来自:https://mp.weixin.qq.com/s/hPsyTQURPpSxRBRvDQELTQ
LevelDB是一个基于磁盘的kv存储系统,他的作者是Google传奇工程师Jeff Dean和Sanjay Ghemawat,无论从代码的结构和系统的实现上,都很值得我们学习。
LevelDB因为是基于单机的,系统容量会有限制,在大规模的系统中很难使用。据我了解,阿里的tair中,底层的ldb存储使用了LevelDB,上面架了类似master角色,实现了一个分布式存储。
一 整体结构
leveldb和hbase一样,都是基于LSM-Tree结构,LSM-Tree将磁盘的随机写转化为顺序写,从而大大提高了写速度.
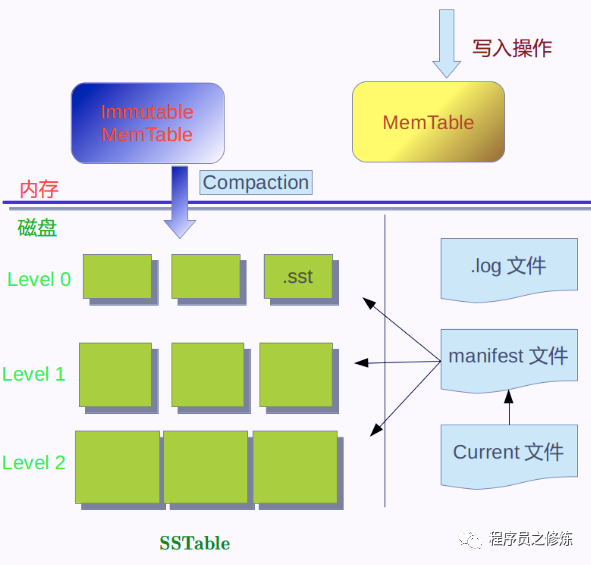
MemTable: 使用跳表实现的内存kv结构,里面的k按照顺序进行存储,所有新写入的数据都是写到这里的。
Immutable MemTable: 内存的数据会整体写入磁盘,在写入过程中,需要保持内存中的数据不变,这个不变的表就是immutable,他本质上还是一个MemTable,只是不能往里面写入数据了
SST文件:我们的数据都是存在这些文件中的,文件按照层进行划分,每个文件属于特定的一层,其中0层都是有immutable memtable写入磁盘生成的,其他层的文件都是有上一层的文件经过合并形成的。
log文件:数据写入时候,一开始是写入内存的,为了避免机器挂了,导致内存数据都是,所有的写操作都先往这个文件中写,万一数据都是,都可以通过这个日志文件进行恢复。
manifest:记录了sst文件的详细信息,文件属于哪一层、开始key、结束的key等信息,通过这个文件,可以快速定位需要查询的文件。
current:当前有效的manifest文件。
二 写入过程
具体过程:
写入log文件
写入memtable
回写磁盘,这个是达到memtable大小上限才触发
sst文件合并,这个也是达到sst文件数量的上限才触发
所以一般情况下,写入过程就只有1和2两个步骤,一个顺序写入磁盘,一个写入内存,都是非常高效,这个就是LevelDB高效的本质原因。
三 查询过程
依次从下面地方读取,如果读取到了,就直接放回了
memtable
immutable
-
sst文件
其中比较复杂的sst问题中查询,整体文件的信息都是在manifest中,可以通过这些信息定位到具体的sst文件,除了次直接从内存回写的,导致key有交叉情况,每个文件信息都需要判断下,其他层的都能快速定位到文件。
四 合并过程
随着系统的写入,不断的生成sst文件,文件数量越来越多了,刚才讲了查询过程,如果文件越多,查询的效率会越来越低;另外系统中的很多key,随着时间的推移,已经是失效了,但是他们还在文件中,浪费存储的空间,同时对查询的性能也有影响。
合并过程:sst文件是有序的,所以合并过程就是多路归并算法,归并后形成新的sst文件,同时把老的sst文件删除,后更新下manifest文件。这个过程主要进行磁盘的大量读取和写入过程,对系统还是有一定的影响的。
五 总结
基于磁盘的高效kv存储。因为是个单机系统,所以很难直接使用,不过中间实现思想、带来的实现都很值得大家学习。
