GeaBase (Graph Exploration and Analytics Database),是集图查询和图分析为一体的分布式图数据库,能为行业规模的应用程序提供实时图遍历和分析功能。先从论文中学习了解一下它吧….
摘要 Abstract
大规模图分析在过去几年中迅速发展,其拥有业内广泛的应用领域,从电子商务,社交网络和推荐系统到欺诈检测,几乎任何需要深入了解数据连接的问题,而不仅仅是数据本身。GeaBase是一个新式的分布式图数据库,能实时的存储和分析大规模图结构数据。它包含一个新奇的更新架构,叫做“更新中心UC”,一个新的适合图分析和遍历的图查询语言。它的查询性能是开源Titan的182倍,吞吐也高达22倍。
We present GeaBase, a new distributed graph database that provides the capability to store and analyze graph-structured data in real-time at massive scale. including a novel update architecture, called Update Center(UC), and a new language that is suitable for both graph traversal and analytics. We also compare the performance of GeaBase to a widely used open-source graph database Titan.
介绍 INTRODUCTION
引入图数据库以有效地存储和查询图。存储在图数据库中的图通常是属性图模型(顶点,边和属性)。图数据库的一个关键特性是边(或连接)被视为模型的核心组件以及顶点。因此,可以有效地检索复杂的拓扑结构。相反,对于传统的关系型数据库,数据之间的连接存储在单独的表中,搜索连接的查询需要连接操作,这种代价通常极高。
但是,为行业规模的应用设计高性能图形数据库具有挑战性:
First, irregular data structure of a graph usually leads to random access pattern to the storage system, and hence results in poor data locality; Second, in order to store a large scale of graph, the data is usually partitioned, which leads to high communication cost and imbalanced workloads; Finally, data consistency in a fast changing and distributed graph database is also very challenging.
首先,图的不规则数据结构通常会导致对存储系统的随机访问,从而导致数据局部性差; 其次,为了存储大规模的图形,数据通常被分区,这导致高通信成本和不平衡的工负载;后,快速变化的分布式图数据库中的数据一致性也非常具有挑战性。
GeaBase (Graph Exploration and Analytics Database),为行业规模的应用程序提供实时图遍历和分析功能。论文描述了GeaBase架构和实现的全部细节:GeaBase采用的技术,例如将计算移动到数据所在的位置,双队列更新管道和用户粘性,以及实现高性能和数据一致性等。
相关工作 RELATED WORK
长达10年的Neo4j是的开源图数据库,但是“scale-up only”难以拓展支撑超大规模的图,类似的还有Titan和Datastax等图数据库。
Typically employ standard graph query language like Gremlins[5] or SparQL [6]. These query languages have limited support of graph analytics. Offline graph analytics systems, such as those proposed in [7]–[10], are not able to update while processing queries or respond in real-time.
典型的标准图查询语言Gremlins和SparQL不支持图分析,而离线图计算系统,不支持实时的查询处理更新。
