前序
Greenplum是目前比较的mpp数据库,其官方推荐了几种将外部数据写入Greenplum方式,包含:通用的Jdbc,pgcopy和pgload以及Pivotal Greenplum-Spark Connector等。
Jdbc:Jdbc方式,写大数据量会很慢。
pgcopy:其中pgcopy是及其不推荐的一种,因为其写数据必须经过Greenplum的master,因此也只建议小数据量使用。
pgload:适合写大数据量数据,能并行写入。但其缺点是需要安装客户端,包括gpfdist等依赖,安装起来很麻烦。需要了解可以参考pgload。
Greenplum-Spark Connector:基于Spark并行处理,并行写入Greenplum,并提供了并行读取的接口。也是接下来该文重点介绍的部分。
2. Greenplum-Spark Connector读数据架构
一个Spark application,是由Driver和Executor节点构成。当Spark application使用Greenplum-Spark Connector加载Greenplum数据时,其Driver端会通过JDBC的方式请求Greenplum的master节点获取相关的元数据信息。Connector将会根据这些元数据信息去决定Spark的Executor去怎样去并行的读取该表的数据。
Greenplum数据库存储数据是按segment组织的,Greenplum-Spark Connector在加载Greenplum数据时,需要指定Greenplum表的一个字段作为Spark的partition字段,Connector会使用这个字段的值来计算,该Greenplum表的某个segment该被哪一个或多个Spark partition读取。
其读取过程如下:
1.Spark Driver通过Jdbc的方式连接Greenplum master,并读取指定表的相关元数据信息。然后根据指定的分区字段以及分区个数去决定segment怎么分配。
2.Spark Executor端会通过Jdbc的方式连接Greenplum master,创建Greenplum外部表。
