本文将结合MySQL 8.0.19 分析InnoDB崩溃恢复的拉起过程,包括恢复前的准备工作,redo回放,undo回滚,以及崩溃恢复后Crash Safe DDL的实现。其中重点介绍redo的回放。
整体的代码流程如下,InnoDB崩溃恢复的流程是从srv_start, innobase_dict_recover ,ha_post_recover这三个函数中展开,后文会详细介绍。
|-->mysqld_main
| |--> init_server_components
| | |--> dd::init
| | | |-->/*忽略了一些链路*/
| | | |--> run_bootstrap_thread
| | | | |--> /*恢复线程中执行*/
| | | | |--> handle_bootstrap
| | | | | |--> do_pre_checks_and_initialize_dd
| | | | | | |--> DDSE_dict_init
| | | | | | | |--> innobase_ddse_dict_init
| | | | | | | | |--> innobase_init_files
| | | | | | | | | |--> /*崩溃恢复主函数*/
| | | | | | | | | |--> srv_start
| | | | | | |--> restart_dictionary
| | | | | | | |--> bootstrap::restart
| | | | | | | | |--> DDSE_dict_recover
| | | | | | | | | |--> /*事务回滚主函数*/
| | | | | | | | | |--> innobase_dict_recover
| | | | |--> /*崩溃恢复结束*/
| | |--> /*Crash Safe DDL*/
| | |--> ha_post_recover
重要结构体
程序=算法+数据结构,所以在介绍具体实现之前,将介绍涉及到的结构体,方便理解代码的实现。
recv_sys_t : 这个结构体变量用来描述恢复系统运行时刻的状态。InnoDB运行时刻有一个该数据结构的实例recv_sys。
下面的代码块为结构体的成员变量,其中英文注释来自源码,中文注释是自己的理解。
spaces : 是以space_id做hash的hash表,表里面存放的元素是以page_no做hash的hash表(pages), pages表里存放的是按照lsn大小排序的需要在该页上进行恢复的日志记录。
parse_start_lsn:本次日志重做恢复起始的lsn,如果是从checkpoint处开始恢复,等于checkpoint_lsn。
scanned_lsn: 在恢复过程,将恢复日志从log_sys->buf解析块后存入recv_sys->buf的日志lsn.
recovered_lsn:已经将数据恢复到page中或者已经将日志操作存储addr_hash当中的日志lsn;
struct recv_sys_t {
/** Every space has its own heap and pages that belong to it. */
struct Space {
/** Constructor
@param[in,out] heap Heap to use for the log records. */
explicit Space(mem_heap_t *heap) : m_heap(heap), m_pages() {}
/** Default constructor */
Space() : m_heap(), m_pages() {}
/** Memory heap of log records and file addresses */
mem_heap_t *m_heap;
/** Pages that need to be recovered */
Pages m_pages;
};
using Pages =
std::unordered_map<page_no_t, recv_addr_t *, std::hash<page_no_t>,
std::equal_to<page_no_t>>;
/*内部维护的hash table,key为SpaceID,value为Space。
而Space内部也有个hash table,保存相同page_no的日志。
暴露给程序,经常在代码里看到*/
/** Hash table of pages, indexed by SpaceID. */
using Spaces = std::unordered_map<space_id_t, Space, std::hash<space_id_t>,
std::equal_to<space_id_t>>;
Spaces *spaces;
/*spaces中包含recv_addr的个数*/
/** Number of not processed hashed file addresses in the hash table */
ulint n_addrs;
/*!< mutex protecting the fields apply_log_recs, n_addrs, and the
state field in each recv_addr struct */
/*保护锁*/
ib_mutex_t mutex;
/** mutex coordinating flushing between recv_writer_thread and
the recovery thread. */
ib_mutex_t writer_mutex;
/*mysql封装的条件变量,用来通知page cleaner线程刷盘操作*/
/** event to activate page cleaner threads */
os_event_t flush_start;
/*mysql封装的条件变量,用来通知page cleaner线程停止刷盘*/
/** event to signal that the page cleaner has finished the request */
os_event_t flush_end;
/*刷盘方式*/