系统总览 SYSTEMOVERVIEW
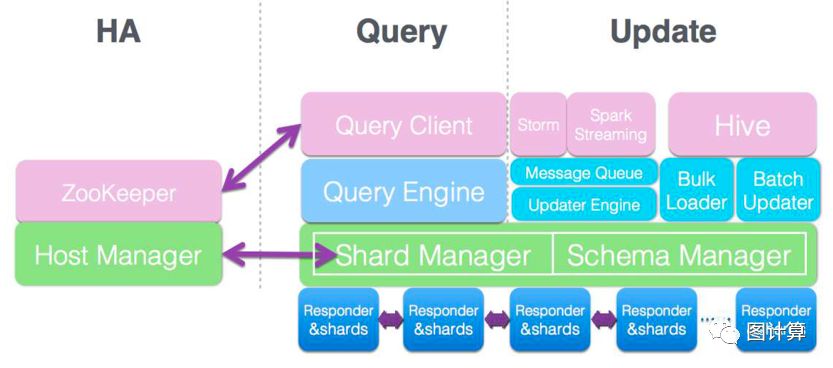
GeaBase系统架构图,四个模块:高可用模块、查询引擎、更新模块和图存储
A. 图存储 Graph Storage
在GeaBase中,顶点和边都被存储为键值对(key-value pairs)。属性被序列化并根据用户定义的模式(schema)存储在key-value pair的值部分中。根据基于散列的分片策略将记录存储在不同的分片中。通常,GeaBase实例包含由分片管理器(shardmanager)维护的数十或数百个分片。
1) 数据模型 Data Model: 图数据库基本的数据模型被描素为OLP(对象-关系-属性,object-link-property)。GeaBase被设计为支持大规模,多维度的图,包括顶点类型(typed-nodes),有向边(directed-typed-edges)以及它们的属性。
GeaBase的数据模型被描素为Graph Schema,包括一个顶点类型list和一个边类型list。Graph Schema中一个典型的顶点包含一个声明其类型的字段,以及一个表示该顶点的属性fileds的列表键值对。源顶点类型,目的顶点类型,边类型,属性列表和方向(有向或无向)都是Schema中有效顶点所需的。除了上面提到的基本要求之外,用户还可以向顶点和边添加可选字段(例如,生存时间字段)。总之,当给定特定的边或顶点类型时,可以从该Graph Schema中获知有关的拓扑结构和序列化格式。
2) 存储模型 Storage Model: 下图给出了GeaBase存储中键值的结构。特别的,一个顶点被存储为一个单一的key-value对,由顶点ID,顶点类型,和顶点属性组成。一个有向边被存储为两个key-value对,分别叫做OutEdge和InEdge,都由源顶点ID,边类型,目的顶点ID和边属性组成。可以将OutEdge视为前向索引(forward index),用于在给定源节点时搜索到目标的跟踪(称为出边导航)。InEdge可以被视为反向索引(reverse index),用于在给定目的顶点时搜索到源顶点的跟踪(称为入边导航)。所有的边类型,顶点类型和给定顶点或边的属性格式都在Graph Schema中指定。
为了节省存储空间,边属性可以存储在一个方向上,基本可以节约一半的空间。
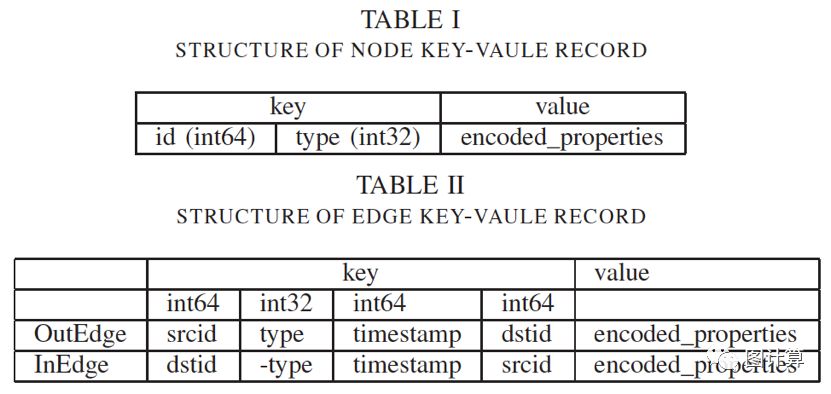
GeaBase的数据和存储模型
3) 分片策略 Sharding Strategy: 所有记录(records)都按key的前8个字节(int64)进行分片。顶点记录将由顶点ID分散,OutEdge记录将由源ID分散,而InEdge则按目的地ID分散。这种分片策略的动机是避免通过网络传输海量数据。在这种策略下,源顶点和源自它的所有OutEdges都位于相同分片中。这同样适用于目的节点和InEdges。因此,在前向forward遍历的情况下,可以在相同的分片中获取边和目的顶点的属性。
B. 高可用模块 High Availability Module
使用ZooKeeper服务实现GeaBase服务的可用性,方法是在ZooKeeper服务和所有GeaBase集群之间保持心跳。每个GeaBase集群都有一个完整的图数据副本,因此被命名为GeaBase副本。如果一个GeaBase服务器或一个副本崩溃,ZooKeeper和此服务器之间的心跳超时,然后从ZooKeeper中删除此服务器。当客户端和其他GeaBase服务器检测到此更改时,它们会将计算重定向到具有相应数据的其它服务器。
C. 更新模块 Update Module
GeaBase为数据更新提供实时(real-time)和批处(batch)理两种方式。
1) Real-time Update:
实时数据在业务决策,财务风险管理和其它行业分析领域变得越来越重要。例如,在电子商务中,实时用户操作数据(例如点击,收集,购买)对于构建用户配置文件和优化推荐效果至关重要。在金融领域,实时用户购买和交易数据是风险管理的基本资源。
实时更新模式如下图所示,可同时支持synchronous 同步模式和asynchronous 异步模式。
在同步模式下,upstream系统将更新事件转换为查询字符串,并将其直接发送到一个GeaBase服务器,并等待服务器以其更新状态发回响应。如果更新事件成功,则后续读取查询将获取新数据。当此模式与III-A中提到的用户粘性策略一起使用时,用户将始终获得一致的数据。
