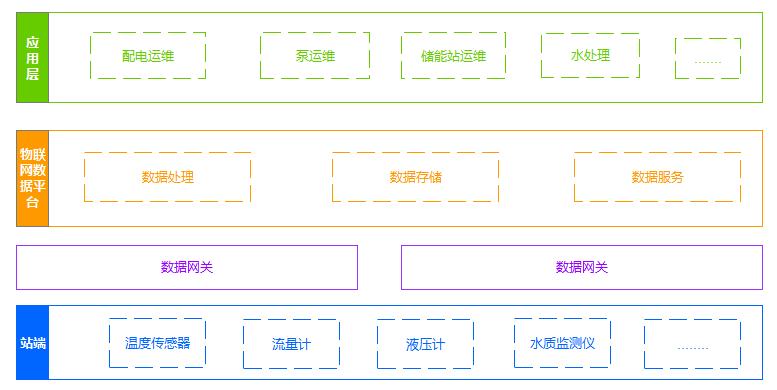
物联网数据平台是电站及泵站智慧运维平台的核心组成,其整体架构如下:物联网数据平台的数据来源主要为电站、水厂、储能站,通过数据网关,将各场站端的设备运行数据传输至云平台的消息队列(MQ)中,数据处理服务订阅MQ的消息,根据设定的规则引擎,进行实时数据处理,之后将数据存储落盘。数据服务API则根据业务需求提供包含实时数据和历史数据在内的数据API。对于历史数据,目前我们采用的MySQL分库分表方案来存储;实时数据会存储在Redis中。在测点数较少或者集控需求不是很多的场景下,基本满足需求。历史数据
历史数据用MySQL存储,一个站点对应一个数据库;一个测点对应一张表,建表语句大致如下:CREATE TABLE `yc_测点id` (
`ts` datetime NOT NULL,
`val` double NOT NULL
);
实时数据
实时数据缓存到Redis中,以测点Id为key,同时缓存数据上报的时间、测量值和质量值等信息。数据计算查询
我们利用MySQL的各种函数、多表连接、应用程序内存计算等方式,计算出结果返回给前端,对于月、年等报表类的计算,则采用定时任务生成。痛点
随着平台业务的发展,接入的站点越来越多,或者单站的测点数越来越多,问题逐渐凸显出来了。具体可以归纳为如下几个方面:
运维难
开发难
随着平台的业务发展,越来越多的站被接入平台,集控需求(跨站聚合分析需求)增加,跨库跨表的查询操作越来越多,这就增加了系统开发的难度,严重影响了系统响应速度和稳定性。成本高
成本主要有两个方面,一个是人力成本高,由于开发、运维的难度增加,造成员工工作量增加,工作效率变低,从企业经营角度看,人力成本变高;另一个是硬件资源成本高,由于服务节点众多,占用的主机、内存和磁盘空间也会很多,购买或租用这些硬件资源需要支出更多费用。二、技术选型
为了解决目前这些问题,我们决定重新进行技术选型,寻找替代方案,升级目前数据库存储方案。结合平台实际需要,我们确定了几个选型要求:- 开源免费:必须是开源的,并且允许免费商用,好也有商业版;
- 开销低:服务节点少,占用的内存、CPU和磁盘空间少;
- 安装维护简单: 数据量较小的情况下,支持单机部署,并且占用资源较少;
我们了解了多款典型的时序数据库产品,终InfluxDB、庚顿、麦杰、TimescaleDB、TDengine这几款进入了我们的考察范围。下面我们来具体看一下:
在开源时序数据库领域长期霸榜,社区活跃,生态也比较丰富,性能也算中规中距,的缺陷就是集群模块不开源。
两者都是传统老牌工业领域的时序数据库,功能、性能都非常不错,的缺点就是不开源,只有商业版,而且价格昂贵。
它是在PostgreSQL之上开发的一个插件,是基于关系数据库的时序数据库,对于我们现有的业务使用几乎无感知,上层可以继续用MyBatis、JPA等ORM框架,但它不是一个纯粹的时序数据库;另外,它对集群支持不好,不支持水平扩展。
支持使用类SQL查询语言来插入或查询数据,内嵌消息队列和缓存机制、无历史数据与实时数据之分、分布式架构,支持线性扩展、支持多副本,无单点故障。看到官网的这些介绍,瞬间感觉TDengine就是为我们准备的,于是马上做了各种验证,结果表明,TDengine完全符号我们的选型要求。为什么没有采用传统Hadoop生态