3.然后Spark Executor通过Http方式连接Greenplum的数据节点,获取指定的segment的数据。该获取数据的操作在Spark Executor并行执行。
其示意流程图如下:
3. Greenplum-Spark Connector写数据流程
1.GSC在Spark Executor端通过Jetty启动一个Http服务,将该服务封装为支持Greenplum的gpfdist协议。
2.GSC在Spark Executor端通过Jdbc方式连接Greenplum master,创建Greenplum外部表,该外部表文件地址指向该Executor所启动的gpfdist协议地址。SQL示例如下:
CREATE READABLE EXTERNAL TABLE
"public"."spark_9dc823a6fa48df60_3d9d854163f8f07a_1_42" (LIKE "public"."rank_a1")
LOCATION ('gpfdist://10.0.8.145:44772/spark_9dc823a6fa48df60_3d9d854163f8f07a_1_42')
FORMAT 'CSV'
(DELIMITER AS '|'
NULL AS '')
ENCODING 'UTF-8'
3.GSC在Spark Executor端通过Jdbc方式连接Greenplum master,然后执行insert语句至真实的表中,数据来源于这张外部表。SQL示例如下:
INSERT INTO "public"."rank_a1"
SELECT *
FROM "public"."spark_9dc823a6fa48df60_3d9d854163f8f07a_1_42"
至于这张外部表的数据,是否落地当前Executor服务器,不清楚。猜测不会落地,而是直接通过Http直接传递给了Greenplum对应的Segment。
GSC监听onApplicationEnd事件,在Spark application结束后,删除创建的外部表。
4. Greenplum-Spark Connector使用
