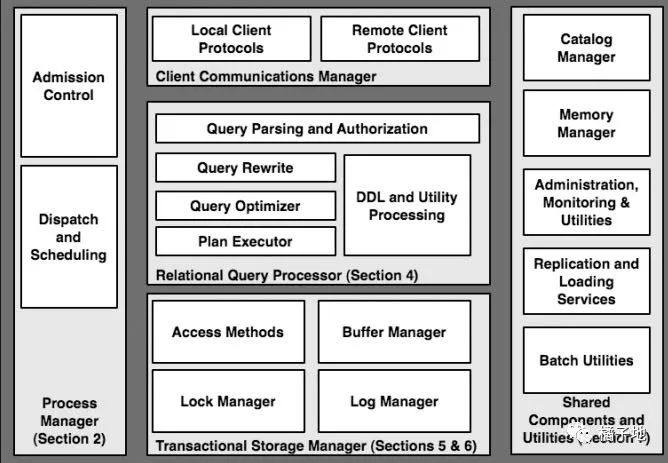 Architecture of a Database System
Architecture of a Database System
几个切入点
在读代码的时候,习惯随手画点概念图,也不是专业的UML,毕竟图片的记忆效率高
这里有几个笔者觉得适合作为一开始了解RocksDB的切入点:
1. RocksDB不是page-oriented,没有表空间的概念。其数据组织在很多Sorted String Table中,由Version来管理。
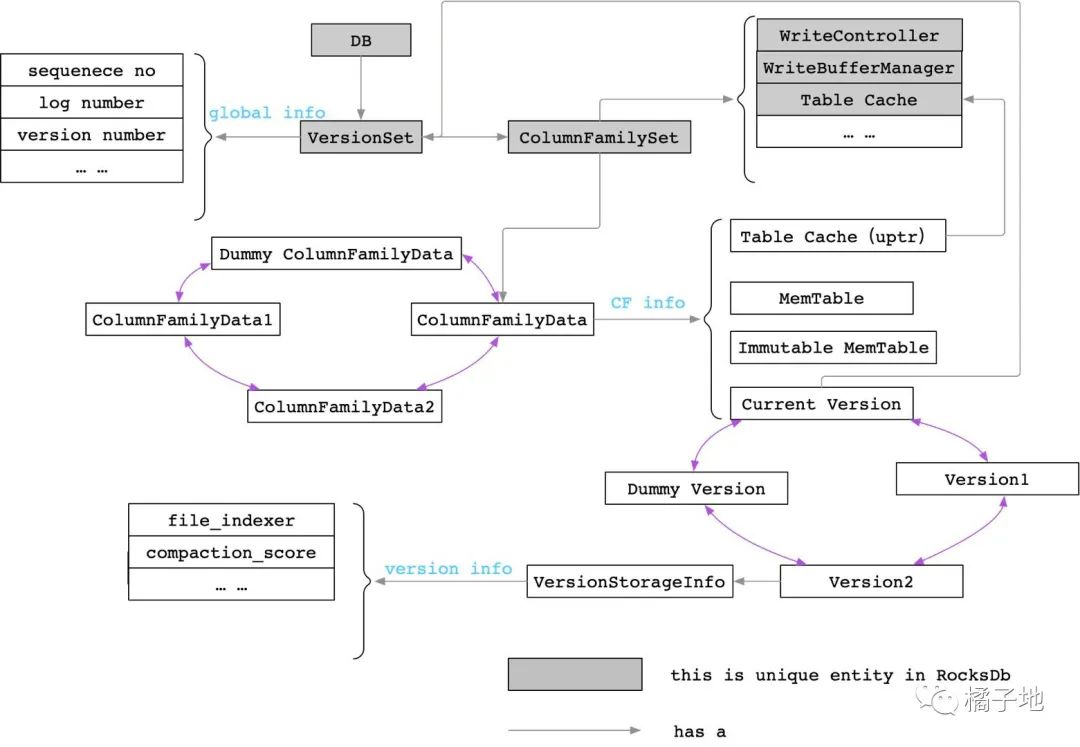 versions
versions
2. 同样是有WAL,page-oriented类的InnoDB存储的是physiological 的 page 变更,而RocksDB中直接到的是WriteBatch。
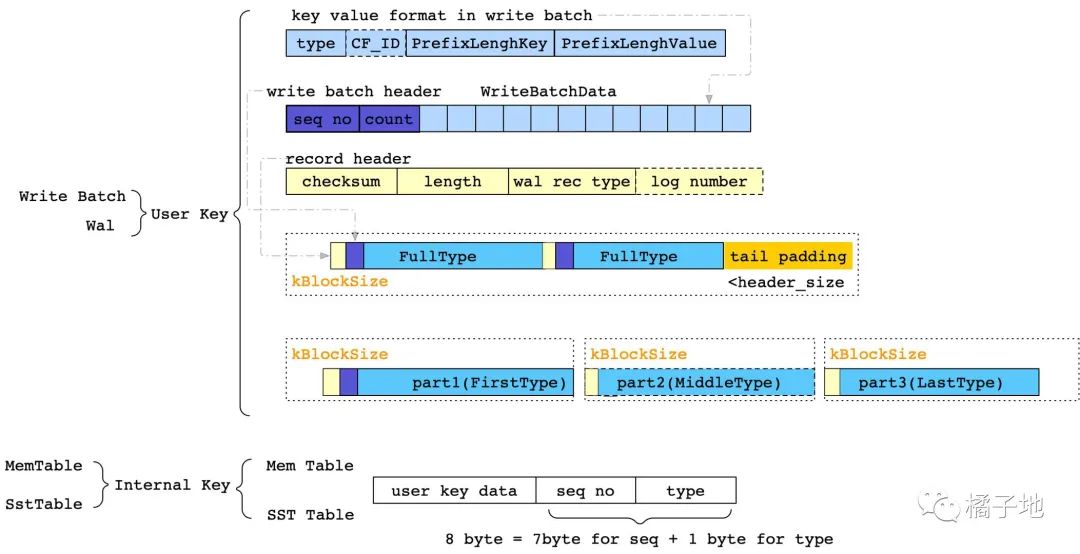 RocksDB WAL Internal
RocksDB WAL Internal
3. 上面提到写入RocksDB WAL的Write Batch,在写入MenTable时会按Column Family 分别写入。
