在boltdb中,核心的数据结构当属B+树了。B+树是数据库或文件系统中常见的数据结构,它的特点是能够保证数据稳定有序,因为每个叶子节点的深度都相同,因此其插入和修改操作拥有较稳定的时间复杂度。
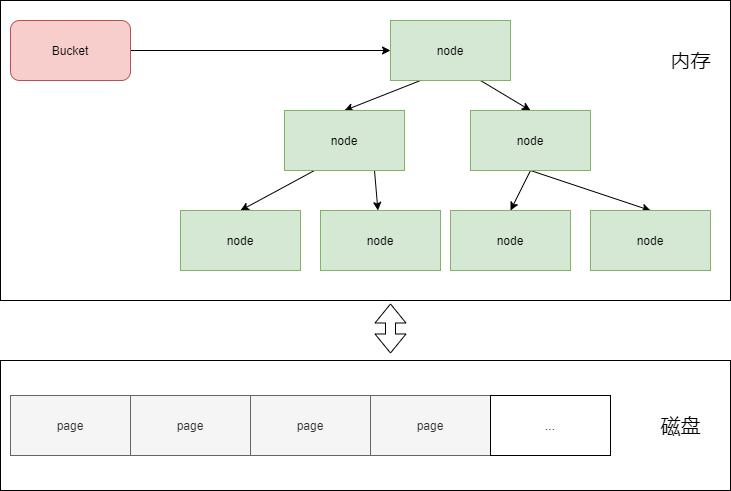
那么boltdb中B+树的节点是如何表示的呢?答案是node。node对应page在内存中的数据结构,node序列化之后便是page,page反序列化之后是node。因为node在内存中,且node对应B+树的一个节点
在概念上,boltdb中的一个Bucket对应一棵B+树。如下图所示
node
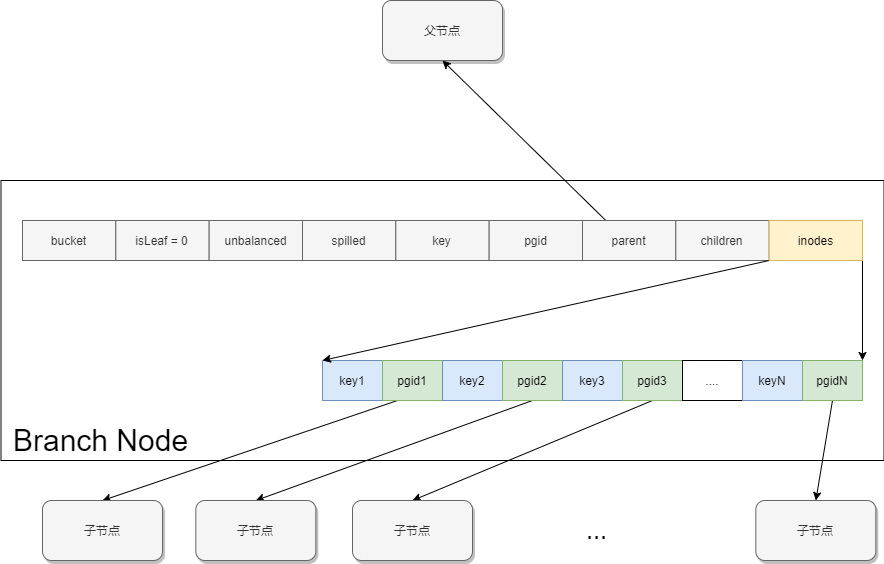
node分为两种,branch node和leaf node。
branch node如下所示,需要注意的是,boltdb中的branch node与通常的B+树略有不同,通常B+树中branch node的key数量比子节点数量多1, 而boltdb中key和子节点是一一对应的,这里应该是出于简化设计的考虑。因此在boltdb的branch node中,子节点i子树中的key应当介于key(i)和key(i+1)之间,左闭右开。
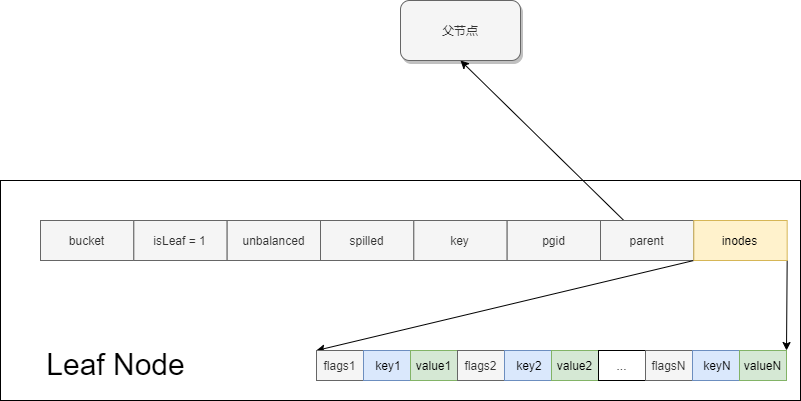
leaf node如下所示。我们注意到叶子节点的数据除了key和value之外,还有一个flags,它的作用是为了区分普通数据和子Bucket数据。当flags != 0时,key为当前Bucket下的子Bucket名,value可反序列化为bucket结构,其中记录着子Bucket对应B+树的根节点所在的page id。稍后在Bucket一节中我们将会深入探讨。
node代码如下:
type nodes []*node
// inode represents an internal node inside of a node.
