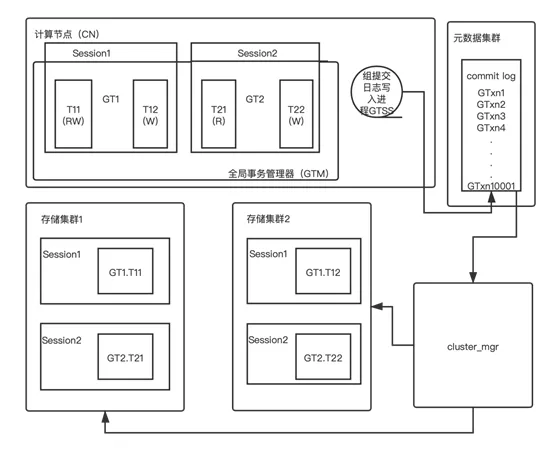
为避免经典的两阶段提交算法缺陷的发生,昆仑分布式数据库的分布式事务处理机制基于经典的两阶段提交算法,并在此基础上增强了其容灾能力和错误处理能力。故此可以做到任意时刻昆仑数据库集群的任意节点宕机或者网络故障、超时等都不会导致集群管理的数据发生不一致或者丢失等错误。昆仑数据库分布式事务处理功能涉及的模块分布在计算节点,存储集群和元数据集群和cluster_mgr模块中(如图1)。计算节点包含全局事务管理器(Global Transaction Manager,GTM),它掌握着一个计算节点中正在运行的每一个客户端连接(即Session,会话)中正在执行的分布式事务GT的内部状态,关键信息包括事务GT读写了哪些存储集群(storage shard),以及全局事务ID等。- GT1在存储集群1上执行的事务分支T11做了读写操作,在存储集群2上执行的事务分支T12做了写入操作。
- GT2在存储集群1上执行的事务分支T21做了只读操作,在存储集群2上执行的事务分支T22做了写入操作。
计算节点的GTSS后台进程负责成组批量写入全局事务的commit log日志到元数据集群中。昆仑数据库会确保每一个记录了Commit log的全局事务GT,都一定会完成提交。具体的两阶段提交流程见下文详述,本节先把相关模块介绍完。元数据集群也是一个高可用的MySQL 集群,它的commit log记录着每一个两阶段提交的事务的提交决定。这些提交决定是给cluster_mgr做错误处理使用的,实际生产系统场景下极少会真的用到,但是其信息非常关键。只有当计算节点或者存储节点发生宕机、断电等故障和问题时,才会被cluster_mgr用来处理残留的prepared状态的事务分支。存储集群是一个MySQL在存储集群中,mysql的会话(THD)对象内部,包含分布式事务分支(简称XA事务)的状态:- 在下图(如图1)中存储节点1包含分布式事务GT1的事务分支GT1.T11和GT2的事务分支GT2.T21的本地执行状态。
- 在下图(如图1)中存储节点2包含分布式事务GT1的事务分支GT1.T12和GT2的事务分支GT2.T22的本地执行状态。
cluster_mgr是一个独立进程,借助元数据集群中的元数据,与存储集群和计算节点交互,辅助它们工作。在分布式事务处理这个场景下,它负责处理因为计算节点和/或存储节点宕机而残留的prepared状态的事务分支,根据每个事务分支所属的全局事务的commit log来决定提交或者回滚其事务分支(具体会在下文详述)。图1. 昆仑数据库分布式事务处理涉及的功能模块和组件
三、如何实现两阶段提交?
