数据库的事务包含原子性、一致性、隔离性、持久性四个特性。隔离性与一致性紧密相连,它们也容易让人迷惑。SQL标准定义了4个隔离级别,但由于定义使用的是自然语言,而非形式化语言,导致人们对隔离级别的理解有所差异,各个数据库系统的实现方式也有所不同。然而在分布式的场景下,又面临新的问题。
探索前沿研究,聚焦技术创新。本期由腾讯云数据库工程师孟庆钟为大家介绍数据库事务一致性的实现,内容包括事务的基本概念以及特性、主要的隔离级别及实现、TDSQL事务一致性的实现。
事务的基本概念及特性
1.1 事务的基本概念及特性
事务是用户定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单位。
事务具有四个特性即ACID:
原子性(A):事务中包括的操作要么都做,要么都不做;
一致性(C):事务执行的结果必须使数据库从一个一致性状态转移到另一个一致性状态;
隔离性(I ):并发执行的事务之间不能互相干扰;
持久性(D):事务一旦提交,它对数据库的改变应该是性的。
原子性和持久性比较直观易懂,但是一致性和隔离性则较为复杂,不同人有不同的理解。

1.2 一致性的理解
一致性是偏应用角度的特性,每个应用程序需要自己保证现实意义上一致。
数据库在一致性方面对应用程序能作出的保证是:只要事务执行成功,都不会违反用户定义的完整性约束。在执行事务的过程中,只要没有违反约束,那么数据库内核就认为是一致的。
常见的完整性约束有主键约束、外键约束、约束、Not-NULL约束、Check约束。只要定义了这些约束,数据库系统在运行时就不会违反;只要没有违反,数据库内核就认为数据库是一致的。至于现实意义上是否一致,需要由应用程序自行判断。

1.3 导致不一致的原因
为什么数据库可能会不一致呢?其实是由冲突所导致的。应用程序对数据的读写操作,终体现为数据库内核中的事务对数据库对象的读写操作。如果不同事务对相同的数据进行操作,并且其中一个操作是写操作,则这两个操作就会出现冲突。如果不能正确处理这些冲突,就会出现某些异常。常见的异常主要有脏写、脏读、不可重复读、幻读等。

并发执行的事务产生冲突,其实可以理解为科幻小说里两个不相容的物体进入了同一时空。因为是在时空上产生冲突,所以我们可以从时间和空间两个维度解决:
时间维度:把两个操作从时间维度隔开,禁止同时访问。这其实是基于锁实现的并发控制思想。
空间维度:把这两个操作从空间维度隔开,禁止访问同一份数据。这其实是基于多版本实现的并发控制思想。
1.4 隔离性的理解
有些应用程序的执行逻辑,永远不会导致某些异常的产生。在这种前提下,即使数据库允许某些异常,实际上永远也不会产生这些异常,数据库仍然是一致的。
我们用一个简单的比喻来进行理解。底层模块看作是数据库,上层模块看作是应用软件,当上层软件模块调用底层模块时,即使底层模块有BUG,但如果不踩这个坑就永远不会触发BUG,则应用软件和数据库组成的成体看起来并没有BUG,数据库则会一致。
隔离性是指并发执行的事务之间不能互相干扰。为了提高系统运行效率,SQL标准允许数据库在隔离性上进行妥协,即允许数据库产生某些异常。那到底需要隔离到什么程度呢?这需要由隔离级别来确定。根据需求的不同,我们可以选择不同的隔离级别。

主要的隔离级别及实现
2.1 SQL标准定义的隔离级别
我们所理解的隔离级别是指并发执行的事务能看到对方的多少。下图是SQL标准给出的定义,根据数据库禁止哪些异常来进行划分。SQL标准定义了四种隔离级别:Read Uncommitted、Read Committed、Repeatable Read、Serializable。
Read Uncommitted为读未提交,所以三种异常都有可能发生。比Read Uncommitted更严格一级的是Read Committed,即不能读未提交的事务,但可以出现不可重复读和幻读。更严格的是Repeatable Read,只允许出现一种异常。严格的是Serializable,这三种异常都不允许发生。

