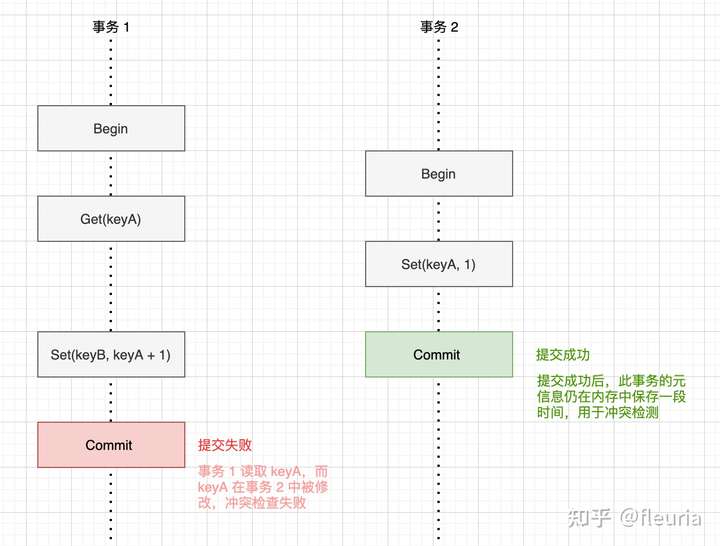
badger 实现了 Serializable Snapshot 隔离级别(简称 SSI)的乐观并发控制的事务,相比 Snapshot 隔离级别(简称 SI),SSI 除了跟踪写操作进行冲突检测,也会对事务中的读操作进行跟踪,在 Commit 时进行冲突检查,当前事务读取过的数据,如果在事务执行的期间被其他事务修改过,则会提交失败:
事务的生命周期
乐观并发控制事务的生命周期大致上分为四段,授时、跟踪读写、提交、清理:
- 事务启动:获取事务开始时刻的授时
- 事务过程:跟踪事务的读写操作涉及到的 key,事务期间读操作按启动时刻的快照为准,事务中的写入内容在内存中暂存
- 事务提交:根据事务中跟踪的 key 进行冲突检测,获取事务提交时刻的授时,使写入生效
- 清理旧事务:当活跃的事务完成后,可以使已经不再需要的快照数据、冲突检测数据等事务相关数据得到释放
为了管理事务的生命周期,需要为每个事务和全局层面记录两部分元信息:
- 每个事务层面,需要记录自己读写的 key 列表,以及事务的开始时间戳和提交时间戳,这部分信息维护在 Txn 结构体中
- 全局层面,需要管理全局时间戳,以及近提交的事务列表,用于在新的事务提交中对事务开始与提交时间戳中间提交过的事务范围进行冲突检查,乃至当前活跃的事务的小时间戳,用于清理旧事务信息,这部分信息维护在 oracle 结构体中
这里授时得到的时间戳并非物理时间,而是逻辑上的:所有的数据变化均来自事务提交的时刻,因此仅当事务提交时使时间戳递增。
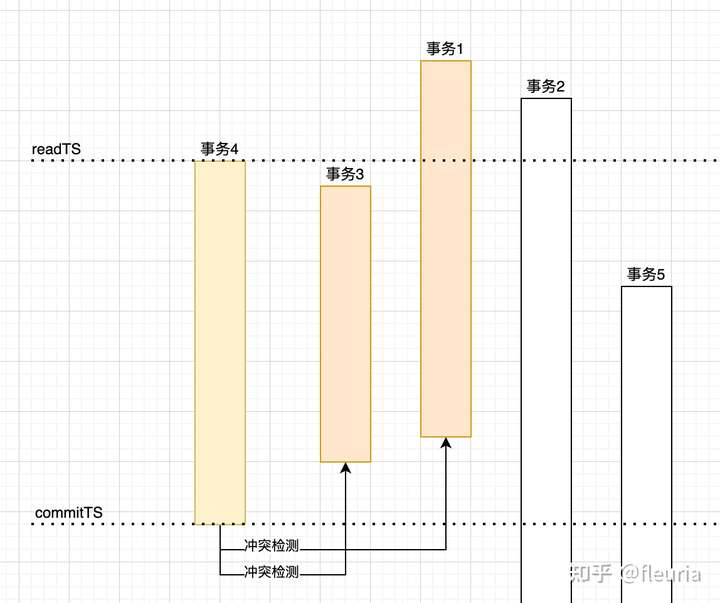
以上面的图为例,事务 4 在提交时需要与事务 3 和事务 1 进行冲突检测,因为事务 3 和事务 1 的提交时间位于事务 4 的开始与提交之间,事务 3 和事务 1 写入的 key 如果与事务 4 读写的 key 列表存在重叠,则认为存在冲突。
接下来我们顺着这四段生命周期,过一下 badger 中的相关过程。
事务开始
启动一个新事务的入口在 db.newTransaction() 函数。这个函数比较简单,除了初始化几个字段,有行为语义的部分就是 txn.readTs = db.orc.readTs() 这一行申请授时的地方了。
看一下 readTs() 函数的实现:
func (o *oracle) readTs() uint64 {
// 忽略 isManaged 部分逻辑
var readTs uint64
o.Lock()
readTs = o.nextTxnTs - 1
o.readMark.Begin(readTs)
o.Unlock()
// Wait for all txns which have no conflicts, have been assigned a commit