下载GSC Jar包。
下载地址:Pivotal Network。
可直接下载新版本的GSC即1.6.2,支持Greenplum5.0之后的版本。greenplum-spark_-.jar,如:
greenplum-spark_2.11-1.6.2.jar
maven中引入:
<dependency>
<groupId>io.pivotal.greenplum.spark</groupId>
<artifactId>greenplum-spark_2.11</artifactId>
<version>1.6.2</version>
</dependency>
spark提交引入:
spark-shell或spark-submit时候,通过–jars加入greenplum-spark_2.11-1.6.2.jar。
将greenplum-spark_2.11-1.6.2.jar与Spark application包打成 uber jar 提交。
5. Greenplum-Spark Connector参数
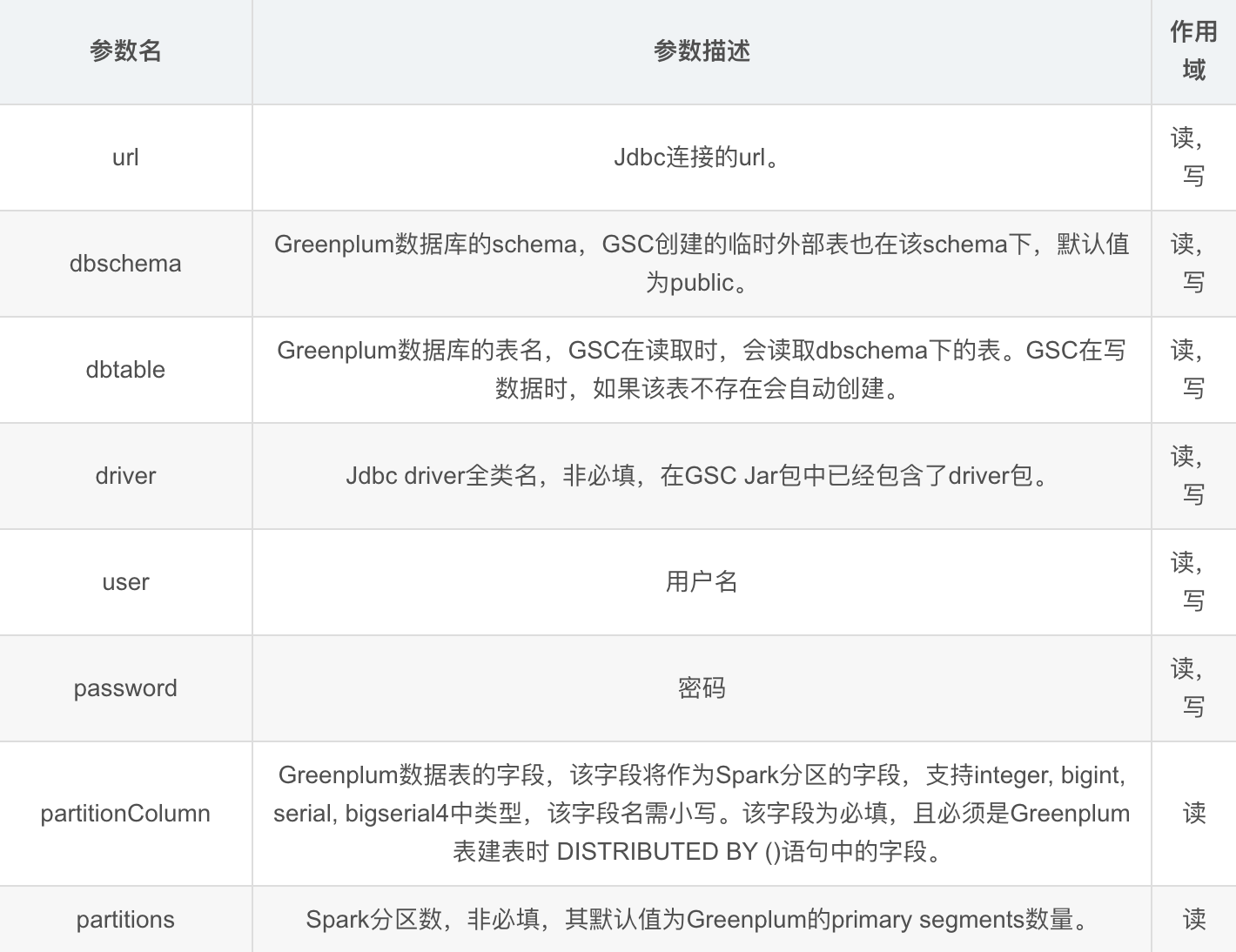
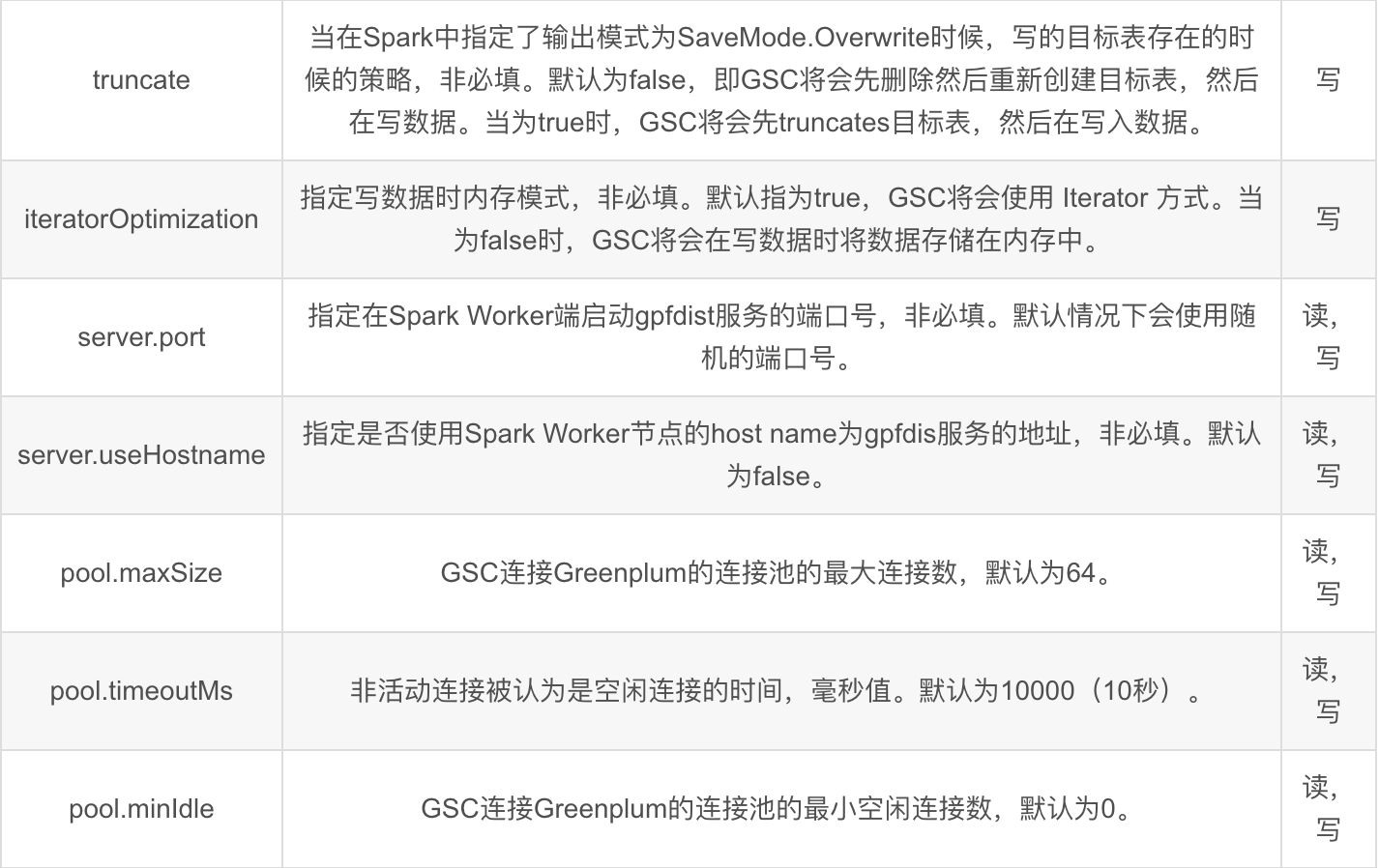
6. 从Greenplum读取数据
DataFrameReader.load()方式:
val gscReadOptionMap = Map(
"url" -> "jdbc:postgresql://gpdb-master:5432/testdb",
"user" -> "bill",
"password" -> "changeme",
"dbschema" -> "myschema",
"dbtable" -> "table1",
"partitionColumn" -> "id"
)
val gpdf = spark.read.format("greenplum")
.options(gscReadOptionMap)
.load()
spark.read.greenplum()方式:
val url = "jdbc:postgresql://gpmaster.domain:15432/tutorial"