但该定义也有不足。一方面,上述定义来源于锁实现的并发控制,但是又想摆脱对锁实现的依赖,所以根据数据库不允许哪些异常来定义数据库的隔离级别。基于锁实现的并发控制可以完美匹配上面的定义,但是其它实现方式不一定匹配这个定义。比如常见的快照隔离(Serializable Isolation),不会出现这三种异常,按定义属Serializable,但它可能出现其它异常(写倾斜),所以快照隔离并非真正的Serializable。另一方面,该定义使用的是自然语言,而非形式化的语言,导致人们理解有差异,有些系统因此直接把快照隔离称为可串行化。
2.2 基于锁实现的并发控制
锁可以分为多种类型,包括读锁、写锁和谓词锁。读锁、写锁锁单个数据对象,谓词锁锁一个范围。持锁的时长也不相同,可以操作完数据直接放锁,也可以等事务结束才放锁,比如读数据或写数据前先把锁拿到手,一直持着不放直到事务结束。下图中的Well-formed Reads/Writes是指读/写数据之前都要加锁,非Well-formed Reads/Writes就是不加锁而直接对数据进行读/写。
基于上述三个前提,我们可以看到视图中的隔离级别,关于写的操作基本相同,都是写数据前要先拿到写锁,写锁等事务结束后再放,主要区别在于读锁。
Read Uncommitted的读不需要加锁。事务写数据要加写锁,事务结束后才放锁。虽然读锁和写锁互斥,写加写锁,但读时不加锁就可以直接读到。
比Read Uncommitted更严格一级的是Read Committed,读时需要加读锁。只要能加读锁就代表没有其它事务在写,写该数据的事务一定已经提交。因为未提交的写事务其写锁还没有放,读锁和写锁互斥,读事务无法加读锁,因此用该隔离级别读到的都已提交事务的数据。读事务的读锁在读完后就放锁,下次再读该数据时要重新加读锁。放锁后再加锁,该数据可能在读事务未持读锁的期间被其它事务修改,因此读到的数据可能有变化。
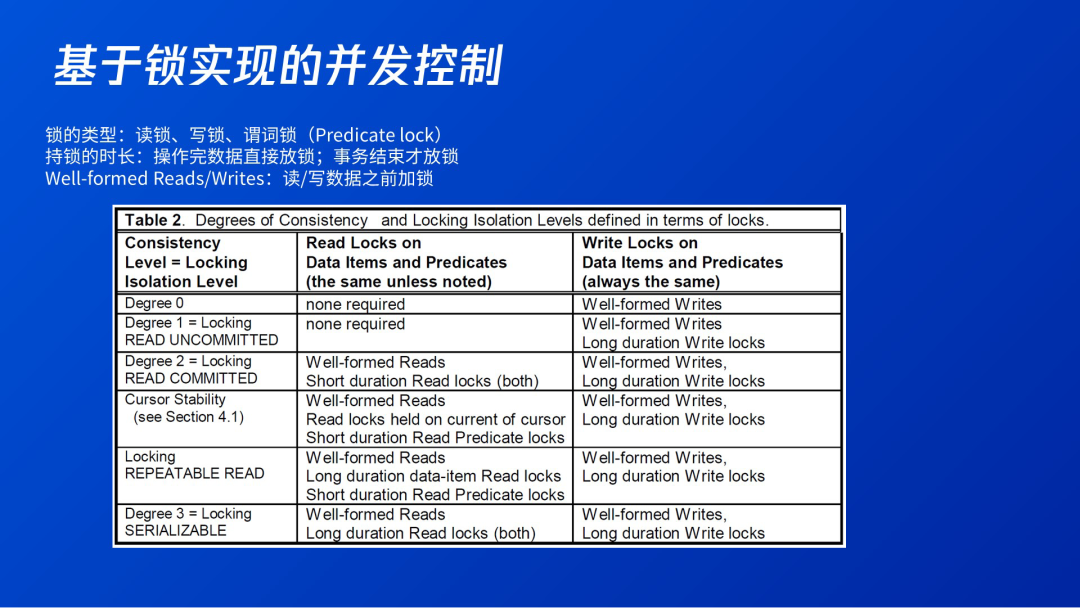
在Serializable下,读要加读锁,到事务提交时才放。这就保证了数据不会在读事务执行期间被修改。因为如果其它事务要改就需要加写锁,写锁读锁互斥,因此其它事务的写锁加不上。括号中的Both指的是谓词锁和一般的读锁都到后才放。
Repeatable Read(RR)比Read Committed(RC)强,比Serializable弱。RR比RC强在读锁,RR比RC多一个读锁后放。RR比Serializable弱在谓词锁,RR比Serializable少一个谓词锁后放,所以RR可能出现幻读。
2.3 基于多版本实现的并发控制
一个数据库对象有多个不同的版本,每个版本关联一个时间戳。事务在访问数据时,会使用一个快照选出合适的版本。这就是多版本并发控制(MVCC),好处是读写互不堵塞,读时可在多版本中读合适的版本,写时追加一个版本。
时间戳的选择有两种主流的方式:
使用事务的开始时间:PostgreSQL属于这类系统。大多数情况下,事务开始的时间越晚,则产生的版本越新,但是存在特例。为了排除这些特例,PostgreSQL的快照中有一个活跃事务列表,列表中的事务对快照不可见。
使用事务的结束时间:TDSQL属于这类系统,事务结束的早,就可以对后续事务可见,所以这类系统的快照只需要一个时间戳,通常只是一个整数。
典型的隔离级别有三种,Read Committed(RC)、Snapshot lsolation(SI)以及 Serializable Snapshot Isolation(SSI)。