// timestamp and are going through the write to value log and LSM tree
// process. Not waiting here could mean that some txns which have been
// committed would not be read.
y.Check(o.txnMark.WaitForMark(context.Background(), readTs))
return readTs
}
授时的逻辑很简单,直接复制来自 oracle 对象的 nextTxnTs 字段中记录的当前时间戳即可。
这里有一个细节,前面提到时间戳的递增发生于事务的提交,会存在一个时间戳递增了但写入仍未落盘的时间窗口,导致事务在这时开始的话,会读到旧数据而非时间戳后的快照。解决办法就是启动事务前,先等待当前时间戳的事务完成写入。
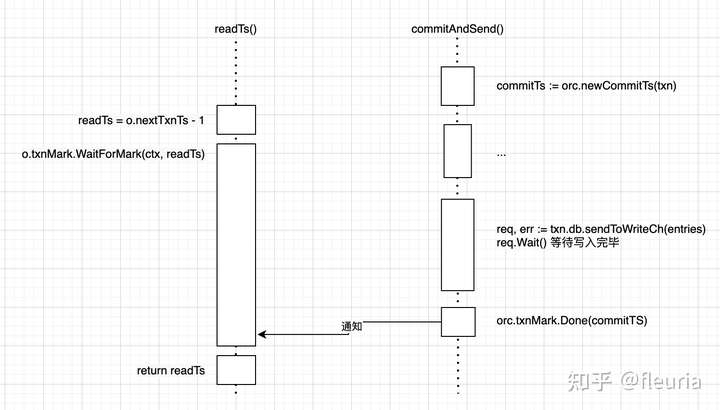
txnMark 字段是 WaterMark 结构体类型,它内部会维护一个堆数据结构,可以用于跟踪事务的时间戳区段的变化通知。
除了基于 txnMark 等待当前时间戳相关的事务完成写入,readTs 函数中还有一行 o.readMark.Begin(readTs)。readMark 与 txnMark 一样是一个 WaterMark 结构体,但它没有利用 WaterMark 结构体等待点位的能力,只利用它的堆数据结构来跟踪当前活跃的事务的时间戳范围,用于找出哪些事务可以过期回收。
事务执行
事务执行期间,写入会暂存在内存的 pendingWrites 缓冲中。managed 模式下,如果在事务中对同一个 key 写入多次,会将本事务内插入的历史版本数据存入 duplicateWrites 缓冲,这里先忽略 duplicateWrites 字段。
事务期间的读取操作会首先读取 pendingWrites 缓冲,随后再读取 LSM Tree 内的数据。badger 继承了 leveldb 中 iterator 组合的思想,把 pendingWrites 的读取链路封装为了 Iterator,并与 MemTableIterator、TableIterator 等 Iterator 通过 MergeIterator 组合为终的 Iterator:
// NewIterator returns a new iterator. Depending upon the options, either only keys, or both
// key-value pairs would be fetched. The keys are returned in lexicographically sorted order.