提到大数据,人们可能反应就会想到Hadopp生态。因此我们前期也考查过腾讯云的TBDS数据套件。说实话那一套东西真的是太笨重了,Hadoop、HBase、HDFS、ZooKeeper、Hive、Spark\Flink这系列的东西搞下来,还真不是一般团队能玩得转的,另外我司的业务场景不止云端服务,还有可能会私有化部署在站内,硬件条件可能也就是一两台状况一般的服务器。三、TDengine存储模型设计
由于TDengine可以设置将新一条数据存储在内存中,因此我们利用这个特性替换掉了用Redis存储实时数据这个环节,改成实时数据直接查询TDengine。TDengine里有超级表的概念,每种设备对应一个超级表。这个超级表只负责存储这种类型的设备数据,数据存储采用横表存储。但是,这显然不符合我们的场景,因为在我们的场景里没有固定的某一设备对象,且每个测点的频率都可能不一致。同时为了尽可能减少对现有业务的影响,我们将超表设计成如下结构:CREATE STABLE IF NOT EXISTS stb_站点id ( ts timestamp, val double ) TAGS (测id nchar(64))
TDengine的子表,可以在插入数据时动态创建,这是TDengine的一个很好用的功能。这样能省去创建子表的业务环节,降低了业务复杂度。子表结构如下:insert into 测点类型_测点id USING stb_站点id (测点id) VALUES ( ts, val,q) eg: insert into yc_15143115161750995367 USING stb_站点id ('15143115161750995367') VALUES ( ts, val,q)
四、使用到的TDengine特性
缓存(Cache)
我们直接使用TDengine提供的缓存(Cache)功能,替换了原有系统中的Redis。创建数据库直接开启cachelast=1,将每张表的后一条记录缓存,应用程序通过last_row函数快速获取实时数据。数据订阅(Publisher/Subscriber)
在我们的业务场景中有一类数据叫SOE事件告警数据,这类数据要实时动态在前端页面上滚动。原有做法是通过页面轮训来实现的,现在直接使用taos的数据订阅功能,配合WebSocket,可以优雅地实现这一功能,大大提升了用户体验。其它一些很用的功能
五、改造迁移
由于TDengine采用了类SQL的语法,支持MyBatis等ORM框架,因此对于老的业务,我们在代码层面的改动非常少,改动多的就是将原来的MySQL函数结合应用代码的一些计算逻辑直接用TDengine的函数替换掉。在试运行阶段,因为我们都是通过自研数据网关将数据通过TCP发送上来的,所以我们利用tcp-copy,将数据复制一份存到TDengine集群,然后通过业务系统观察和验证各项功能是否正常。验证正常之后,就是历史数据的迁移了。由于TDengine的表结构与原来的MySQL存储结构基本类似,因此我们采用DataX的TDengine插件,很方便就将历史数据迁移过来了。至此,我们就用TDengine替换了原有的存储架构。总结
初始接触一个新产品,难免会遇到一些困难。好在办法总比困难多,在同事们的支持下,在TDengine的工程师们的支持下,我们总算是基本完成了这次实时数据存储查询的升级改造。当前项目数据测点大概在18万左右,改造后数据存储周期由原来的5分钟减少到1秒钟,存储的数据维度更精细了,能为平台的智能诊断、智能分析服务提供更准确的数据支持,同时各业务场景下的计算查询性能也提升了不少,数据库服务器由原来的6台减少到目前的3个节点集群。来源 https://www.modb.pro/db/188742