2.3.1 Read committed的实现
理论上,Read Committed有三种实现方式:
对每行数据来说,随意读取一个已经提交的版本;
对每行数据来说,读取数据后提交的版本;
每条SQL语句开始时,获取一个新的快照,使用这个快照选择数据合适的版本,修改数据时修改新版本。
种实现方式满足定义,但可能因为读取的数据太老,导致现实中无意义,因此实际系统里基本不用这种实现方式。
第二种实现方式也满足RC定义,但会存在读偏序问题。读偏序是指只读取到某个事务的部分结果,比如T1更新了两行数据,但是T2只读到其中一行的更新。如果对每行数据都只读新提交的版本,就会存在读偏序问题,实际系统中也较少使用这种实现方式。
第三种则是实际系统里较为常用的实现方式。具体实现方式为:每条SQL语句开始时都会获取一个新的快照,用该快照选择合适的版本,用同一快照选择就不存在读偏序问题。
2.3.2 Snapshot lsolation的实现
第二种比较典型的隔离级别是Snapshot lsolation(SI),它并不在SQL标准定义的四种隔离级别中。其实现方式是:事务开始时获取一个新的快照,事务的整个执行过程中使用同一个快照,保证可重复读。修改数据时,如果发现数据已被其它事务修改,则abort。
在SI中,上述提及的三个异常即脏读、不可重复读、幻读都不存在,但存在写偏序问题。如果两个事务读取了相同的数据,但是修改了这些数据中的不同部分,就可能导致异常,这种异常叫写偏序。
2.3.3 Serializable Snapshot Isolation的实现
第三种比较典型的隔离级别是Serializable Snapshot Isolation(SSI),其实现方式为:事务开始时,获取一个快照(通常是新的。为了降低事务abort的概率,某些只读事务可能拿到非新快照)。修改数据时,如果发现数据已经被其它事务修改,则abort。
SSI跟SI的不同在于:在读数据时,SSI记录事务读取数据的集合,再使用算法进行检测,如果检测到可能会有不可串行化的发生,则abort。这种算法可能会有误判,但不会有遗漏,因此SSI不存在写偏序问题。
SSI是真正的Serializable隔离级别。
2.3.4 写写冲突的处理
对于写写冲突的处理,基于多版本实现有两种实现方式:
First commit win,谁先提交谁赢。谁先把数据提交到数据库里谁就胜出。
First write win,谁先写谁赢。谁先往数据库里写(不一定提交),就会阻塞后面的写事务,从而更有可能赢。
2.4 MySQL的隔离级别
在分析MySQL的隔离级别之前,我们需要先了解两个概念:当前读和快照读。当前读是指读取数据的新版本,读写时都需要加锁。快照读是指使用快照读取合适的版本,快照读不加锁。MySQL支持SQL标准定义的四种隔离级别,具体实现方式如下:
MySQL在Read Uncommitted直接读,不加锁,可能出现脏读。
MySQL在Read Committed下,对于select(非for update、 非in share mode)使用快照读,每个SQL语句获取一个快照;对于insert、update、delete、select for update、select in share mode则使用当前读,读写都加锁,但不使用gap锁,读锁用完就释放,写锁等到事务提交再释放。