// It can be used to point to elements in a page or point
// to an element which hasn't been added to a page yet.
type inode struct {
flags uint32
pgid pgid
key []byte
value []byte
}
type inodes []inode
// node represents an in-memory, deserialized page.
type node struct {
bucket *Bucket
isLeaf bool
unbalanced bool
spilled bool
key []byte
pgid pgid
parent *node
children nodes
inodes inodes
}
node中的成员变量:
bucket: 当前节点所属的Bucket(直属bucket, 不包含祖先)isLeaf: 当前节点是否为叶子节点unbalanced: 表示该节点是否有可能被合并。如果从node中去掉了某对kv数据, 则unbalance从false变成true。合并策略见spilled: 表示该节点是否已经被拆分。在一个写事务中,已拆分的节点不会再被拆分。当node中插入数据,导致node中数据大小超过一定阈值时,便会触发node的拆分,pgid: 该node对应page的page idparent: 当前节点的父节点inodes: 本节点内的key/value数据对。对于叶子节点来说,key和value都存在。对于非叶子节点来说,只有key存在。key:inodes中所有key/value数据中小的keychildren: 当前节点的所有子节点。如果当前节点是非叶子节点,则len(inodes) = len(children); 如果当前节点是叶子节点,则children为空
node中的成员函数:
minKeys: node允许存在的少key数量(leaf node情况下为1。branch node情况下为2)size: 返回node序列化成page之后的字节数,boltdb中以此判断当前节点是否需要分裂或合并sizeLessThan: 判断node序列化之后大小是否小于给定大小。出于性能考虑,实现中做了提前返回,比直接调用node.size并判断是否小于给定大小要快pageElementSize: 当前节点为leaf node时,返回leafPageElementSize, 即一个leafPageElement对象的长度;当前节点为branch node时,返回branchPageElementSize, 即branchPageElement对象的长度。childAt: 返回第index个子节点。实现上,首先从inodes中拿到子节点的page id, 然后从bucket中根据page id进行索引,终返回子节点对应的node对象childIndex: 输入child node, 从inodes数组中二分查找该child node的位置。注意这里之所以能使用二分查找是因为inodes中所有元素都是按照key进行升序排列的numChildren: 返回当前节点的子节点数量nextSibling: 当前节点的右兄弟节点,如果没有返回nil。实现上,首先调用node.childIndex判断当前节点在其父节点中的位置index,然后返回父节点index+1位置的子节点prevSibling: 当前节点的左兄弟节点,如果没有返回nil。实现上类似nextSibling。
node的序列化: node -> page
node.write: 将node对象序列化到page中
序列化步骤:
- 根据
node.isLeaf设置page.flags - 检查
inodes数组长度是否超过上限0xFFFF,超过则panic(因为B+树的分裂策略,这种情况不可能发生,除非有脏数据) - 将
inodes中的数据复制到page.ptr所指向的缓冲区中。如果node是leaf node, 则page缓冲区中写入的是[]leafPageElement和所有key/value对。如果node是branch node, 则page缓冲区中写入的是[]branchPageElement和所有的key值。
for i, item := range n.inodes {
_assert(len(item.key) > , "write: zero-length inode key")
// Write the page element.