val tblname = "avgdelay"
val jprops = new Properties()
jprops.put("user", "user2")
jprops.put("password", "changeme")
jprops.put("partitionColumn", "airlineid")
val gpdf = spark.read.greenplum(url, tblname, jprops)
然鹅,这种方式必然需要引入一个隐式转换,官网也没介绍。
7. 写数据至Greenplum
7.1. 写数据示例:
val gscWriteOptionMap = Map(
"url" -> "jdbc:postgresql://gpdb-master:5432/testdb",
"user" -> "bill",
"password" -> "changeme",
"dbschema" -> "myschema",
"dbtable" -> "table2",
)
dfToWrite.write.format("greenplum")
.options(gscWriteOptionMap)
.save()
在通过GSC写到Greenplum表时,如果表已经存在或表中已经存在数据,可通过DataFrameWriter.mode(SaveMode savemode)方式指定其输出模式。相关模式行为如下:
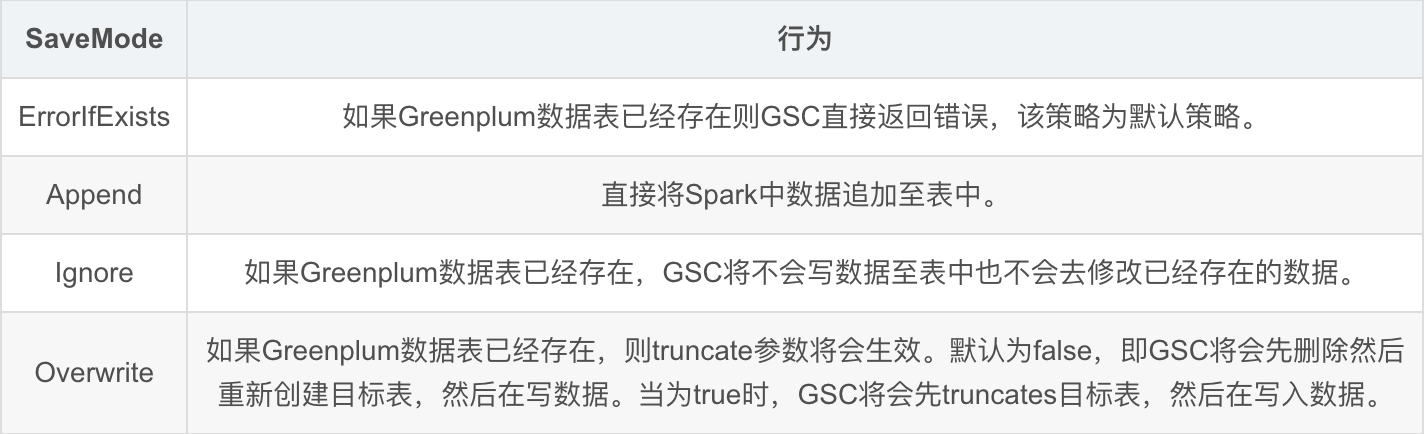
7.2. GSC自动建表:
1、创建的Greenplum表将不会有distribution列,如下为GSC生成的建表语句:
CREATE TABLE "public"."rank_a1"
("id" INTEGER NOT NULL, "rank" TEXT, "year" INTEGER NOT NULL, "gender" INTEGER NOT NULL, "count" INTEGER NOT NULL);
2、创建的Greenplum表的字段名将会使用Spark DataFrame中的字段名。