/** type of the flush request. BUF_FLUSH_LRU: flush end of LRU,
keeping free blocks. BUF_FLUSH_LIST: flush all of blocks. */
buf_flush_t flush_type;
/*正在应用log record到page中*/
/** This is true when log rec application to pages is allowed;
this flag tells the i/o-handler if it should do log record
application */
bool apply_log_recs;
/*批量应用log record标志*/
/** This is true when a log rec application batch is running */
bool apply_batch_on;
/*恢复时后的块内存缓冲区*/
/** Possible incomplete last recovered log block */
byte *last_block;
/*后块内存缓冲区的起始位置,因为last_block是512地址对齐的,需要这个变量记录free的地址位置*/
/** The nonaligned start address of the preceding buffer */
byte *last_block_buf_start;
/*从日志块中读取的重做日志信息数据*/
/** Buffer for parsing log records */
byte *buf;
/** Size of the parsing buffer */
size_t buf_len;
/** Amount of data in buf */
ulint len;
/*本次日志重做恢复起始的lsn*/
/** This is the lsn from which we were able to start parsing
log records and adding them to the hash table; zero if a suitable
start point not found yet */
lsn_t parse_start_lsn;
/** The log data has been scanned up to this lsn */
/*在恢复过程,将恢复日志从log_sys->buf解析块后存入recv_sys->buf的日志lsn*/
lsn_t scanned_lsn;
/*恢复日志的checkpoint 序号*/
/** The log data has been scanned up to this checkpoint
number (lowest 4 bytes) */
ulint scanned_checkpoint_no;
/*恢复位置的偏移量*/
/** Start offset of non-parsed log records in buf */
ulint recovered_offset;
/*已经将数据恢复到page中或者已经将日志操作存储addr_hash当中的日志lsn*/
/** The log records have been parsed up to this lsn */
lsn_t recovered_lsn;
/*是否开启日志恢复诊断*/
/** Set when finding a corrupt log block or record, or there
is a log parsing buffer overflow */
bool found_corrupt_log;
};另外还有2个重要的数据结构,结构体定义非常简单。
recv_addr_t 结构体如下:
其中rec_list是相同page redo的链表
/** Hashed page file address struct */
struct recv_addr_t {
using List = UT_LIST_BASE_NODE_T(recv_t);
/** recovery state of the page */
recv_addr_state state;
/** Space ID */
space_id_t space;
/** Page number */
page_no_t page_no;
/** List of log records for this page */
List rec_list;
};
/** Stored log record struct */
struct recv_t {
using Node = UT_LIST_NODE_T(recv_t);
/** Log record type */
mlog_id_t type;
/** Log record body length in bytes */
ulint len;
/** Chain of blocks containing the log record body */
recv_data_t *data;
/** Start lsn of the log segment written by the mtr which generated
this log record: NOTE that this is not necessarily the start lsn of
this log record */
lsn_t start_lsn;
/** End lsn of the log segment written by the mtr which generated
this log record: NOTE that this is not necessarily the end LSN of
this log record */
lsn_t end_lsn;
/** List node, list anchored in recv_addr_t */
Node rec_list;
};这几个数据结构运行时刻的关系如下:
准备阶段
InnoDB的recovery的函数入口是srv_start,进行一些innodb启动以及崩溃恢复的准备阶段。
包括:
- 物理文件扫描(建立space_id到文件名的映射)