if n.isLeaf {
elem := p.leafPageElement(uint16(i))
elem.pos = uint32(uintptr(unsafe.Pointer(&b[])) - uintptr(unsafe.Pointer(elem)))
elem.flags = item.flags
elem.ksize = uint32(len(item.key))
elem.vsize = uint32(len(item.value))
} else {
elem := p.branchPageElement(uint16(i))
elem.pos = uint32(uintptr(unsafe.Pointer(&b[])) - uintptr(unsafe.Pointer(elem)))
elem.ksize = uint32(len(item.key))
elem.pgid = item.pgid
_assert(elem.pgid != p.id, "write: circular dependency occurred")
}
// If the length of key+value is larger than the max allocation size
// then we need to reallocate the byte array pointer.
//
// See: https://github.com/boltdb/bolt/pull/335
klen, vlen := len(item.key), len(item.value)
if len(b) < klen+vlen {
b = (*[maxAllocSize]byte)(unsafe.Pointer(&b[]))[:]
}
// Write data for the element to the end of the page.
copy(b[:], item.key)
b = b[klen:]
copy(b[:], item.value)
b = b[vlen:]
}
node的反序列化:page -> node
node.read: 从page对象初始化node,即page反序列化成node
反序列化步骤如下:
- 复制page id到node中
- 根据
page.flags确定node.isLeaf - 将page缓冲区中的数据复制到
node.inodes中。branch page还是leaf page两种情况下数据格式略有不同。
// read initializes the node from a page.
func (n *node) read(p *page) {
n.pgid = p.id
n.isLeaf = ((p.flags & leafPageFlag) != )
n.inodes = make(inodes, int(p.count))
for i := ; i < int(p.count); i++ {
inode := &n.inodes[i]
if n.isLeaf {
elem := p.leafPageElement(uint16(i))
inode.flags = elem.flags
inode.key = elem.key()
inode.value = elem.value()
} else {
elem := p.branchPageElement(uint16(i))
inode.pgid = elem.pgid
inode.key = elem.key()
}
_assert(len(inode.key) > , "read: zero-length inode key")
}
// Save first key so we can find the node in the parent when we spill.
if len(n.inodes) > {
n.key = n.inodes[].key
_assert(len(n.key) > , "read: zero-length node key")
} else {
n.key = nil
}
}
插入数据
node.put: 向当前节点中插入key/value。pageid和flags这两个输入参数是相关的,当flags不为零时,表示这对kv是Bucket数据,此时pageid是其bucket的root page。当flags为零时,pageid没有意义,此时这对kv就是普通数据。
实现上:
- 首先从当前节点的
inodes二分搜索-key/value对插入位置index。 - 如果
inodes中存在等值的key, 则覆盖其value - 如果
inodes中不存在等值key, 则在index位置处插入一个inode
// put inserts a key/value.
func (n *node) put(oldKey, newKey, value []byte, pgid pgid, flags uint32) {
...
// Find insertion index.
index := sort.Search(len(n.inodes), func(i int) bool { return bytes.Compare(n.inodes[i].key, oldKey) != -1 })
// Add capacity and shift nodes if we don't have an exact match and need to insert.
exact := (len(n.inodes) > && index < len(n.inodes) && bytes.Equal(n.inodes[index].key, oldKey))
if !exact {
n.inodes = append(n.inodes, inode{})
copy(n.inodes[index+1:], n.inodes[index:])
}
inode := &n.inodes[index]
inode.flags = flags
inode.key = newKey
inode.value = value
inode.pgid = pgid
_assert(len(inode.key) > , "put: zero-length inode key")
}
删除数据
node.del: 从当期节点中删除一对kv数据。后设置unbalanced为true, 表示本节点有可能触发合并
实现上:
- 首先从
inodes中二分查找key,对应位置为index - 从
inodes中删除index位置的inode对象
// del removes a key from the node.
func (n *node) del(key []byte) {
// Find index of key.
index := sort.Search(len(n.inodes), func(i int) bool { return bytes.Compare(n.inodes[i].key, key) != -1 })
// Exit if the key isn't found.
if index >= len(n.inodes) || !bytes.Equal(n.inodes[index].key, key) {
return
}
// Delete inode from the node.
n.inodes = append(n.inodes[:index], n.inodes[index+1:]...)