// Using prefetch is recommended if you're doing a long running iteration, for performance.
//
// Multiple Iterators:
// For a read-only txn, multiple iterators can be running simultaneously. However, for a read-write
// txn, iterators have the nuance of being a snapshot of the writes for the transaction at the time
// iterator was created. If writes are performed after an iterator is created, then that iterator
// will not be able to see those writes. Only writes performed before an iterator was created can be
// viewed.
func (txn *Txn) NewIterator(opt IteratorOptions) *Iterator {
if txn.discarded {
panic("Transaction has already been discarded")
}
if txn.db.IsClosed() {
panic(ErrDBClosed.Error())
}
// Keep track of the number of active iterators.
atomic.AddInt32(&txn.numIterators, 1)
// TODO: If Prefix is set, only pick those memtables which have keys with
// the prefix.
tables, decr := txn.db.getMemTables()
defer decr()
txn.db.vlog.incrIteratorCount()
var iters []y.Iterator
if itr := txn.newPendingWritesIterator(opt.Reverse); itr != nil {
iters = append(iters, itr)
}
for i := 0; i < len(tables); i++ {
iters = append(iters, tables[i].sl.NewUniIterator(opt.Reverse))
}
iters = append(iters, txn.db.lc.iterators(&opt)...) // This will increment references.
res := &Iterator{
txn: txn,
iitr: table.NewMergeIterator(iters, opt.Reverse),
opt: opt,
readTs: txn.readTs,
}
return res
}
badger 会将 commitTs 作为 key 的后缀存储到 LSM Tree 中,Iterator 在迭代中也会对时间戳有感知,按 readTs 时刻的快照数据进行迭代。这里与 leveldb 的 sequence 号与 Snapshot 的迭代行为是一致的。
事务提交
事务的提交入口位于 Commit() 函数,它调用的 commitAndSend() 函数是逻辑的主体。大致上的过程包括:
- 通过 orc.newCommitTs(txn) 进行事务冲突检测,如果无冲突,获取授时 commitTs
- 循环为 pendingWrites 和 duplicateWrites 中的 Entry 的 version 绑定 commitTs,并使存储的 key 绑定 commitTs
- 调用 txn.db.sendToWriteCh(entries) 使写入缓冲进入落盘写入
- 等待落盘完成后,通知 orc.doneCommit(commitTs),移动 txnMark 的点位
newCommitTs 内部会发起冲突检测和过期事务清理,并使事务跟踪到 commitedTxns 中:
func (o *oracle) newCommitTs(txn *Txn) uint64 {
o.Lock()
defer o.Unlock()
if o.hasConflict(txn) {
return 0
}
var ts uint64
o.doneRead(txn)
o.cleanupCommittedTransactions()
// This is the general case, when user doesn't specify the read and commit ts.
ts = o.nextTxnTs
o.nextTxnTs++
o.txnMark.Begin(ts)
y.AssertTrue(ts >= o.lastCleanupTs)
if o.detectConflicts {
// We should ensure that txns are not added to o.committedTxns slice when
// conflict detection is disabled otherwise this slice would keep growing.
o.committedTxns = append(o.committedTxns, committedTxn{
ts: ts,
conflictKeys: txn.conflictKeys,
})
}
return ts
}
其中冲突检测的逻辑很简单,遍历 committedTxns,找出当前事务开始之后提交的事务,判断自己读到的 key 中,是否存在于其他事务的写列表中:
// hasConflict must be called while having a lock.
func (o *oracle) hasConflict(txn *Txn) bool {
if len(txn.reads) == 0 {
return false
}
for _, committedTxn := range o.committedTxns {
// If the committedTxn.ts is less than txn.readTs that implies that the
// committedTxn finished before the current transaction started.
// We don't need to check for conflict in that case.