 RocksDB write-batch & memtable
RocksDB write-batch & memtable
4. RocksDB的sequence number就是其中KV的版本号,按上图所示,如果MemTable中只放已提交的数据,那么可见性判断就很好做,这也是默认的做法。但是为了提高性能,希望在2PC的prepare阶段就可以些MemTable,这就是Write Prepared的策略;但是需要解决可见性的问题,就通过如下图的这些结构维护。
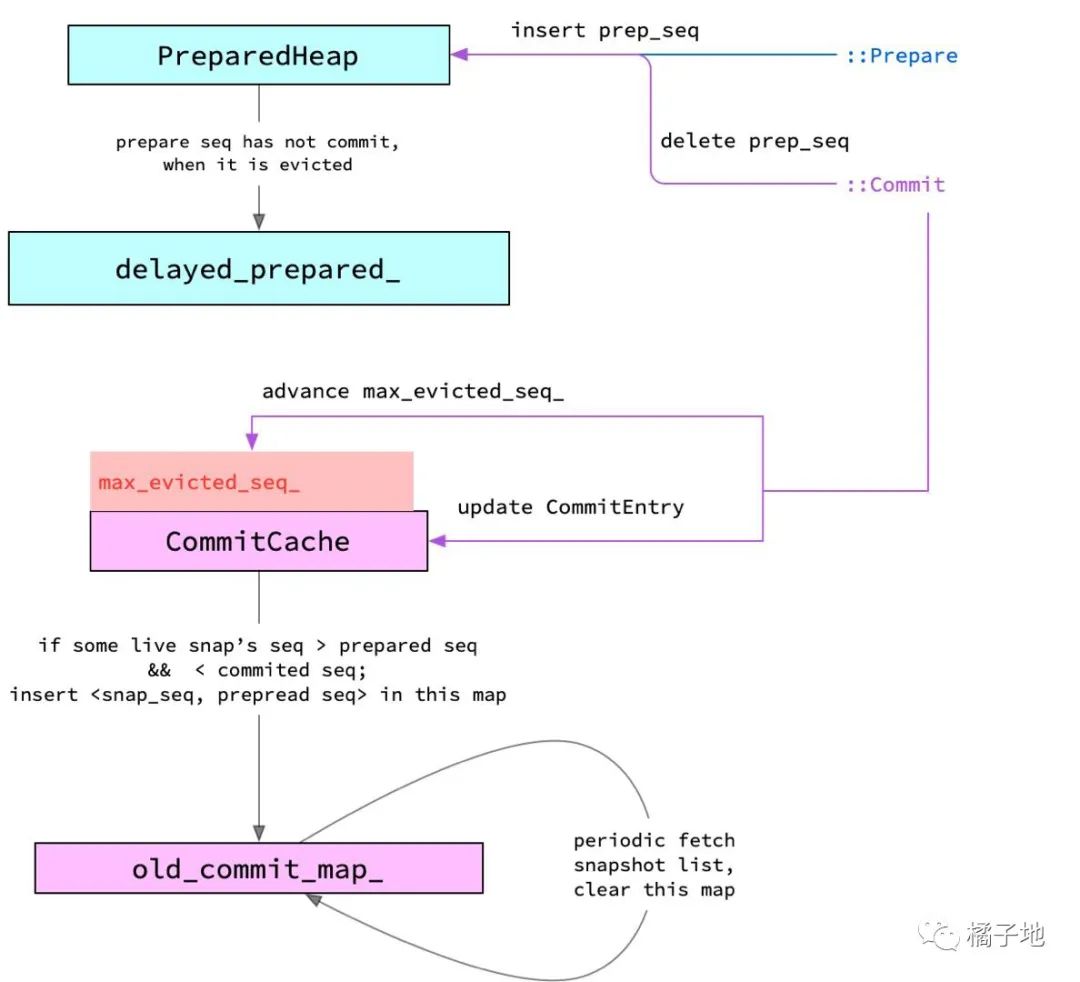 PessimisticTransactionDB Write Prepared
PessimisticTransactionDB Write Prepared
---
总之,看RocksDB代码给我的感觉就是焕然一新,除了LSM-tree之外,还有modern C++,之前看的PgSQL是C写的,MySQL(InnoDB)是C++98,这又来了11 甚至 14,后面还有20,妈的,学不动了,C++真是让人头秃啊🤮……
来源 https://www.modb.pro/db/58325
