一、整体结构
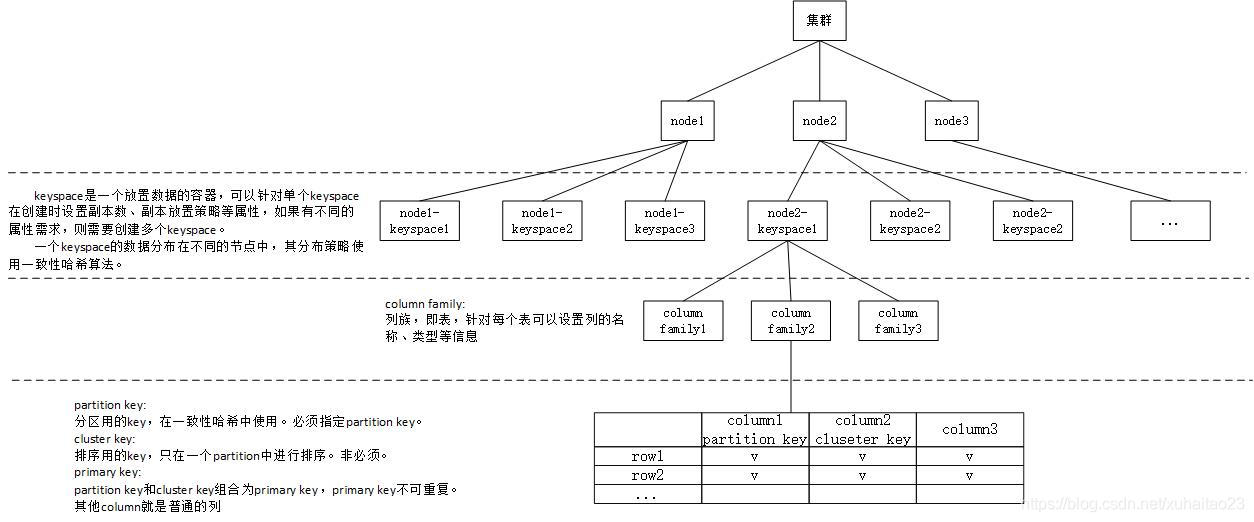
scylladb的大致存储结构如下图所示。
1.一个集群有多个节点组成,一个节点是一个scylladb服务,一般就是一台主机。
2.集群中可以创建多个keyspace,每个keyspace都分布在所有节点上,可以针对keyspace指定副本数、副本策略等属性
3.keyspace中可以创建多个column family,column family类似与sql中的表,可以指定列的名称、类型等信息,可以对行进行插入、删除、更新操作
4.parition key是一个特殊的列,作为分区(即分partition,一个partition中的数据保存到同一个节点中)的依据,分区使用一致性hash算法,后面介绍。也可以组合使用多个列作为partition key
5.cluster key也是一个特殊的列,作为一个分区内的排序依据,搜索时指定[特定parition key]+[cluster key的范围]可以进行快速搜索。
6.primary key由partition key和cluster key组合而成,primary key不可重复。
二、一致性hash算法
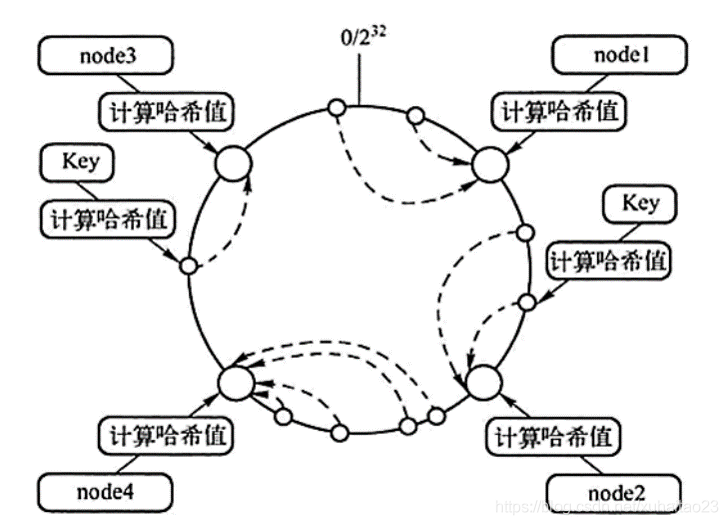
1.每个node有一个token,token计算哈希值并对应到一个圆环上,圆环对应一个数值范围,新版本上应该是0~2^64。圆环上的这些node将圆环分成了多个区间,一个区间属于这个区间的端点上的node。
2.对每个row的partition key计算其hash值,也分布到圆环上,会属于其中一个区间,该row会报存到该区间所属的node。
3.新增/删除node时,数据分布会发生变化,需要迁移。
4.为了使数据分布更均匀,一个node实际会有多个token。这样新增、删除node时数据分布会更均匀。
三、文件结构
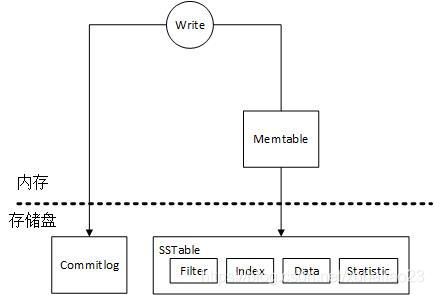
1.Memtable
写入SSTable前会先在内存中进行缓存,当达到一定条件(超过上限,或者超过时间间隔)后再写入SSTable。
2.Commitlog
写入数据时,首先记录到Commitlog中,保存在硬盘。写入到SSTable后会删除Commitlog中对应内容。
3.SSTable
保存数据。一个SSTable保存一个ColumnFalimy的一部分数据。SSTable中保存的数据是连续的,即
4. Filter
使用了Bloom Filter,用于快速判断一个key是否保存在当前SSTable中。
5.Index
保存一个key在Data中的位置,避免读取数据时需要读取整个Data文件。
四、bloom filter
1.bloom filter
一个m位的数组
2.hash算法
使用k个hash算法,用于生成元素的hash值。图中是3个hash算法,对一个元素x1,3个算法各自生成一个值,生成了3个hash值。
3.更新bloom filter
对新元素使用k个hash算法生成k个hash值,将hash值对应的位置为1
4.判断是否通过bloom filter
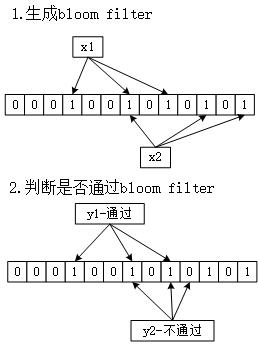
对一个需要判断的元素y,使用k个hash算法生成k个hash值,对应的位上的值全为1则通过,否则不通过
5.存在误判,误判概率的计算、相关参数的设置依据参考:https://blog.csdn.net/jiaomeng/article/details/1495500
————————————————
版权声明:本文为CSDN博主「cocoti」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xuhaitao23/article/details/110813232