// Mark the node as needing rebalancing.
n.unbalanced = true
}
解引用
node.dereference: 将所有inodes数据复制到Heap上,避免对DB中mmap缓冲区的引用,避免因为boltdb重新mmap造成原有mmap缓冲区失效。这个方法是递归的,对当前节点执行dereference会递归对所有子节点调用dereference
释放
node.free: 将当前节点对应的page从freelist中释放。
Bucket
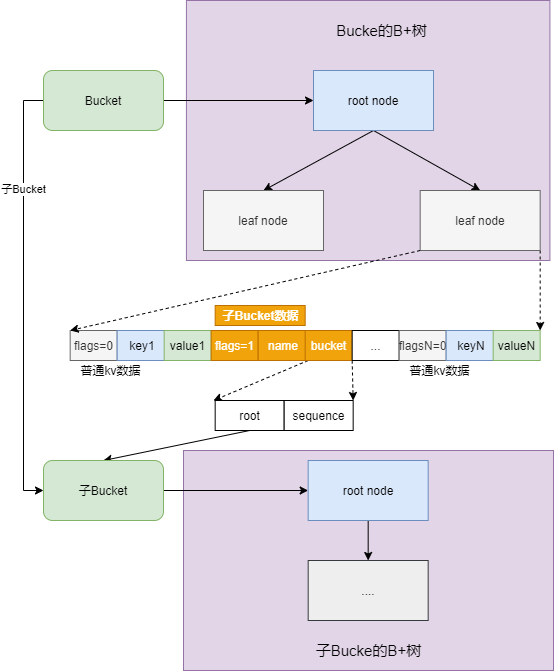
在Boltdb学习笔记之〇--概述中我们提到,Bucket类似于关系型数据库中的表,区别在于Bucket支持嵌套,一个Bucket中可以包含很多子Bucket。而不管是父Bucket还是子Bucket,每个Bucket都对应一个B+树,B+树中存储着该Bucket的所有数据和children Bucket。因为Bucket与B+树一一对应,boltdb中所有B+树操作都能在Bucket中找到对应接口。因此接下来我们以Bucket为载体总结B+树相关操作。
以下代码定义了bucket和Bucket两种类型。在bucket中,root表示该Bucket对应的B+树的根节点page id,sequence是一个单调递增的id, 对应一个Bucket。bucket可序列化为[]byte类型,作为leaf page中的value值。同样的,在leaf page中,如果某条leafPageElement数据中flags != 0, 我们也可读取其value值并将其反序列成bucket对象。
// bucket represents the on-file representation of a bucket.
// This is stored as the "value" of a bucket key. If the bucket is small enough,
// then its root page can be stored inline in the "value", after the bucket
// header. In the case of inline buckets, the "root" will be 0.
type bucket struct {
root pgid // page id of the bucket's root-level page
sequence uint64 // monotonically incrementing, used by NextSequence()
}
Bucket由bucket组成,除此之外还有其他一些成员,注意这些字段仅存在于内存中,无法序列化到db文件中。
// Bucket represents a collection of key/value pairs inside the database.
type Bucket struct {
*bucket
tx *Tx // the associated transaction
buckets map[string]*Bucket // subbucket cache
page *page // inline page reference
rootNode *node // materialized node for the root page.
nodes map[pgid]*node // node cache
// Sets the threshold for filling nodes when they split. By default,
// the bucket will fill to 50% but it can be useful to increase this
// amount if you know that your write workloads are mostly append-only.
//
// This is non-persisted across transactions so it must be set in every Tx.
FillPercent float64
}
tx:Bucket所关联的事务idbuckets: 缓存当前Bucket下的子Bucketpage: 仅当Bucket为inline时有效,即本Bucket下的所有数据都可容纳于一个page中。rootNode: 缓存当前Bucket对应的B+树根节点nodes: 缓存Bucket中B+树的节点。FillPercent: 设置Bucket对应的B+树中的分裂阈值。默认值为50%。
B+树相关操作
查询数据
Bucket.Get会在当前Bucket中搜索-key对应的value, 如果B+树中找不到key, 或者key对应的value是子Bucket数据,则返回nil值。否则返回key对应的value值。
// Get retrieves the value for a key in the bucket.