- recv_sys的初始化
- IO线程的初始化
- page cleaner线程的初始化
- 打开系统表空间,并进行系统检查
物理文件扫描
在InnoDB启动时,首先会通过 fil_set_scan_di 拿到目录。然后进入 fil_scan_for_tablespaces,并行扫描datadir这个目录下scan所有的”.ibd”文件,并且解析其中的Page0-3,读取对应的Space_id,检查是否存在相同Space_ID但文件名不同的”.ibd”文件,并且和文件名也就是Tablespace名做一个映射,保存在Fil_system的Tablespace_dirs midrs中,这个mdirs主要用来在InnoDB的crash recovery阶段解析log record时,通过space_id拿到文件名。
在InnoDB运行过程中,在内存中会保存所有Tablesapce的Space_id,Space_name以及相应的”.ibd”文件的映射,这个结构都存储在InnoDB的Fil_system这个对象中,在Fil_system这个对象中又包含64个shard,每个shard又会管理多个Tablespace,整体的关系为:Fil_system -> shard -> Tablespace。
下面来看下 fil_scan_for_tablespaces 的调用逻辑:
|--> srv_start
| |--> /*Discover tablespaces by reading the header from ibd files*/
| |--> fil_scan_for_tablespaces
| | |--> Fil_system::scan
| | | |--> Tablespace_dirs::scan
| | | | |--> fil_get_scan_threads /*根据文件数决定扫描线程数目*/
| | | | |--> Tablespace_dirs::duplicate_check
| | | | | |--> /*根据文件名读取space_id*/
| | | | | |--> Fil_system::get_tablespace_id(phy_filename)
| | | | | |--> Tablespace_files::add(space_id, filename)
recv_sys初始化
recv_sys_create和recv_sys_init来初始化恢复过程中重要的结构体recv_sys_t *recv_sys。
recv_sys_create主要用来初始化recv_sys的mutex和writer_mutex,后面的并发行为通过这两个mutex保护。
recv_sys_init中主要初始化成员变量,值得注意的是,如果开启只读,则初始化flush_start 和 flush_end,避免恢复阶段的刷盘行为。
void recv_sys_init(ulint max_mem)
{
if (!srv_read_only_mode) {
recv_sys->flush_start = os_event_create();
recv_sys->flush_end = os_event_create();
}
}
IO线程初始化
接着初始化后台IO线程,包括四个read thread+四个write thread+一个log thread+一个insert buffer thread
如果开启只读,insert buffer thread、log thread将不会被创建。
page cleaner线程初始化
接着进行异步刷脏线程的初始化,入口函数是buf_flush_page_cleaner_init。会创建一个 buf_flush_page_cleaner_coordinator线程,和若干buf_flush_page_cleaner_worker。
崩溃恢复期间的刷脏,buf_flush_page_coordinator_thread和recv_writer_thread是通过条件变量recv_sys->flush_start和recv_sys->flush_end 进行通信。注意,此时recv_writer_thread还没创建,它是在recv_recovery_from_checkpoint_start中创建的,后面会介绍。
buf_flush_page_coordinator_thread和buf_flush_page_cleaner_worker通过条件变量page_cleaner->is_requested和page_cleaner->is_finished通信。基本流程如下,可以看到当打开只读时,恢复过程中不会参与刷盘。
崩溃恢复结束后,recv_writer_thread销毁。
|--> buf_flush_page_coordinator_thread
| |//create and start page cleaner work thread
| |
| |/*if not read-only,then loop for recovery*/
| |/*loop*/
| |--> os_event_wait(recv_sys->flush_start)
| |--> pc_request // 任务分发,slot 数目等于 bp_instance 数目
| | |--> os_event_set(page_cleaner->is_requested)
| |--> pc_flush_slot // 参与刷脏.FLUSH_LRU or FLUSH_LIST
| |--> pc_wait_finished
| |--> os_event_reset(recv_sys->flush_start)
| |--> os_event_set(recv_sys->flush_end)
| |/*out of loop*/
|
| |/*when mysqld recovery,skip out of the above loop*/
| |--> os_event_wait(buf_flush_event)
|
| /* loop */
| |--> page_cleaner_flush_pages_recommendation // 计算大刷脏量
| |--> pc_request // 任务分发,slot 数目等于 bp_instance 数目