MySQL的Serializable属于纯两阶段锁实现,所有DML都使用当前读,都读新版本,读写都加锁,使用gap锁,锁都到后再放。
MySQL的Repeatable Read在Serializable的基础上,放松了对select的限制,select(非for update、非in share mode)使用快照读,其它场景则与Serializable相同。MySQL在Repeatable Read下,混用了当前读和快照读,可能会导致看起来比较奇怪的现象,但只要理解它的实现方式,就可以对这些行为做出分析,这些都是可解释的。
2.5 PostgreSQL的隔离级别
MySQL更像是基于锁和多版本的结合。而PostgreSQL则是基于多版本的实现,写时有行锁。PostgreSQL支持三种隔离级别,即Read Committed、SI、SSI,PostgreSQL里没有当前读,都是快照读,三种隔离级别的实现方式如下:
在Read Committed中,每条SQL语句都会使用一个新的快照。对于update,如果发现本事务将要修改的行已经被其它事务修改了,则使用数据新的版本重新跑一遍SQL语句,重新计算过滤条件、计算投影结果等,再尝试更新新的行,如果不满足过滤条件则直接放弃更新。这个过程在PostgreSQL中被称为EPQ(EvalPlanQual)。
在SI中,整个事务使用同一个快照,更新时如果发现数据已经被其他事务修改,则直接abort。这在PostgreSQL代码里有较为直观的呈现,发现数据被改后,判断当前隔离级别是否大于等于SI,如果是则直接abort,如果小于则会跑EPQ。
SSI在SI的基础上,使用SIREAD锁(PG内部也称为Predicate Locking),记录本事务的读集合。如果检测到可能导致非可串行化,则将事务abort。实际加锁的数据范围,与执行计划相关,比如seqscan对整个表加锁,index scan只需要对部分行加锁。需要注意的是,SIREAD锁是一套独立于PG读写锁之外的机制,与PG中读写锁均不冲突,它只是起到记录作用,用于写倾斜的检测。
PostgreSQL里面关于写写冲突的处理方式是谁先写谁胜出,具体实现机制为给行加上行锁,这时其它事务就无法修改。PG的行锁几乎不占内存,本文不详细展开。


TDSQL事务一致性的实现
3.1 TDSQL的架构
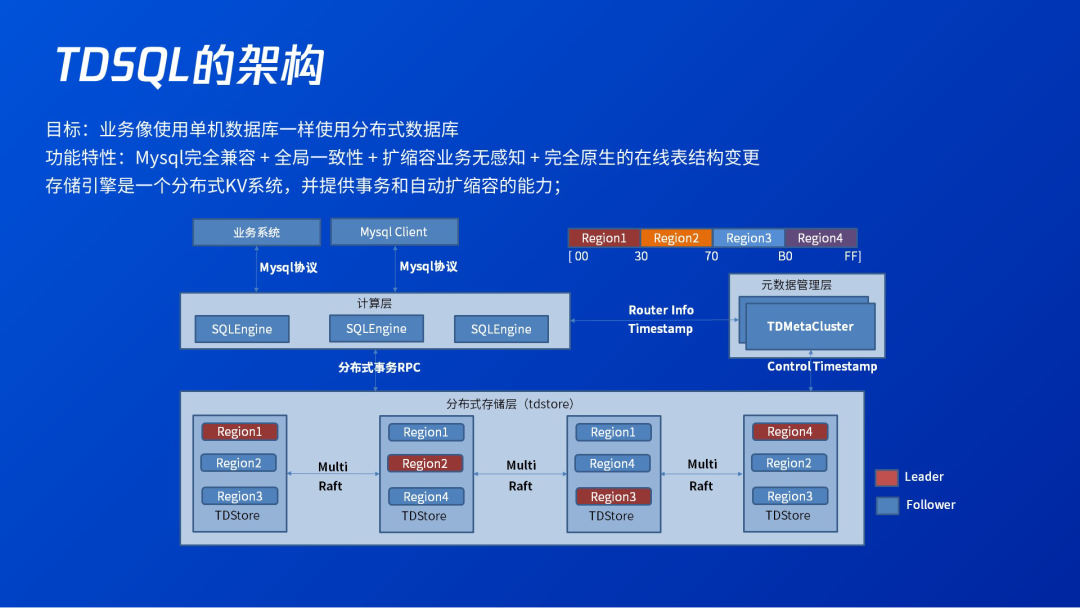
3.2 多副本的一致性
选主。Raft协议是一个强主的协议,集群中必须要有一个leader,系统才能对外提供服务,要保证选出来的leader。 日志复制。日志只会从leader到follower单向复制,日志没有其它流动方向。 安全。保证选出来的leader包含多的日志,避免leader因为日志不全而需要到其它节点上拉取日志。如果日志不够多,就不可能成为leader。 配置变更。Raft协议中,系统只能有的leader,不能产生双主。为了避免产生双主,增减节点时使用两阶段完成。整体流程为:先是旧配置生效,再到新配置和旧配置同时生效,后新配置生效。

