
接上期,上期的连接在文字下方,上期已经分别对 MYSQL PS 的 threads , instrumnents , consumers 进行了说明和相关的配置方式进行了说明,本期需要继续对PS中的监控信息体系中的events 进行说明, events 是PS 中对于 instruments 标签记录的结果,也就是终我们要看的结果都是体现在events 中, events 中包含了 四个层次, transactions , statements , stages , waits 这 四个方面,
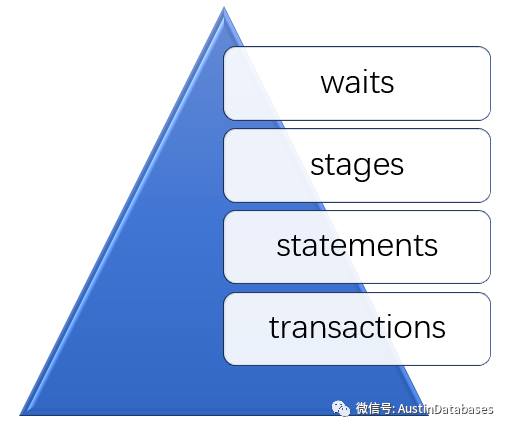
事务: 在events中的事务是针对事务的隔离级别,事务的状态,等信息进行记录,针对每个连接的threads 的事务进行记录,默认为当前的10个事务进行收集。
语句:这部分是普通监控者关注的部分,一般关于慢查询的信息也可以从这部分取出,而不用在使用slow query log + pt-query-digest + 流式数据记录到数据表的方式,当然这里需要熟悉statemnts 中的一些参数以及获取信息的方式。这里的信息包含一个语句执行了多少行,返回了多少信息行,以及是否使用了INDEX ,执行的时间等等信息,这个方式和 POSTGRESQL 的 pg_stat_statements 是类似的。 随时你 可以获知你的语句执行的情况,同样默认的情况,会保留近的10条语句。
stage:这里包含了 show processlist 的信息。
waits: 这部分包含的信息很多,包含多个mutexes的等待信息,例如 I/O 的等待信息针对系统中各个部分的mutexe, 但如果想看懂这部分信息,需要对提供的参数含义有明确的了解,但这不是很容易的一件事,可以从一些关键的信息入手。
上面的是events的 横向的维度, 那么纵向的维度,就是 current , history , history-long 这几个项目了, current 就是刚才提到的,每种维度的信息大概默认都是保留近10条, history 保留的是一个历史的信息保证系统在出现故障重启后,你还能获得刚才已经丢失的信息,history-long 则是可以设置保留这些信息大的容量,一般默认是10000条。
所以到此为止,如通你从期看的话,你就明白为什么次对于instruments 要进行设置,而不是 直接去全部OPEN。
但实际上这样的问题并不单纯,每个事件本身可能是事务中的某个部分,这就造成事件发生后,还会有上一层就是触发他发生问题的另一个时间。
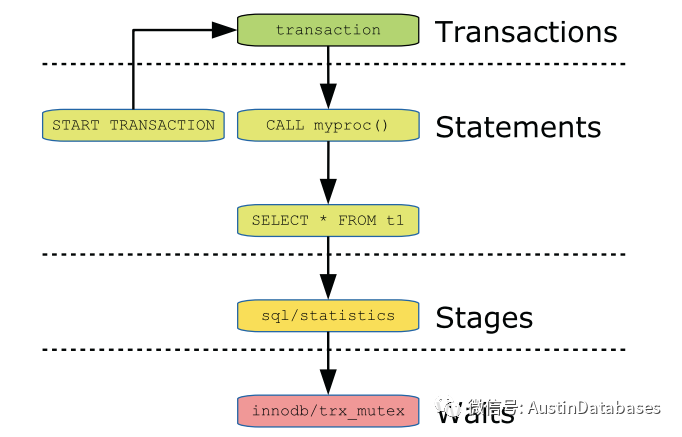