| | |--> os_event_set(page_cleaner->is_requested)
| |--> pc_flush_slot // 参与刷脏
| |--> pc_wait_finished
| /* out of loop */
|--> buf_flush_page_cleaner_thread
| |--> os_event_wait(page_cleaner->is_requested)
| |--> pc_flush_slot // 1 个线程处理 1 个 bp_instance
| | |--> buf_flush_LRU_list // 从 LRU 中刷脏
| | | |--> buf_flush_do_batch(BUF_FLUSH_LRU)
| | |
| | |--> buf_flush_do_batch(BUF_FLUSH_LIST) // 从 flush_list 刷脏
| | | |--> buf_flush_batch
| | | | |--> buf_do_LRU_batch
| | | | | |--> buf_free_from_unzip_LRU_list_batch
| | | | | |--> buf_flush_LRU_list_batch
| | | | | | |--> buf_LRU_free_page
| | | | | | |--> buf_flush_page_and_try_neighbors
| | | | | | | |--> buf_flush_try_neighbors
| | | | | | | | |--> buf_flush_page
| | | | |
| | | | |--> buf_do_flush_list_batch
| | | | | |--> buf_flush_page_and_try_neighbors
/** tasked with flushing dirty pages from the buffer*/
|--> recv_writer_thread
| /* loop */
| |/* Flush pages from end of LRU if required */
| |--> os_event_reset(recv_sys->flush_end)
| |--> recv_sys->flush_type = BUF_FLUSH_LRU
| |--> os_event_set(recv_sys->flush_start)
| |--> os_event_wait(recv_sys->flush_end)
| /* out of loop */
|--> recv_apply_hashed_log_recs
| |--> buf_flush_wait_LRU_batch_end
| | |--> buf_flush_wait_batch_end(buf_pool, BUF_FLUSH_LRU)
| |--> os_event_reset(recv_sys->flush_end)
| |--> recv_sys->flush_type = BUF_FLUSH_LIST;
| |--> os_event_set(recv_sys->flush_start);
| |--> os_event_wait(recv_sys->flush_end);
| |--> buf_pool_invalidate();
| | |--> buf_pool_invalidate_instance
| | | |--> buf_flush_wait_batch_end(buf_pool, type)
| | | |--> buf_LRU_scan_and_free_block
| | | | |--> buf_LRU_free_from_common_LRU_list
|--> recv_sys_free
| |--> recv_sys_finish
| |--> os_event_set(recv_sys->flush_start)
|--> srv_shutdown_all_bg_threads
| |--> os_event_set(recv_sys->flush_start)
打开系统表空间
数据库启动后,InnoDB 会通过 read_lsn_and_check_flags() 函数读取系统表空间中 flushed_lsn ,这一个 LSN 只在系统表空间的个页中存在,而且只有在正常关闭的时候写入。
系统正常关闭时,会调用 srv_shutdown_log() -> fil_write_flushed_lsn() ,也就是在执行一次 sharp checkpoint 之后,将 LSN 写入。另外需要注意的是,写 flushed_lsn 时会同时写入到 Double Write Buffer,如果 flushed_lsn 对应的页损坏,则可以从 dbwl 中进行恢复。接下来,InnoDB 会通过 redo-log 日志找到近一次提交的 checkpoint,读取该 checkpoint 对应的 LSN 。其中,checkpoint 信息会保存在 redo-log 的个文件中,在两个固定偏移中轮流写入;所以,需要同时读取两个,并比较获取较大的一个值。
比较获得的 flushed_lsn 以及 checkpoint_lsn ,如果两者相同,则说明正常关闭;否则,就需要进行故障恢复。
flushed_lsn 只有在系统表空间的页存在,偏移量为 FIL_PAGE_FILE_FLUSH_LSN(26),也就是保证至少在此 LSN 之前的页已经刷到磁盘。
|--> srv_start
| |--> SysTablespace::open_or_create //打开系统表空间,并获取flushed_lsn
| | |--> read_lsn_and_check_flags
| | | |--> read_first_page
| | | |--> //将双写缓存加载到内存中,如果ibdata日志损坏,则通过dblwr恢复
| | | |--> buf_dblwr_init_or_load_pages
| | | |--> validate_first_page //校验个页是否正常,并读取flushed_lsn
| | | | |--> mach_read_from_8 //读取LSN,偏移为FIL_PAGE_FILE_FLUSH_LSN