// Returns a nil value if the key does not exist or if the key is a nested bucket.
// The returned value is only valid for the life of the transaction.
func (b *Bucket) Get(key []byte) []byte {
k, v, flags := b.Cursor().seek(key)
// Return nil if this is a bucket.
if (flags & bucketLeafFlag) != {
return nil
}
// If our target node isn't the same key as what's passed in then return nil.
if !bytes.Equal(key, k) {
return nil
}
return v
}
以上b.Curosr().seek(key)即完成了B+树中key的查找, Curosr.seek代码如下
// seek moves the cursor to a given key and returns it.
// If the key does not exist then the next key is used.
func (c *Cursor) seek(seek []byte) (key []byte, value []byte, flags uint32) {
_assert(c.bucket.tx.db != nil, "tx closed")
// Start from root page/node and traverse to correct page.
c.stack = c.stack[:]
c.search(seek, c.bucket.root)
ref := &c.stack[len(c.stack)-1]
// If the cursor is pointing to the end of page/node then return nil.
if ref.index >= ref.count() {
return nil, nil,
}
// If this is a bucket then return a nil value.
return c.keyValue()
}
Cursor.seek中调用了Cursor.search, 该函数会从B+树根节点开始递归搜索-key = seek的数据。如下所示,Cursor.search中
- 首先根据page id获取B+树根节点对应的
page和node对象(如果Bucket中已经缓存了该page, 则node对象有效,否则为空) - 然后对page类型进行校验,必须是branch page或leaf page类型。换言之,page类型不能是meta page或freelist page
- 接着进行递归搜索:如果
n有效(对应节点已被Bucket缓存),则执行Cursor.searchNode;否则执行Cursor.searchPage - 递归搜索的边界条件是到达B+树叶子节点,此时调用
Cursor.nsearch在叶子节点中查找key, 记录下个大于等于目标key的位置。
// search recursively performs a binary search against a given page/node until it finds a given key.
func (c *Cursor) search(key []byte, pgid pgid) {
p, n := c.bucket.pageNode(pgid)
if p != nil && (p.flags&(branchPageFlag|leafPageFlag)) == {
panic(fmt.Sprintf("invalid page type: %d: %x", p.id, p.flags))
}
e := elemRef{page: p, node: n}
c.stack = append(c.stack, e)
// If we're on a leaf page/node then find the specific node.
if e.isLeaf() {
c.nsearch(key)
return
}
if n != nil {
c.searchNode(key, n)
return
}
c.searchPage(key, p)
}
Cursor.searchNode里,在节点n的inodes数组中二分查找key,找到后一个小于等于key值的inode的位置,接着在该位置对应的子节点中继续查找key
func (c *Cursor) searchNode(key []byte, n *node) {
var exact bool
index := sort.Search(len(n.inodes), func(i int) bool {
// TODO(benbjohnson): Optimize this range search. It's a bit hacky right now.
// sort.Search() finds the lowest index where f() != -1 but we need the highest index.
ret := bytes.Compare(n.inodes[i].key, key)
if ret == {
exact = true
}
return ret != -1
})
if !exact && index > {
index--
}
c.stack[len(c.stack)-1].index = index
// Recursively search to the next page.
c.search(key, n.inodes[index].pgid)
}
插入数据
接口Bucket.Put用于在当前Bucket对应的B+树中插入一对key/value数据。如果key已存在,则用新value覆盖老value值,如果key不存在,则新增key/value对。
在查询数据这一节我们已经见到了Cursor.seek这个接口,它的功能从Bucket中搜索目标key。如果目标key存在,返回对应的key, value和flags(用于区分value是普通数据还是子Bucket数据)。如果目标key不存在,则返回大于目标key的小key, 及其对应的value、flags
// Put sets the value for a key in the bucket.
// If the key exist then its previous value will be overwritten.
// Supplied value must remain valid for the life of the transaction.