有时用户更关心更新吞吐而不是更新响应时间。upstream系统可以选择将更新事件转换为消息,然后将其放入分布式队列以供所有GeaBase副本异步使用。实际上,当不同区域中的多个分布式消息队列服务可用时,所选择的消息队列是与上游系统接近的消息队列。每个GeaBase副本的剩余作业都是不断消耗客户端排队的更新消息,这些消息来自所有区域中的所有消息队列。
某些应用程序不需要严格的更新顺序,并且它们需要高更新吞吐量。对于这些情况,GeaBase提供了一种实时更新的异步模式。上游系统将更新事件转换为消息,然后将其放入分布式队列,然后由所有GeaBase副本异步使用。
具体地,消息队列中的数据被分区,对应于III-A中描述的GeaBase分片策略,并且每个GeaBase服务器订阅subscribes消费与其保持的分片对应的队列的分区。这种架构保证了弱消息序列。在每个分区中,消息序列由接收消息的顺序确定。但是,跨分区不保证序列。共享相同密钥ID的节点或边缘消息将被发送到同一队列分区,因此,根据其发送顺序处理同一节点或边缘上的添加/更新/删除操作。
三个缺点: First, it does not ensure data consistency between replicas 不能保证副本一致性.Second, the message encoding procedure is done repeatedly for each replicas,which wastes valuable CPU resource 消息被重复编码,浪费CPU资源. Third, there are too many queue consumers, and this would increase the pressure on the queue servers 有很多的消费队列,会使MQ集群压力大.
解决方案:更新中心架构被提出(update center architectureis proposed). 选择一个MQ副本作为update center即master queue. 用来消费队列和存储用户生成的消息;将编码后的消息存储下来并发送给其它的slave queue;所有其它的副本消费slave queue并相应的更新存储。
好处:通过这种方式,所有副本始终使用相同的数据,从而确保数据的一致性。此外,编码过程仅在更新中心执行。还值得一提的是,更新中心可以切换到任何其他副本,因为它们之间的区别是它们使用不同的消息队列。
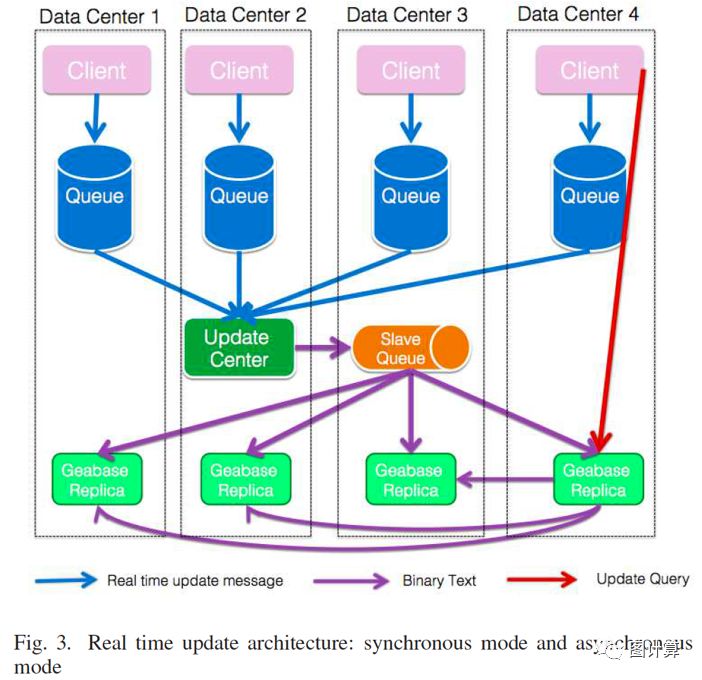
实时更新架构:同步和异步模式
2) 批更新 Batch Update:
批更新如下图所示,常用于从数据仓库导入批量计算结果图。数据仓库中的数据通常格式化为表格。我们要求所有表都包含以下元素:键key ID,值value和标记tag。标记表示特定的更新方法,例如添加,删除,更新。 GeaBase对表进行分片,每个服务器读取一个表的子集并相应地更新数据库。

批更新架构: Batch center architecture
D. 查询引擎 Query Engine
1) 引擎结构 Engine Structure: query engine design principles is to perform computation at where data is.(准则:数据在哪计算就在哪). 查询处理流程:检查查询语句的语法;生成一个遍历或计算的计划;当查询需要非本地数据时,查询引擎会生成一个子查询,该子查询检索远程数据,并通过内部请求将子查询发送到目标节点所在的服务器。如果不需要内部请求,则遍历计划结束,结果数据将发送回客户端。
2) 查询语言 Query Language: 支持三类操作,还包括内置(build-in)和用户自定义( user-defined)方法以体现系统灵活性。
图的增删改查操作 graph CRUD operations: GetNodeProp (get nodes properties), GetEdgeProp (get edges properties), Nav(igation) (graph navigation),GetDistance, Limit, Add/ Delete Node/Edge
图遍历和计算 traversal, computation: Sort, Union, Subtract, Combine (setoperations), Agg(group by), For (iterations), variables
图分析 analysis: FindLoop, ShortestDistance, KCore, et al.