| | | |--> restore_from_doublewrite //如果有异常,则从dblwr恢复//
崩溃恢复阶段
总体流程
- 首先获取当前已经写入redo log的日志量(flush_lsn),这个已经写入的日志量存放在系统表空间的页中。
- 然后将flush_lsn作为参数调用recv_recovery_from_checkpoint_start函数,初始化recv_sys_t结构,读取checkpoint, 然后从checkpoint开始读取日志,解析日志,应用日志。
- 后调用recv_recovery_from_checkpoint_finish函数进行一些崩溃恢复的清理工作,释放创建的recv_sys_t内存空间。
recv_recovery_from_checkpoint_start
其中崩溃恢复绝大部分的逻辑都集中在recv_recovery_from_checkpoint_start中,下面我们对它进行进一步的介绍。这其中的代码逻辑主要分为2个阶段,首先是日志扫描阶段,扫描阶段按照数据页的space_id和page_no分发redo日志到hash_table中,保证同一个数据页的日志被分发到同一个哈希桶中,且按照lsn大小从小到大排序。扫描完后,再遍历整个哈希表,依次应用每个数据页的日志。下面我们按照流程顺序做个基本的简介。
- 开始恢复前为每个buffer pool instance创建一颗红黑树,加速flush list插入速度,flush list是按照升序排列的,入口函数为 buf_flush_init_flush_rbt
- 然后找到ib_logfile0上大的lsn,入口函数为recv_find_max_checkpoint。在日志头中有2个checkpoint block域。InnoDB是采用2个checkpoint了轮流写的方式来保证checkpoint写操作的安全(并不是一次写2份checkpoint, 而是轮流写)。 由于redo log是幂等的,应用一次和与应用两次都是一样的(在实际的应用redo log时,如果当前这一条log记录的lsn大于当前page的lsn,说明这一条log还没有被应用到当前的page中去)。所以,即使某次checkpoint block写失败了,那么崩溃恢复的时候从上一次记录的checkpoint点开始恢复也能正确的恢复数据库事务。
- 如果开启了只读,进行完一些列初始化工作后,函数会直接返回,不会进入恢复操作。如果没有开启,则继续往下走。
- 进入recv_init_crash_recovery函数,进行崩溃恢复的环境初始化工作。包括半页写的恢复(buf_dblwr_process),以及创建recv_writer_thread。
recv_writer_thread,这个线程和page cleaner线程配合使用,它会去通知page cleaner线程去flush崩溃恢复产生的脏页,直到recv_sys中存储的redo记录都被应用完成并彻底释放掉。其中buf_dblwr_process的大致逻辑为:
- 遍历double write物理文件拿到所有的space_no和page_id,去检查数据页是否完整。如果不完整进入下一步
- 检查 对应double writer 的数据的完整性,如果不完整直接丢弃,记录错误日志,重新执行 redo log
- 如果 double write 的数据是完整的,用 double buffer 的数据更新该数据页,跳过该 redo log。
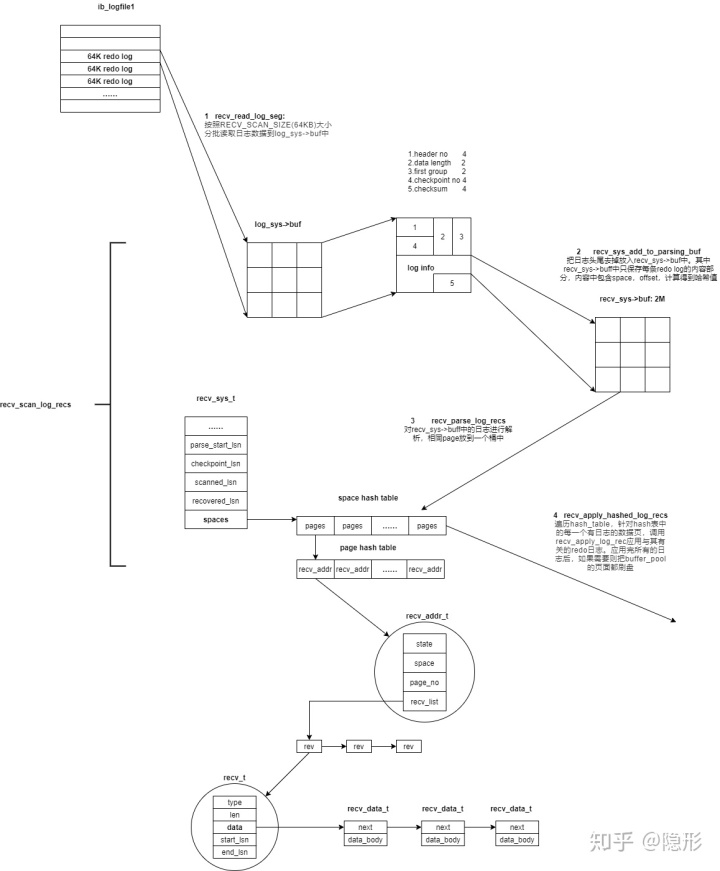
- 接下来用读取到的checkpoint数据作为参数调用recv_recovery_begin。崩溃恢复的主要代码流程来到了recv_recovery_begin。在recv_recovery_begin中,存在一个循环,该循环以checkpoint为起点,调用底层函数(recv_read_log_seg),按照RECV_SCAN_SIZE(64KB)大小分批读取日志数据到log_sys->buf中,然后调用调用recv_scan_log_recs对读取到的数据进行扫描解析和应用,直到所有的日志都处理完毕。
- 在recv_scan_log_recs中,首先通过block_no和lsn之间的关系以及日志checksum判断是否读到了日志后,如果读到后则返回(即使数据库是正常关闭的,也要走崩溃恢复逻辑,那么在这里就返回了,因为正常关闭的checkpoint值一定是指向日志后),否则调用recv_sys_add_to_parsing_buf函数把日志去头去尾放到一个recv_sys->buf中,日志头里面存了一些控制信息和checksum值,只是用来校验和定位,在真正的应用时没有用。接下来就开始调用recv_parse_log_recs对recv_sys->buf中的日志数据进行解析然后放到前面提到的hash表中。当hash表中存放的数据recv_addr_t达到一定的大小之后,就调用recv_apply_hashed_log_recs进行日志应用。
- 在recv_parse_log_recs时,解析到的日志分两种:single_rec和multi_rec,前者表示只对一个数据页进行一种操作,后者表示对一个或者多个数据页进行多种操作。日志中还包括对应数据页的space_id,page_no,操作的type以及操作的内容(具体单条日志记录的解析逻辑在recv_parse_log_rec函数中)。解析出相应的日志后,按照space_id和page_no进行哈希并放到hash_table里面即可,等待后续应用。在recv_single_rec和recv_multi_rec中都会调用到recv_parse_log_rec进行单条记录的解析。
- 在recv_apply_hashed_log_recs中,就是遍历hash_table,针对hash表中的每一个有日志的数据页。先找到对应的物理文件(fil_tablespace_open_for_recovery), 如果找不到(即已被删除),就将对应的日志设置为RECV_DISCARDED, 这些日志无需apply。然后调用recv_apply_log_rec应用与其有关的redo日志。应用完所有的日志后,如果需要则把buffer_pool的页面都刷盘.