// Returns an error if the bucket was created from a read-only transaction, if the key is blank, if the key is too large, or if the value is too large.
func (b *Bucket) Put(key []byte, value []byte) error {
if b.tx.db == nil {
return ErrTxClosed
} else if !b.Writable() {
return ErrTxNotWritable
} else if len(key) == {
return ErrKeyRequired
} else if len(key) > MaxKeySize {
return ErrKeyTooLarge
} else if int64(len(value)) > MaxValueSize {
return ErrValueTooLarge
}
// Move cursor to correct position.
c := b.Cursor()
k, _, flags := c.seek(key)
// Return an error if there is an existing key with a bucket value.
if bytes.Equal(key, k) && (flags&bucketLeafFlag) != {
return ErrIncompatibleValue
}
// Insert into node.
key = cloneBytes(key)
c.node().put(key, key, value, , )
return nil
}
所以以上代码中,当Cursor.seek返回之后,首先校验flags, 如果为子Bucket数据返回ErrIncompatibleValue错误。然后将key/value数据插入到Cursor对象c当前所在的节点上。
删除数据
Bucket.Delete从当前Bucket对应的B+树中删除目标key的数据。如果目标key不存在则什么也不做
实现上:
- 校验:事务中db是否为空,当前Bucket是否可写
- 调用
Cursor.seek寻找目标key在B+树上的位置。 - 在B+树叶子节点上删除目标key
// Delete removes a key from the bucket.
// If the key does not exist then nothing is done and a nil error is returned.
// Returns an error if the bucket was created from a read-only transaction.
func (b *Bucket) Delete(key []byte) error {
if b.tx.db == nil {
return ErrTxClosed
} else if !b.Writable() {
return ErrTxNotWritable
}
// Move cursor to correct position.
c := b.Cursor()
_, _, flags := c.seek(key)
// Return an error if there is already existing bucket value.
if (flags & bucketLeafFlag) != {
return ErrIncompatibleValue
}
// Delete the node if we have a matching key.
c.node().del(key)
return nil
}
节点分裂
随着用户不断向Bucket中插入新数据,B+树的某些叶子节点可能会超过分裂阈值,从而触发分裂。
Bucket.spill实现了当前Bucket对应的B+树的分裂,以及所有子Bucket对应的B+树的分裂(递归的)。
其实现如下:
- 首先遍历缓存中的所有子Bucket,对于每个子Bucket
- 如果子Bucket小到可以
inlineable, 则将子Bucket对应B+树中所有page释放,并将该子Bucket序列化到value中 - 否则对子Bucket递归调用
Bucket.spill,并将更新后的Bucket header序列化到value中. - 在当前Bucket对应的B+树中更新子Bucket的value, key为子Bucket名
- 如果子Bucket小到可以
- 然后对当前Bucket对应的B+树调用
node.spill,执行节点分裂 - 更新当前Bucket对应的B+树的根节点(B+树节点分裂可能会生成新的根节点)
// spill writes all the nodes for this bucket to dirty pages.
func (b *Bucket) spill() error {
// Spill all child buckets first.
for name, child := range b.buckets {
// If the child bucket is small enough and it has no child buckets then
// write it inline into the parent bucket's page. Otherwise spill it
// like a normal bucket and make the parent value a pointer to the page.
var value []byte
if child.inlineable() {
child.free()
value = child.write()
} else {
if err := child.spill(); err != nil {
return err
}
// Update the child bucket header in this bucket.
value = make([]byte, unsafe.Sizeof(bucket{}))
var bucket = (*bucket)(unsafe.Pointer(&value[]))
*bucket = *child.bucket
}
// Skip writing the bucket if there are no materialized nodes.
if child.rootNode == nil {
continue
}
// Update parent node.
var c = b.Cursor()
k, _, flags := c.seek([]byte(name))
if !bytes.Equal([]byte(name), k) {
panic(fmt.Sprintf("misplaced bucket header: %x -> %x", []byte(name), k))
}
if flags&bucketLeafFlag == {
panic(fmt.Sprintf("unexpected bucket header flag: %x", flags))
}
c.node().put([]byte(name), []byte(name), value, , bucketLeafFlag)
}
// Ignore if there's not a materialized root node.
if b.rootNode == nil {
return nil
}
// Spill nodes.
if err := b.rootNode.spill(); err != nil {
return err
}
b.rootNode = b.rootNode.root()
// Update the root node for this bucket.