在这些events中会有 nesting_events_id nesting_event_type 来这对这个时间是否存在上一个父时间,或关联时间进行注释。所以可以针对表写出递归查询。
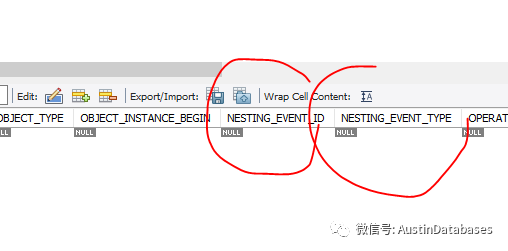
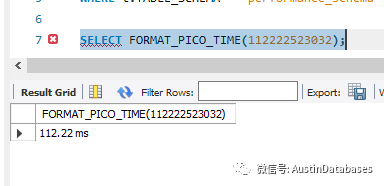
对于事件中的信息,包含了 timer_start, time_end, timer_wait 等信息,从中可以判断这个事务等待的时间,何时开始,合适结束。对于其中使用的时间单位,皮秒可以使用提供的 format_pico_time 函数来解决,将其转换为可以识别的人类时间。这个函数是在MYSQL 8.016 提供的,所以使用MYSQL 8 的情况下,尽量使用更新的版本目前新的版本是 8.027
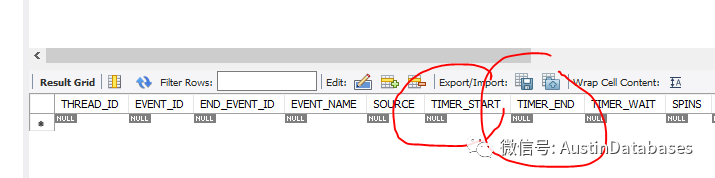
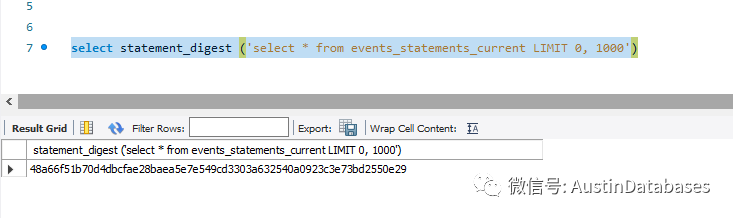
同时举例如events_statements_current ,通过这个表可以查看当前正在执行的语句中的后10条,这里使用了一项类似PT-QUERY-DIGEST 的技术,就是针对语句进行分类, 语句的条件是变化的,但语句的结构是一致的,可以通过 statment_digest 函数针对你想要查询的语句进行 digest 码的生成,可以瞬间找到类似的语句,以及计算整体这样的语句的数量。

通过函数 statement_digest 来计算每个语句的 digest 值,通过这个值可以对比结构类似条件不一致的语句。
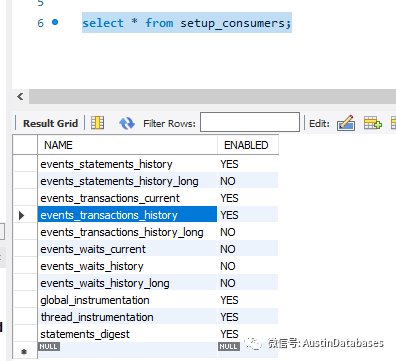
通过可以通过performance_schema 中的setup 表对于其中获取信息的组件进行信息的停止收集和打开。
对于SETUP 表,直接使用UPDATE 语句对其中的ENABLED值进行改变

MYSQL 从performance_schema说起,但不止于PS (1)
https://mp.weixin.qq.com/s?__biz=Mzg4NDA0NTEwNA==&mid=2247494482&idx=1&sn=c6fd81b9a6303df9285147d9b87df5cd&chksm=cfbc8f0df8cb061b019945d3d523bb32f563edde3b2914a907e571a09461668a9b5f60561bda&token=1980463622&lang=zh_CN#rd