- 在recv_apply_log_rec首先把需要应用日志的页读取到buffer pool中buf_page_get,然后调用recv_recover_page_func将日志的修改应用到该页中去。如果页面不在buffer中,会主动尝试采用预读的方式多读点page (
recv_read_in_area),搜集多连续32个(RECV_READ_AHEAD_AREA)需要做恢复的page no,然后发送异步读请求。 page 读入buffer pool时,会主动做崩溃恢复逻辑;
- 对于recv_recover_page_func
- 已经被删除的表空间,直接跳过其对应的日志记录;
- 只有LSN大于数据页上LSN的日志才会被apply; 忽略被truncate的表的redo日志;
- 在恢复数据页的过程中不产生新的redo 日志;
- 在完成修复page后,需要将脏页加入到buffer pool的flush list上;由于innodb需要保证flush list的有序性,而崩溃恢复过程中修改page的LSN是基于redo 的LSN而不是全局的LSN,无法保证有序性;InnoDB另外维护了一颗红黑树来维持有序性,每次插入到flush list前,查找红黑树找到合适的插入位置,然后加入到flush list上。(
buf_flush_recv_note_modification)
流程图如下:

|--> recv_recovery_from_checkpoint_start
| |--> buf_flush_init_flush_rbt //创建一颗红黑树,加速flush list插入速度
| |--> recv_find_max_checkpoint //从ib_logfile0中找到大的checkpoint
| |/*if not read-only*/
| |--> recv_init_crash_recovery //进行崩溃恢复的环境初始化工作
| | |--> buf_dblwr_process //恢复半页写
| | | |/*loop*/
| | | |--> buf_dblwr_recover_page
| | | | |--> if(block.is_corrupted())
| | | | | |-->if (dblwr_buf_page.is_corrupted())
| | | | | |--> //print error and skip
| | | | | |-->fi
| | | | | |fil_io //Write the good page from the doublewrite buffer to the intended position
| | | | |--> fi
| | | |/*out of loop*/
| | | |--> fil_flush_file_spaces
| | |
| | |--> srv_threads.m_recv_writer.start() //启动recv_writer_thread
| |--> recv_recovery_begin //崩溃恢复主函数
| | |/*loop*/
| | |--> recv_read_log_seg //按照RECV_SCAN_SIZE(64KB)大小分批读取日志数据到log_sys->buf中
| | |--> recv_scan_log_recs
| | | |/*loop*/
| | | |--> recv_sys_add_to_parsing_buf //把日志去头去尾放到一个recv_sys->buf中
| | | |/*out of loop*/
| | | |
| | | |--> recv_parse_log_recs
| | | | |--> recv_single_rec|recv_multi_rec
| | | | | |--> recv_parse_log_rec
| | | | | | |--> recv_parse_or_apply_log_rec_body //在这里仅仅解析记录
| | | |
| | | |/*if (recv_heap_used() > max_memory)*/
| | | |/*当hash表中存放的数据recv_addr_t达到一定的大小之后,则进行日志应用*/
| | | |--> recv_apply_hashed_log_recs
| | | | |/*loop*/
| | | | |/*恢复前,需要打开对应的物理文件*/
| | | | |--> fil_tablespace_open_for_recovery
| | | | |/*进入恢复逻辑*/
| | | | |--> recv_apply_log_rec
| | | | | |--> recv_recover_page
| | | | | | | /*loop*/
| | | | | | |--> recv_parse_or_apply_log_rec_body //根据日志类型,选择对于的恢复函数
| | | | | | | /*out of loop*/
| | | | | | |--> buf_flush_recv_note_modification //找到合适插入位置
| | | | |/*out of loop*/
| | | | |--> buf_flush_wait_LRU_batch_end //等待LRU刷盘结束
| | | | |--> os_event_reset(recv_sys->flush_end)
| | | | |--> recv_sys->flush_type = BUF_FLUSH_LIST //触发flush list刷盘
| | | | |--> os_event_set(recv_sys->flush_start)
| | | | |--> os_event_wait(recv_sys->flush_end)
| | | | |--> buf_pool_invalidate //清空buffer pool
| | |/*out of loop*/
recv_recovery_from_checkpoint_finish
进入recv_recovery_from_checkpoint_finish之前,还需要进行一些准备工作。需要考虑到Insert buffer:在刷走所有脏页之前,需要启动redo log相关日志线程。那是因为一些脏页可能因ibuf合并而变脏。 ibuf合并可能将日志写到redo log buffer。redo log必须刷新到新的脏页,然后将之前的页面刷新到磁盘。因此,我们需要log_flusher线程将刷新与ibuf合并相关的日志记录,允许刷新修改后的页面。
if (!srv_read_only_mode) {
log_start_background_threads(*log_sys);
}
recv_apply_hashed_log_recs(*log_sys, true);
同时还得应用后一个hash table的日志,因为上文recv_scan_log_recs中的日志的apply条件为:
if (recv_heap_used() > max_memory) {
recv_apply_hashed_log_recs(log, false);
}可能还有后一部分小于max_memory的日志。
后调用recv_recovery_from_checkpoint_finish函数进行一些崩溃恢复的清理工作,释放创建的recv_sys_t内存空间。
recv_recovery_from_checkpoint_finish
{
buf_flush_wait_LRU_batch_end
while (recv_writer_is_active())
{
sleep;
}
recv_sys_free
buf_flush_free_flush_rbt
}
回滚未完成的事务