The GeaBase query language has a LISP lik grammar that looks like:
( operator [ :ATTR=value ] ) * where [:ATTR=value] can be as ub-query.
3) Nav: Like select clause in SQL. 类似于SQL的select子句
(Nav :DATA=(Nav :START=123
:EDGE_TYPE="friend"
:RETURN=@name,@age
:FILTER=@age>40)
:EDGE_TYPE="family "
:RETURN=$0, $1 , @location , @city
)
实验 EXPERIMENTS
通过一组查询说明GeaBase的延迟,吞吐量和可伸缩性,主要使用Twitter(1.47 billion social relations graph)数据集与开源图数据库Titan做对比。为了充分测试性能,在每条边上添加了四个属性:含十多个字符的短字符串属性,含一百个字节的长字符串属性,一个int64属性和每个边一个double属性。
低延迟:
首先,GeaBase可以通过数据聚类(即,存储在一起的每个节点的所有边)实现更好的数据局部性,并采用将计算移动到数据所在的策略。另一方面,Titan需要在复合索引中搜索起始节点ID以查找全局ID,然后找到ID的HBase行,其中存储了属性。另一方面,所有属性键和节点ID都存储在同一名称空间中,因为Titan中只有一个表,这将降低查询速度。
此外,在two-hop遍历中,Titan将每个查询拆分为具有相同连接的RPC调用序列。HBase在JVM上运行,垃圾收集(GC)无法控制。虽然GeaBase完全是用C++编写的,但没有这个问题。
后,GeaBase和Titan之间的性能差距对于four-hop查询案例来说更小。这是因为对于four-hop查询,通信成本远高于one-hop查询的情况,其中工作者之间没有通信。对于Titan而言,与上述原因相比,内部沟通并不是一个重要因素。因此,GeaBase和Titan之间的性能差距较小,因为在相同的网络下,通信成本是相似的。

高吞吐:
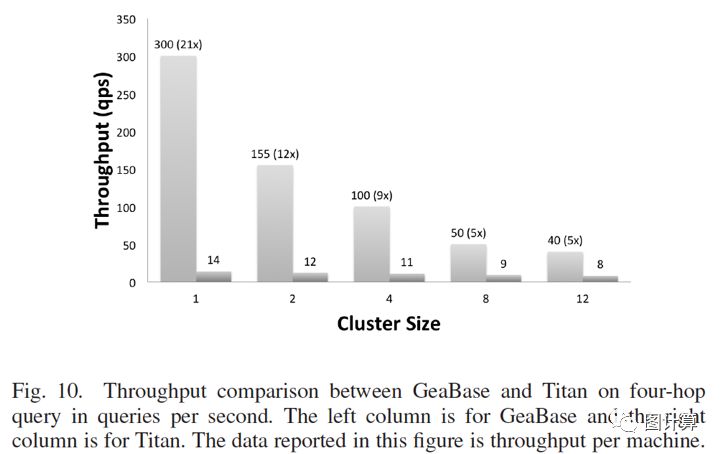
伸缩性:GeaBase实现了one-hop查询几乎线性的系统伸缩能力。对于two-hop和four-hop情况,由于数据分片,GeaBase引擎需要向其它服务器发送远程查询,因此通信成本要高得多,导致可拓展性差。GeaBase试图通过根据目标服务器对节点进行分组来小化通信成本。

[1] GeaBase: AHigh-Performance Distributed Graph Database for Industry-Scale Applications
[2] https://www.cloud.alipay.com/docs/2/74240
来源 https://www.modb.pro/db/150617