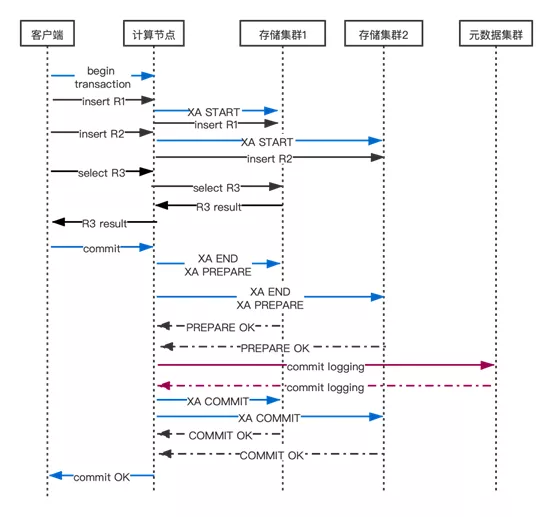
在用户发送begin transaction给计算节点时,计算节点会在其内部开启一个新的分布式事务GT对象(GTM会为这个分布式事务GT建立内部状态)。然后在GT事务运行期间读写一个存储集群时,GTM会发送包含XA START在内的若干条SQL语句启动GT在这个存储集群中的事务分支,并初始化事务状态。然后发送DML语句来读写数据。计算节点会对收到的SQL语句做解析、优化、执行并计算应该向哪些目标分片发送什么样的SQL语句完成局部数据读写工作,只读写确实含有目标数据的存储集群。计算节点与一组存储节点的通信总是做异步通信,确保存储节点并发执行SQL语句(不过这部分内容不是本文讨论的重点)。 在一个分布式事务GT执行commit之前如果发生了昆仑数据库集群中的节点、网络故障或者存储节点的部分SQL语句执行出错,那么计算节点的GTM会回滚事务GT及其在存储节点上的所有事务分支,GT相当于没有被执行过,它不会对用户数据造成任何影响。下面详述计算节点执行客户端发送commit的语句的分布式事务提交流程。事务提交的正常情况流程(时序图)见图2。
3.1 阶段
当客户端/应用发送commit语句时,GTM根据分布式事务GT的内部状态选择提交策略(当GT写入的存储集群少于2个时,对GT访问过的所有存储集群执行一阶段提交)。在MySQL中这个SQL语句是XA COMMIT ... ONE PHASE;在分布式事务做阶段提交过程中如果发生任意节点宕机,那么这些节点本地完成恢复即可正常工作,用户数据不会错乱、不一致。具体来说,如果宕机的节点包含那个做过写入的节点WN,那么WN完成本地恢复后,如果GT在WN的事务分支TX被恢复了,那么GT的全部改动(全部在TX中)就是生效的,否则GT的全部改动(全部在TX中)就没有生效(无论如何GT的原子性都是保持的)。如果宕机的节点全部都是GT的只读节点那么GT的任何改动都没有丢失,也不会造成GT的状态出错或者数据不一致。执行只读事务分支的存储节点重启并完成恢复后,那些之前运行中的只读事务残留的undo log都会被InnoDB自动清除,其他之前运行时的内部状态全部在内存中,随着重启已经都消失了,因此完全可以忽略只读事务一阶段提交的任何错误。所以这种情况下,对其的写入节点的commit语句可以正常继续执行。当GT写入的存储集群不少于2个时,GTM对GT写入过的所有存储集群执行两阶段提交,并且对GT只读访问过的每个存储集群执行一阶段提交。执行两阶段提交时,阶段全部返回成功后才会执行第二阶段的提交(XA COMMIT) 命令,否则第二阶段会执行XA ROLLBACK命令回滚所有两阶段提交的事务分支。
3.2 如何批量写Commit log?
在开始第二阶段提交之前,GTM会请求GTSS进程为每个GT写入commit log并且等待其成功返回。只有成功为GT写入commit log后GTM才会对GT开始第二阶段提交,否则直接回滚这些prepared状态的事务分支。GTM在每个后端进程(backend process是PostgreSQL术语,也就是执行一个用户连接中的SQL语句的进程,每个用户连接绑定一个后端进程)中会把每个要开始第二阶段提交的分布式事务的ID等关键信息放入GTSS的请求队列然后等待GTSS通知请求完成。GTSS会把请求队列中所有的commit log写入请求转换为一条SQL insert语句发给元数据集群,该集群执行insert语句完成commit logging并向GTSS确认成功,然后GTSS即可通知每一个等待着的后端进程开始第二阶段提交。如果commit log写入失败那么计算节点会发送回滚命令(XA ROLLBACK) 让存储集群回滚GT的事务分支。如果commit log 写入超时那么计算节点会断开与存储集群的连接以便让cluster_mgr事后处理。所有确认写入commit log的分布式事务一定会完成提交,如果发生计算节点或者存储节点故障或者网络断连等,那么cluster_mgr 模块会按照commit log 的指令来处理这些prepared 状态的事务分支。
3.3 元数据节点会不会成为性能瓶颈?