前文主要讲恢复过程中的前滚,整个InnoDB recovery的阶段也就结束了,在该阶段中,所有已经被记录到redo log但是没有完成数据刷盘的记录都被重新落盘。但是仅仅这样是不够的,mysql内部通过binlog和redo完成阶段提交。事务提交,包含着redo log和Binlog落盘,两个过程。所以需要将只持久化了redo log,没有持久化Binlog的事务回滚。
在InnoDB初始化innobase_init_files函数执行完成之后,MySQL服务层会调用InnoDB引擎层的innobase_dict_recover函数,执行InnoDB更高层次的恢复过程。该函数会启动一个线程trx_recovery_rollback_thread,这个线程主要执行的函数为trx_rollback_or_clean_recovered,这里面会检测前滚阶段产生的事务是否已经提交,如果已经提交,那么清除这个事务可能存在的insert undo log(trx_undo_insert_cleanup)。如果这个事务未提交,那么就对其进行回滚(trx_rollback_active)。这里面的清除和回滚需要用到undo log。
|--> innobase_dict_recover
| |--> case DICT_RECOVERY_RESTART_SERVER
| |--> //打开所有表空间,并校验,上文有介绍
| |--> boot_tablespaces
| |--> srv_dict_recover_on_restart
| |--> end case
| |--> //Start the remaining InnoDB service threads
| |--> srv_start_threads
| | |--> //启动回滚线程
| | |--> trx_recovery_rollback_thread
| | | |--> trx_rollback_or_clean_recovered
| | | | |--> /*loop*/
| | | | |--> trx_rollback_resurrected
| | | | | |--> case TRX_STATE_COMMITTED_IN_MEMORY:
| | | | | |--> trx_cleanup_at_db_startup
| | | | | | |--> trx_undo_insert_cleanup
| | | | | |--> case TRX_STATE_ACTIVE:
| | | | | |--> trx_rollback_active
| | | | |--> /*end loop*/
| | |--> //启动主线程
| | |--> srv_master_thread
| | |-->//background stats gathering
| | |--> dict_stats_thread
| |--> fil_open_for_business
Crash Safe DDL
MySQL8.0新增了 Crash Safe DDL 特性,这里仅从崩溃恢复的角度做简单的分析。
在崩溃恢复结束后,会调用ha_post_recover接口函数,进而调用innodb内的函数Log_DDL::recover(),一样的replay其中的记录,并在结束后删除记录。但ALTER_ENCRYPT_TABLESPACE_LOG类型(对tablespace加密属性的修改)并非在这一步删除,而是加入到一个数组ts_encrypt_ddl_records中,在以后调用resume_alter_encrypt_tablespace来恢复操做。
|--> ha_post_recover
| |--> post_recover_handlerton
| | |--> innobase_post_recover
| | | |--> Log_DDL::recover
| | | | |--> Log_DDL::replay_all
| | | | | |--> /*loop*/
| | | | | |--> Log_DDL::replay
| | | | | | |--> case FREE_TREE_LOG
| | | | | | |--> replay_free_tree_log
| | | | | | |--> case DELETE_SPACE_LOG
| | | | | | |--> replay_delete_space_log
| | | | | | |--> case RENAME_SPACE_LOG
| | | | | | |--> replay_rename_space_log
| | | | | | |--> case ALTER_ENCRYPT_TABLESPACE_LOG
| | | | | | |--> replay_alter_encrypt_space_log
| | | | | |--> /*end of loop*/
| | | | |--> delete_by_ids
| | | | | |--> DDL_Log_Table::remove
注意点
实际运维过程中,mysql崩溃恢复往往比较久。一般耗时的原因在于事务的回放以及回滚或者库表数目较多。这里简单分析一下崩溃恢复阶段innodb的文件扫描,方便大家排查相关问题。
crash recovery阶段,文件按需打开
在crash recovery阶段,实际在Fil_system并不会保存全量的”.ibd”文件映射。前文提到:在InnoDB运行过程中,在内存中会保存所有Tablesapce的Space_id,Space_name以及相应的”.ibd”文件的映射。实际就是在shard的m_space和m_names中,但这两个结构并非是在InnoDB启动的时候就把所有的Tablespace和对应的”.ibd”文件映射都保存下来,而是在redo log回放过程中需要按需打开表文件(recv_apply_hashed_log_recs->fil_tablespace_open_for_recovery)。
|/*恢复前,需要打开对应的物理文件*/
|--> fil_tablespace_open_for_recovery
| |--> Fil_system::open_for_recovery
| | |--> Fil_system::lookup_for_recovery
| | | |--> get_scanned_files
| | |/*如果找不到,则返回false*/
| | |/*如果找到了相应文件,尝试着打开并修复*/
| | |--> get_scanned_files
| | |--> /*如果是活跃的Undo表空间,则返回*/
| | |--> Fil_system::ibd_open_for_recovery
| | | |--> 如果已经加载到cache,do nothing
| | | |--> Fil_shard::ibd_open_for_recovery
| | | | |--> /*打开文件后,开始校验*/
| | | | |--> Datafile::validate_for_recovery
| | | | | |--> /*校验页*/
| | | | | |--> Datafile::validate_first_page
| | | | | | |--> Datafile::read_first_page//读取页,然后检验
| | | | | | |--> /*读取之前的路径,并与现在的对比*/
| | | | | | |--> fil_space_read_name_and_filepath
| | | | | |--> /*if DB_CORRUPTION*/
| | | | | |--> open_read_write
| | | | | |--> find_space_id
| | | | | |--> /*如果有异常,则从dblwr恢复*/