3、在GSC自动建表时,将会为字段名加上双引号,这将使Greenplum区分大小写。
4、当Spark DataFrame的字段不为nullable时,GSC自动建表的字段将是 NOT NULL。
5、将会对应的Spark DataFrame字段类型映射为Greenplum的字段类型。参考,字段类型映射表。
7.3. 提前手动建表:
1.将Spark DataFrame的字段名的数据写至Greenplum表的对应的字段中。值得注意的是,GSC在做映射的时候,是严格区分大小写的。
2.写至Greenplum的字段的数据类型,与对应的Spark DataFrame一致,具体参见字段类型映射。
3.如果Spark数据中某列包含空数据,需确保对应的Greenplum表的列没有被指定为NOT NULL。
4.Greenplum表中建表时其字段顺序可以与Spark DataFrame中不一致。但Greenplum表中不能出现不存在在Spark DataFrame中的字段。如下例子:
// Greenplum 中的字段
CREATE TABLE public.rank_a1 (
id int4 NOT NULL,
"rank" text NULL,
"year" int4 NOT NULL,
gender int4 NOT NULL,
count int4 NOT NULL
)
DISTRIBUTED BY (id);
// Spark DataFrame中的字段
var df = Seq((2, "a|b", 2, 2, 2),(3, "a|b", 3, 3, 3)).toDF("id", "rank", "year", "gender")
// 在写数据至public.rank_a1表时,将会报错如下
Exception in thread "main" java.lang.IllegalArgumentException: requirement failed: The number of columns doesn't match.
Old column names (5): _1, _2, _3, _4, _5