if b.rootNode.pgid >= b.tx.meta.pgid {
panic(fmt.Sprintf("pgid (%d) above high water mark (%d)", b.rootNode.pgid, b.tx.meta.pgid))
}
b.root = b.rootNode.pgid
return nil
}
从上面的分析可以看到B+树分裂的核心逻辑其实在node.spill中,代码略长这里就不列出了,感兴趣的同学可查看源码。这里仅总结基本思路:
在对一个B+树节点执行分裂操作时:
- 首先将当前节点的所有子节点按照
node.key升序排序 - 然后当前节点的所有子节点递归调用
node.spill, 执行可能触发的分裂操作 - 接着对当前节点调用
node.split,返回一组分裂后的新节点, 放置于当前节点的父节点下,用于替换当前节点 - 后处理边界条件:如果当前节点是B+树根节点,判断
node.spill中是否生成了新的根节点,如果是则对新根节点执行node.spill
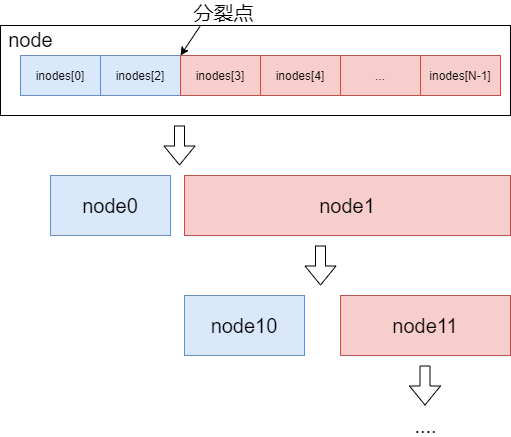
在node.split中, 将当前节点根据一定的策略分裂成一组新节点, 策略如下:
- 如果当前节点中
len(n.inodes) <= minKeysPerPage * 2(分裂后每个page中key的数量不超过minKeysPerPage),则不必分裂 - 如果当前节点序列化之后的大小小于
pageSize(该节点可被一个page容纳), 则不必分裂 - 根据
fillPercent计算出node分裂的大小阈值threshold:fillPercent * pageSize - 根据
threshold,找到当前node的分裂点(超过阈值的临界inode的位置) - 如果当前node没有parent,即自身就是B+树根节点, 则创建一个新节点作为当前节点的父节点
- 在当前节点分裂点处一分为二,生成两个新节点
left和right, 接着对right节点重复执行1-6步
节点合并
当boltdb中的B+树不断删除数据之后,导致一些节点中的数据越来越小,此时需要对低于一定阈值的节点进行递归合并。代码中由Bucket.reblance实现.
在该函数中,首先对所有缓存的node调用node.rebalance执行合并操作,然后对所有的子Bucket递归调用Bucket.rebalance
// rebalance attempts to balance all nodes.
func (b *Bucket) rebalance() {
for _, n := range b.nodes {
n.rebalance()
}
for _, child := range b.buckets {
child.rebalance()
}
}
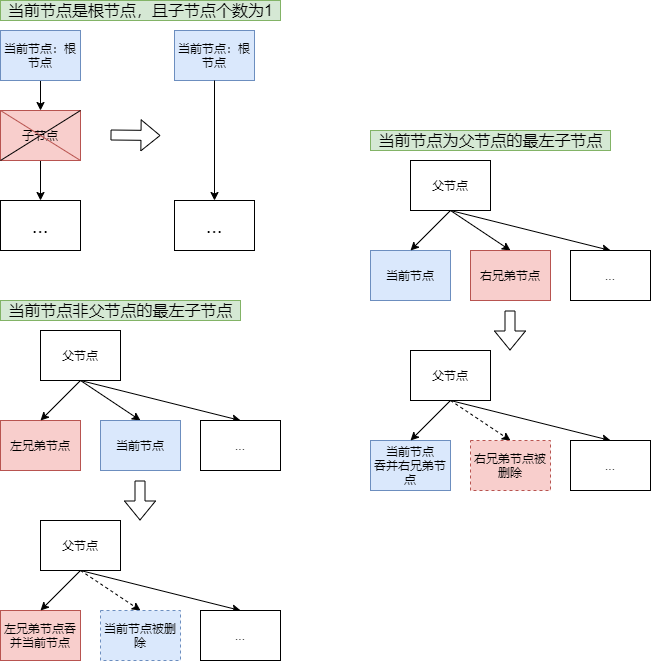
从上面的分析看到,节点合并的核心逻辑在node.rebalance中, 代码较长,这里仅总结其合并策略:
- 如果当前节点的
unbalanced为false, 说明该节点从在本次事务中未删除任何数据,那么无需对其合并 - 如果当前节点大小大于
pageSize的1/4, 且其中key的数量大于node.minKeys(), 那么无需对其合并 - 除了1和2两种情况下,说明当前节点需要合并,合并步骤如下:
- 如果当前节点是B+树的根节点。按照以下两种情况细分
- 如果当前节点非leaf node且子节点个数为1,将子节点的所有子节点放置于当前节点下,并去除子节点。
- 如果当前节点是leaf node,直接返回
- 如果当前节点的子节点个数为零,则将其从父节点的
inodes和children中删除,然后对父节点重新执行rebalance - 如果当前节点是其父节点的个子节点,则将右兄弟节点合并到当前节点中, 并对父节点执行
rebalance - 如果当前节点不是其父节点的个子节点,则将当前节点合并到其左兄弟节点中, 并对父节点执行
rebalance
Bucket相关操作
创建子Bucket
Bucket.CreateBucket: 在当前Bucket下创建子Bucket.