| | | | | |--> restore_from_doublewrite
| | | | | | |--> /*copy the page from double write buffer to ibd*/
| | | | | | |--> os_file_write
| | | | | |--> /*Free previously read first page and then re-validate*/
| | | | | |--> free_first_page
| | | | | |--> Datafile::validate_first_page //再次检查
| | | | | |--> /*end if DB_CORRUPTION*/
| | | | |--> Fil_shard::space_create
| | | | |--> create_node /*Attach a file to a tablespace*/
| | | | |-->
| | |--> buf_dblwr_recover_pages //从double write恢复此表所有页面
| | | |--> /*loop*/
| | | |--> buf_dblwr_recover_page
| | | |--> /*end loop*/
| | | |--> fil_flush_file_spaces
|--> fil_tablespace_lookup_for_recovery
| |--> Fil_system::lookup_for_recovery
crash recovery结束后,文件全部打开
在crash recovery结束后,在DD的初始化过程中,会把DD中所保存的Tablesapce全部进行validate check一遍(Validate_files::check->fil_ibd_open->validate_to_dd),用于检查是否有丢失ibd文件或者数据有残缺等情况,在这个过程中,会把所有保存在DD中的Tablespace信息,并保存在Fil_system中会打开所有表文件。需要注意的是,如果库表较多,validate_to_dd可能耗时较久。
|--> DDSE_dict_recover
| |--> innobase_dict_recover
| | |--> boot_tablespaces
| | | |--> Validate_files::validate
| | | |--> /*multi thread scan*/
| | | |--> n_threads=fil_get_scan_threads
| | | |--> Validate_files::check
| | | | |--> fil_ibd_open
| | | | | |--> if(validate)
| | | | | |--> Datafile::validate_to_dd
| | | | | | |--> /*校验页是否正常,并读取flushed_lsn*/
| | | | | | |--> Datafile::validate_first_page
| | | | | | | |--> /*读取页,然后检验*/
| | | | | | | |--> Datafile::read_first_page
| | | | | | | | |--> os_file_read_no_error_handling
| | | | | | | | | |--> os_file_read_no_error_handling_func
| | | | | | | | | | |--> os_file_read_page
| | | | | | | |--> /*读取之前路径,并与现在的对比*/
| | | | | | | |--> fil_space_read_name_and_filepath
| | | | | |--> end if (validate)
| | | | | |--> fil_space_create
| | | | | |--> Fil_shard::create_node /*Attach a file to a tablespace*/
可以看到如果validate=1,会检查表空间页,涉及到磁盘的IO以及相关数据的校验( Tablespace flags,First page must be number 0 ,判断space id是否和之前相同)。如果库表过多,但是拉起耗时可以将srv_force_recovery=1。mysql8.0做的的优化是多线程扫描(fil_get_scan_threads)。同时8.0.21增加innodb_validate_tablespace_paths参数关闭正常启动时的表空间校验过程。其中validate的定义如下:
if (checkpoint_lsn != flush_lsn)
{
recv_needed_recovery=true;
}
const bool validate = recv_needed_recovery && srv_force_recovery == ;
innodb对文件映射的处理
总结下crash recovery前,crash recovery时,以及crash recovery后,innodb对".ibd”文件映射的处理
- crash recovery前,在InnoDB启动时,会先从datadir这个目录下scan所有的”.ibd”文件,并且解析其中的Page0-3,读取对应的Space_id,检查是否存在相同Space_ID但文件名不同的”.ibd”文件,并且和文件名也就是Tablespace名做一个映射,保存在midrs中。
- crash recovery时,按需调用fil_tablespace_open_for_recovery,打开相应文件进行恢复
- crash recovery结束后,初始化Data Dictionary Table,在DD的初始化过程中,会把DD中所保存的Tablesapce全部进行validate check一遍,用于检查是否有丢失ibd文件或者数据有残缺等情况,在这个过程中,会把所有保存在DD中的Tablespace信息,且在crash recovery中未能open的Tablespace全部打开一遍,并保存在Fil_system中,至此,整个InnoDB中所有的Tablespace的映射信息都会加载到内存中。
崩溃恢复触发条件
什么时候需要崩溃恢复呢? 阅读代码可以发现,recv_init_crash_recovery有两个入口。首先是recv_recovery_from_checkpoint_start函数中进行lsn的判断,如果符合条件,则进入recv_init_crash_recovery,初始化相关变量。如果 checkpoint_lsn == flush_lsn ,会在recv_scan_log_recs函数中继续判断,是否在checkpoint_lsn 后又写入了新的日志。为什么需要这么考虑呢?因为mysql其中后,下一次checkpoint前意外崩溃时,checkpoint_lsn == flush_lsn可能成立,而checkpoint_lsn后可能又新写入了日志。所以需要两个条件来限制。
- checkpoint_lsn != flush_lsn
recv_recovery_from_checkpoint_start
{
if (checkpoint_lsn != flush_lsn) {
recv_init_crash_recovery();
}
}- checkpoint_lsn 后又写入了日志
recv_scan_log_recs
{
if (!recv_needed_recovery &&
scanned_lsn > recv_sys->checkpoint_lsn) {
recv_init_crash_recovery();
}
}