New column names (4): id, rank, year, gender
at scala.Predef$.require(Predef.scala:224)
at org.apache.spark.sql.Dataset.toDF(Dataset.scala:435)
at org.apache.spark.sql.DatasetHolder.toDF(DatasetHolder.scala:44)
at com.lt.spark.greenplum.GreenplumWrite$.main(GreenplumWrite.scala:14)
at com.lt.spark.greenplum.GreenplumWrite.main(GreenplumWrite.scala)
确保指定的用户对于该表有读写的权限,自动建表,需要有建表的权限。
8. Troubleshooting
8.1. 端口相关问题

8.2. Greenplum连接数问题
当连接Greenplum的连接数接近Greenplum数据库配置的大连接数(max_connections)时。Spark application将会抛出 connection limit exceeded 错误。
排查过程:
查询Greenplum数据的大连接数:
postgres=# show max_connections;
max_connections
-----------------
250
(1 row)
查询当前连接Greenplum数据库的连接数:
postgres=# SELECT count(*) FROM pg_stat_activity;
查询指定的用户连接Greenplum数据的连接数:
postgres=# SELECT count(*) FROM pg_stat_activity WHERE datname='tutorial';
postgres=# SELECT count(*) FROM pg_stat_activity WHERE usename='user1';
查询Greenplum数据库空闲和活动的连接数:
postgres=# SELECT count(*) FROM pg_stat_activity WHERE current_query='<IDLE>';
postgres=# SELECT count(*) FROM pg_stat_activity WHERE current_query!='<IDLE>';
查询连接Greenplum数据库名,用户名,客户端地址,客户端ip,当前查询语句:
postgres=# SELECT datname, usename, client_addr, client_port, current_query FROM pg_stat_activity;
如果确认是Spark application使用连接数过多,则配置JDBC Connection Pooling相关参数,减少连接数。
8.3. Greenplum Database Data Length Errors
在使用Greenplum 4.x或5.x的时候,可能会报出“data line too long”错误。这是因为在Greenplum数据库中参数项“gp_max_csv_line_length”默认值是1M。需要登陆Greenplum master修改这个参数值,示例如下,通过gpconfig修改该参数的值为5M:
gpadmin@gpmaster$ gpconfig -c gp_max_csv_line_length -v 5242880
gpadmin@gpmaster$ gpstop -u
9. 类型映射表
9.1. Greenplum to Spark
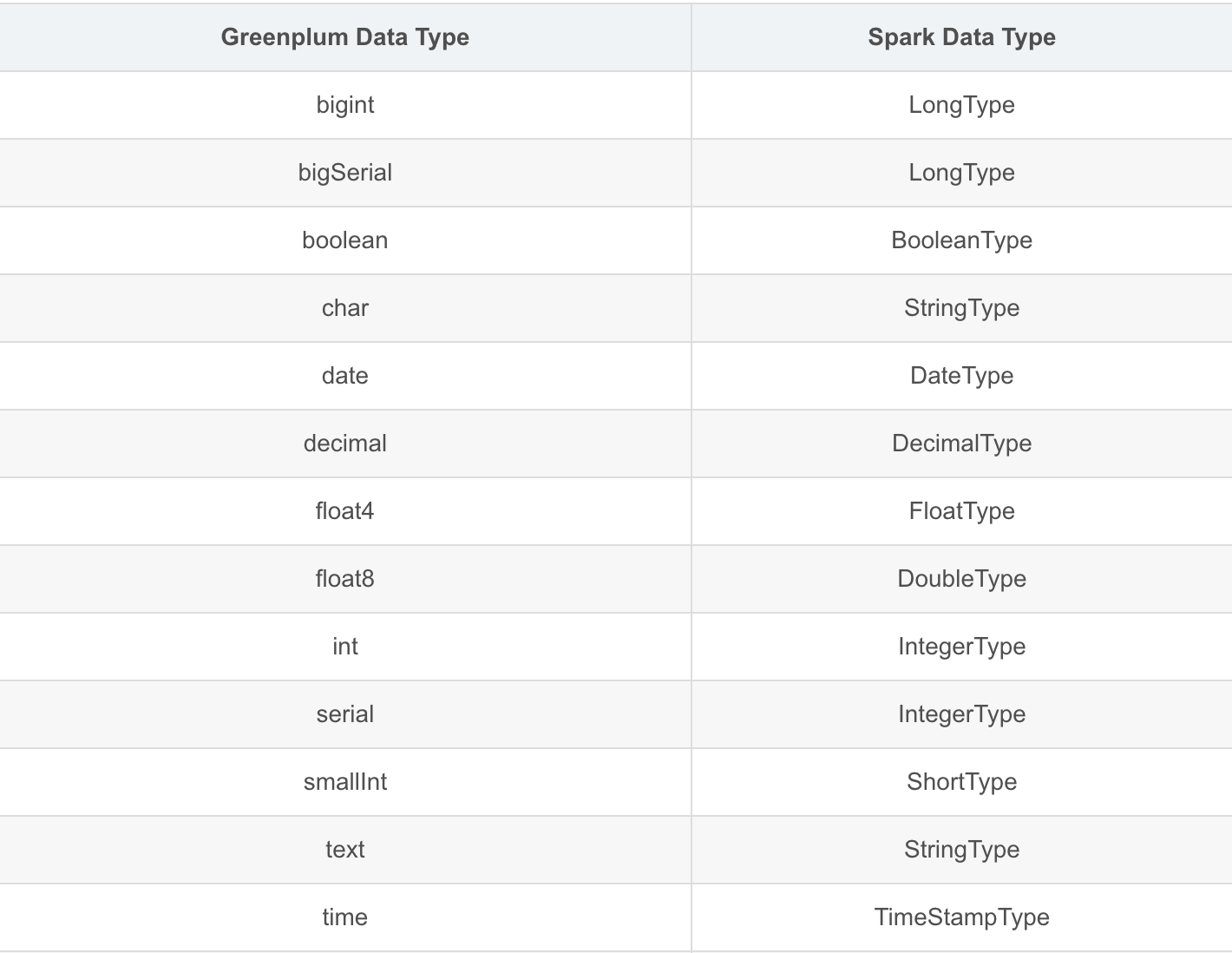

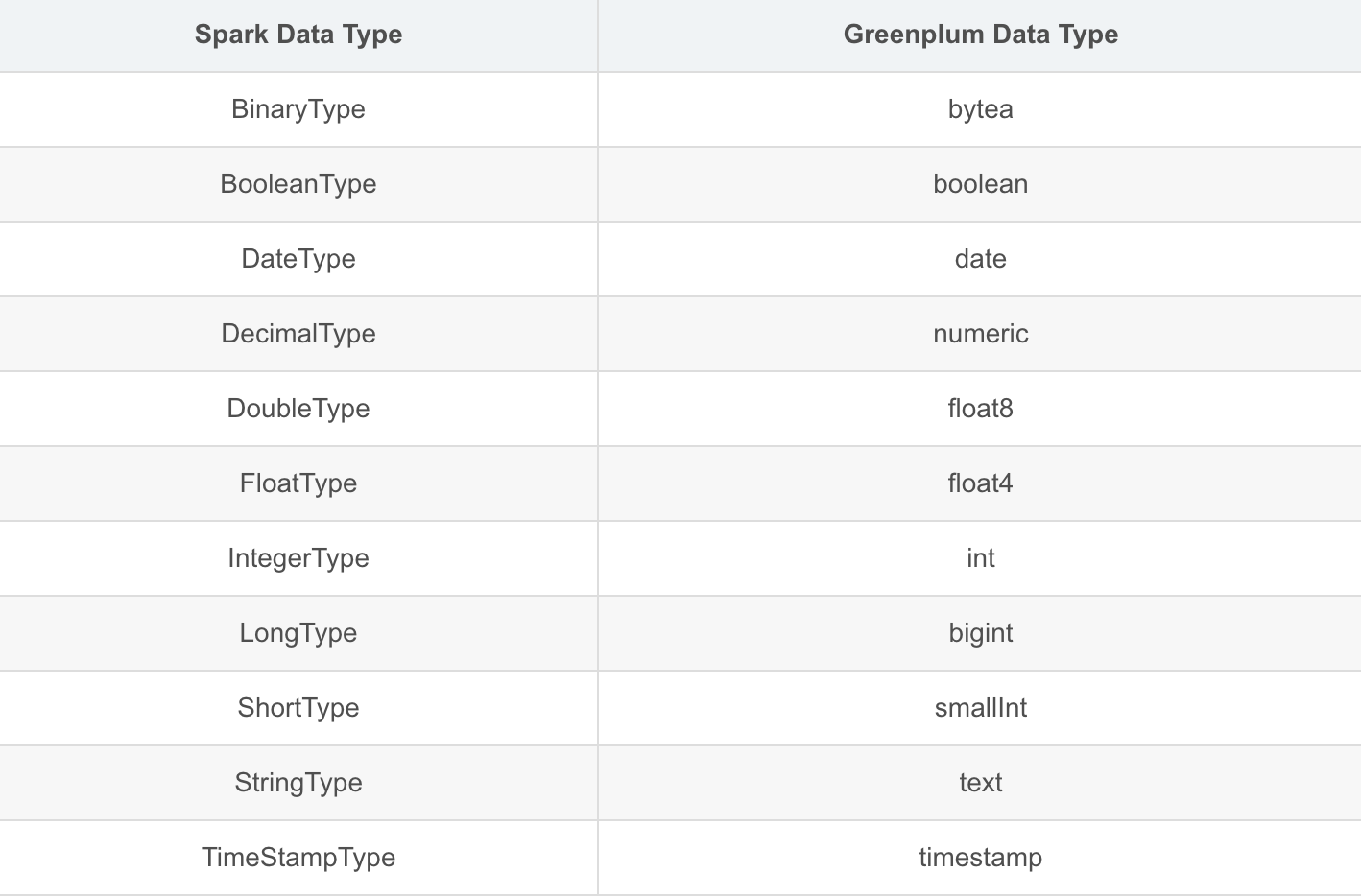
9.2. Spark to Greenplum
10. 参考
Greenplum-Spark Connector官方文档
Greenplum建表语句文档
Greenplum参数配置官方文档
本文来源:https://blog.csdn.net/ylltw01/article/details/104735721