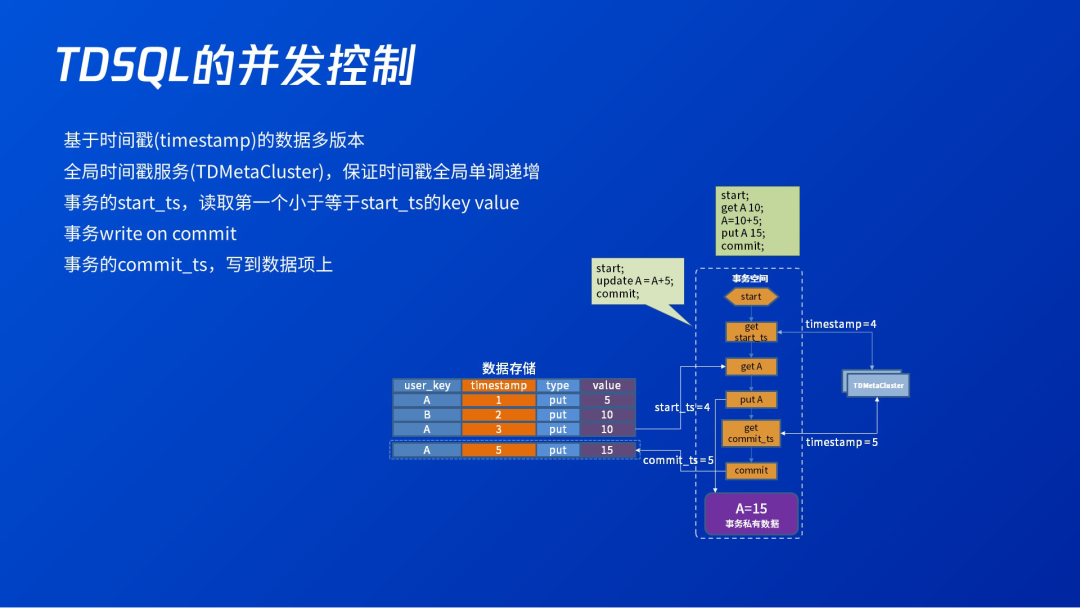
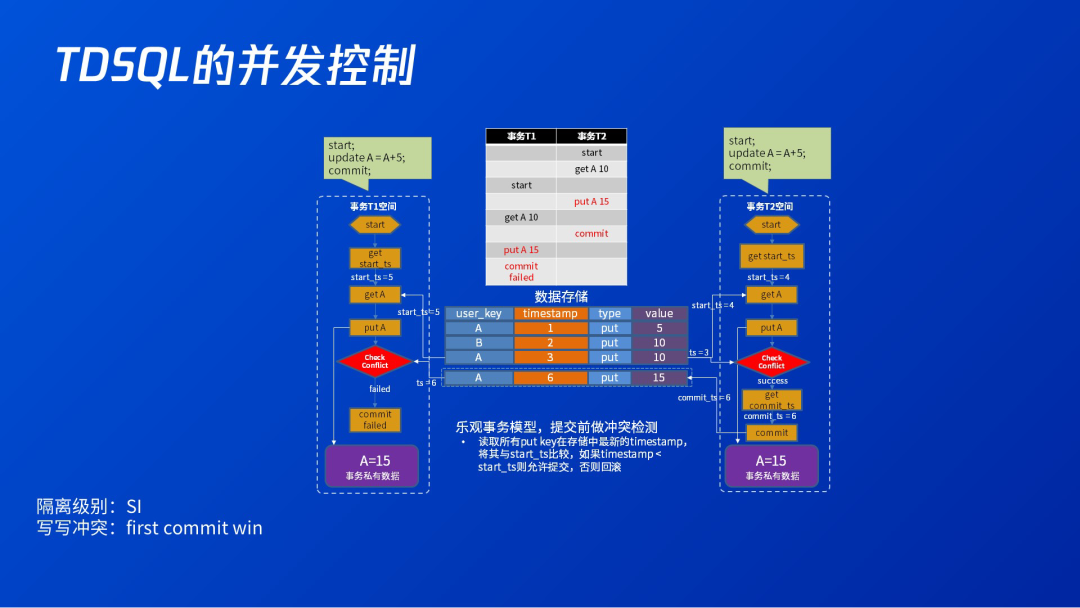
3.3 TDSQL的并发控制
3.4 TDSQL的分布式提交协议
每个节点都有带预写式日志的持久化储存; 没有节点发生故障; 预写式日志永远不会丢失; 任何节点之间都可以相互通信。

3.5 TDSQL的一致性读