// This change assumes linearizability. Lack of linearizability could
// cause the read ts of a new txn to be lower than the commit ts of
// a txn before it (@mrjn).
if committedTxn.ts <= txn.readTs {
continue
}
for _, ro := range txn.reads {
if _, has := committedTxn.conflictKeys[ro]; has {
return true
}
}
}
return false
}
事务清理
前面提到事务在提交时会结合 committedTxns 数组中的信息,进行冲突检测。committedTxns 数组记录近期的已提交事务的信息,显然是不能无限增长的。那么何时可以对 committedTxns 数组进行清理呢?标准就是早的活跃的事务的开始时间戳,如果历史事务的提交时间戳早于当前活跃的事务的开始时间戳,冲突检查时就不需要考虑它了,也就可以在 committedTxns 中回收它了。
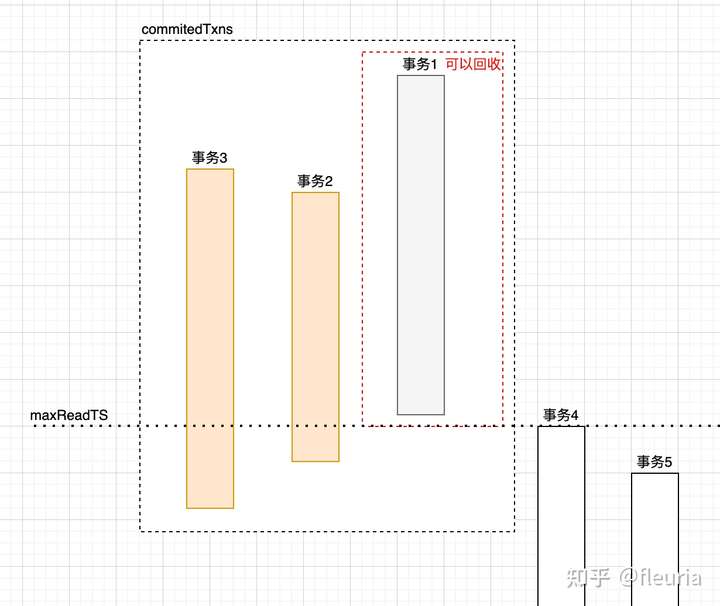
func (o *oracle) cleanupCommittedTransactions() {
// Must be called under o.Lock
if !o.detectConflicts {
// When detectConflicts is set to false, we do not store any
// committedTxns and so there's nothing to clean up.
return
}
// Same logic as discardAtOrBelow but unlocked
var maxReadTs uint64
if o.isManaged {
maxReadTs = o.discardTs
} else {
maxReadTs = o.readMark.DoneUntil() // 在 readMark 堆中获取当前活跃事务的早 readTs
}
y.AssertTrue(maxReadTs >= o.lastCleanupTs)
// do not run clean up if the maxReadTs (read timestamp of the
// oldest transaction that is still in flight) has not increased
if maxReadTs == o.lastCleanupTs {
return
}
o.lastCleanupTs = maxReadTs
tmp := o.committedTxns[:]
for _, txn := range o.committedTxns {
if txn.ts <= maxReadTs {
continue
}
tmp = append(tmp, txn)
}
o.committedTxns = tmp
}
oracle 会记录 lastCleanupTs 记录上次清理的时间戳,避免不必要的清理操作。
总结
- badger 中与事务相关的结构体包括 Txn 和 oracle 两个,Txn 内部的信息主要是开始时间戳、提交时间戳、读写的 key 列表,oracle 相当于事务管理器,内部维护近期提交的事务列表、全局时间戳、当前活跃事务的早时间戳等。
- 事务时间戳是逻辑时间戳,每次事务提交时递增 1。
- SSI 事务中冲突探测的逻辑就是,找出在当前事务执行期间 Commit 的事务列表,检查当前事务读取的 key 列表是否与这些事务的写入的 key 列表有重叠。
- WaterMark 结构体内部是个堆,用于管理、查找事务开始、结束的区段。oracle 的 txnMarker 主要用于协调等待 Commit 授时与落盘的时间窗口,readMarker 管理当前活跃事务的早时间戳,用于清理过期的 committedTxns。