一定会有读者担心,把所有计算节点发起的分布式事务的commit log写到同一个元数据集群中,那么元数据集群会不会成为性能瓶颈?会不会出现单点依赖?经过验证并与我们的预期相符的是:在100万TPS的极高吞吐率情况下,元数据集群也完全不会成为性能瓶颈。具体来说,在1000个连接的sysbench测试满负荷运行时,GTSS批量写入commit log的这个组的规模通常在200左右,其他的工作负载以及相关参数配置(默认cluster_commitlog_group_size = 8 和cluster_commitlog_delay_ms=10)下,这个规模可能更大或者更小。考虑到每行commit log数据量不到20个字节(是与工作负载无关的固定长度),也就是200个存储集群的分布式事务会导致元数据集群执行一个写入约4KB WAL日志的事务,那么即使集群整体TPS达到100万每秒,元数据集群也只有5千TPS,每秒写入20MB WAL日志,对于现在的SSD存储设备来说是九牛一毛,完全可以负担的。所以即使存储集群满负荷运行,元数据集群的写入负载仍然极低(元数据集群不会成为昆仑数据库集群的性能瓶颈)。GTSS会多等待cluster_commitlog_delay_ms毫秒以便收集至少cluster_commitlog_group_size个事务批量发送给元数据集群。通过调整这两个参数可以在commit log组规模和事务提交延时之间取得平衡。
3.4 第二阶段
当commit log写入成功后,GTSS进程会通知所有等待其commit log写入结果的用户会话(连接)进程,这些进程就可以开始第二阶段提交了。第二阶段中,GTM向当前分布式事务GT写入过的每个存储节点并行异步发送提交(XA COMMIT)命令,然后等待这些节点返回结果。无论结果如何(断连,存储节点故障),GTM都将返回成功给用户。因为第二阶段开始执行就意味着这个事务一定会完成提交。甚至如果第二阶段进行过程中计算节点宕机或者断网了那么这个事务仍将提交,此时应用系统后端(也就是数据库的客户端)会发现自己的commit语句没有返回直到数据库连接超时(通常应用层也会让终端用户连接超时)或者返回了断连错误。
四、总结
笔者和团队在昆仑分布式数据库中的两阶段提交方式,可以成功避免经典的两阶段提交算法的缺陷。
而在此分布式事务处理两阶段提交机制和原理上,笔者和增强其容灾能力和错误处理能力,可以做到任意时刻昆仑数据库集群的任意节点宕机或者网络故障、超时等都不会导致集群管理的数据发生不一致或者丢失等错误。
下篇文章详述《分布式事务对于两阶段提交的错误处理》~
点击阅读原文
推荐阅读
KunlunBase架构介绍
KunlunBase技术优势介绍
KunlunBase技术特点介绍
KunlunBase集群基本概念介绍
END
昆仑数据库是一个HTAP NewSQL分布式数据库管理系统,可以满足用户对海量关系数据的存储管理和利用的全方位需求。
应用开发者和DBA的使用昆仑数据库的体验与单机MySQL和单机PostgreSQL几乎完全相同,因为首先昆仑数据库支持PostgreSQL和MySQL双协议,支持标准SQL:2011的 DML 语法和功能以及PostgreSQL和MySQL对标准 SQL的扩展。同时,昆仑数据库集群支持水平弹性扩容,数据自动拆分,分布式事务处理和分布式查询处理,健壮的容错容灾能力,完善直观的监测分析告警能力,集群数据备份和恢复等 常用的DBA 数据管理和操作。所有这些功能无需任何应用系统侧的编码工作,也无需DBA人工介入,不停服不影响业务正常运行。
昆仑数据库具备全面的OLAP 数据分析能力,通过了TPC-H和TPC-DS标准测试集,可以实时分析新的业务数据,帮助用户发掘出数据的价值。昆仑数据库支持公有云和私有云环境的部署,可以与docker,k8s等云基础设施无缝协作,可以轻松搭建云数据库服务。
请访问 http://www.kunlunbase.com/ 获取更多信息并且下载昆仑数据库软件、文档和资料。
KunlunBase项目已开源
【GitHub:】
https://github.com/zettadb
【Gitee:】
https://gitee.com/zettadb