- 首先进行校验:db是否有效,当前Bucket是否可写,待新建Bucket的name是否为空
- 如果同名的子Bucket已存在,返回
ErrBucketExists错误 - 如果同名的key/value数据已存在,返回
ErrIncompatibleValue错误 - 在对应的B+树叶子节点中插入子Bucket数据,并返回子Bucket
注意:CreateBucket会产生一个dirty node和一个new Bucket对象,都是在内存中,在事务提交之前不会flush到磁盘,不会影响其他只读事务。
// CreateBucket creates a new bucket at the given key and returns the new bucket.
// Returns an error if the key already exists, if the bucket name is blank, or if the bucket name is too long.
// The bucket instance is only valid for the lifetime of the transaction.
func (b *Bucket) CreateBucket(key []byte) (*Bucket, error) {
if b.tx.db == nil {
return nil, ErrTxClosed
} else if !b.tx.writable {
return nil, ErrTxNotWritable
} else if len(key) == {
return nil, ErrBucketNameRequired
}
// Move cursor to correct position.
c := b.Cursor()
k, _, flags := c.seek(key)
// Return an error if there is an existing key.
if bytes.Equal(key, k) {
if (flags & bucketLeafFlag) != {
return nil, ErrBucketExists
}
return nil, ErrIncompatibleValue
}
// Create empty, inline bucket.
var bucket = Bucket{
bucket: &bucket{},
rootNode: &node{isLeaf: true},
FillPercent: DefaultFillPercent,
}
var value = bucket.write()
// Insert into node.
key = cloneBytes(key)
c.node().put(key, key, value, , bucketLeafFlag)
// Since subbuckets are not allowed on inline buckets, we need to
// dereference the inline page, if it exists. This will cause the bucket
// to be treated as a regular, non-inline bucket for the rest of the tx.
b.page = nil
return b.Bucket(key), nil
}
获取子Bucket
Bucket.Bucket实现了从当前Bucket中获取名为name的子Bucket。首先从缓存Bucket.buckets中查找子Bucket, 有则直接返回。否则从当前Bucket对应的B+树中查找该子Bucket, 如果存在则将子Bucket加入到缓存中,并返回;否则返回nil
// Bucket retrieves a nested bucket by name.
// Returns nil if the bucket does not exist.
// The bucket instance is only valid for the lifetime of the transaction.
func (b *Bucket) Bucket(name []byte) *Bucket {
if b.buckets != nil {
if child := b.buckets[string(name)]; child != nil {
return child
}
}
// Move cursor to key.
c := b.Cursor()
k, v, flags := c.seek(name)
// Return nil if the key doesn't exist or it is not a bucket.
if !bytes.Equal(name, k) || (flags&bucketLeafFlag) == {
return nil
}
// Otherwise create a bucket and cache it.
var child = b.openBucket(v)
if b.buckets != nil {
b.buckets[string(name)] = child
}
return child
}删除子Bucket
Bucket.DeleteBucket实现了在当前Bucket中删除指定name的子Bucket.
由于子Bucket可能还嵌套包含自己的子Bucket, 因此在从当前Bucket对应的B+树中删除该子Bucket时,还需递归调用Bucket.DeleteBucket将子Bucket中的子Bucket删除。
