背景
RocksDB是由Fackbook公司开源的一款性能很高的Key Value存储引擎,有很多项目包括58存储团队的分布式KV存储产品WTable都使用它作为存储引擎。但是RocksDB参数调优也极其复杂,若希望RocksDB在不同机器、不同的应用场景发挥良好的性能,并不是一个简单的事情。绝大多数时候在一台机器或者一个集群中调整的参数,在另一个机器或集群中性能可能会不行。在RocksDB官网中,已经提供一篇关于调优的wiki,RocksDB Tuning Guide以供大家参考。这里笔者会结合58存储项目的一些些使用经验,详细对其解释,和大家一起学习。在优化RocksDB参数前,首先应该先了解RocksDB是如何具体处理LSM的。这个在其他公众号应该有很多文章了,这里暂时不重复说明了,有机会可能会加入这方面的内容。
放大因素
调试RocksDB通常是在三个Amplifcation之间进行取舍:
1. 写放大。目前我们常碰见的是写放大。假如我们写入10M的数据,但是实际上硬盘写入30M数据,那么写放大就是3。如果是写入压力较大的机器或者集群,我们就需要尽量减小写放大。通过RocksDB本身的统计可以观察。
2. 读放大。每次请求需要读几次硬盘。如果一个query需要读5 pages,那么读放大就是5。在RocksDB本身的统计中并没有特别好的方法去观察读放大,通常需要iostat等命令来评估。
3. 空间放大。假如需要存储10M数据,实际上硬盘占用100M,那么空间放大就是10。
RocksDB 统计信息
我们实际调优性能时,绝大多数都是借助RocksDB本身的统计信息。RocksDB有个参数stats_dump_period_sec可以定时将这些stats信息打印到LOG日志 中,默认是10分钟。也可以通过db->GetProperty("rocksdb.stats")直接在程序中获得统计信息。目前,WTable只使用默认的Column Family,统计信息如下:

上面是默认Column Family的compaction统计信息,以及整个DB的统计信息。
Compaction 信息
Compaction stats就是Level N和N+1做compaction的一些数据统计,在N+1输出结果:
Level 就是LSM的level。Sum代表所有level的总和。INT是从上次打印到现在的数据。
Files 有两个值a/b。前者是每层Level的文件个数,后者是当前有多少个文件正在compaction。
Size 当前Level的大小。
Score 除了Level-0,score值是(current level size) (max level size)。正常情况下值是0或者1,如果大于1,则代表这层Level需要compaction。对于Level-0的score值计算方式是(current number of files)/(number of compaction trigger)。
Read(GB) 是从Level N到N+1做compaction的总读取数据量。
Rn(GB) 是从Level N到N+1做compaction的Level N的读取数据量。
Rnp1(GB) 是从Level N到N+1做compaction的Level N+1的读取数据量。
Write(GB) 是从Level N到N+1做compaction的总写入数据量。
Wnew(GB) 是新写入Level N+1的数据量,值是(total bytes written to N+1) - (bytes read from N+1 during compaction with level N)来计算的。
Moved(GB) 直接移动到Level N+1的数据量,只是修改对应元数据信息,并不会进行IO操作。表示之前在Level N,现在在Level N+1层了。
W-Amp 是从Level N到N+1的写放大。
Rd(MB/s) 是从Level N到N+1做compaction的读取速度。值是(Read(GB) * 1024) duration, duration是从Level N到N+1做compaction的时间。
Wr(MB/s) 是从Level N到N+1做compaction的写入速度。计算方式和 Rd(MB/s)一致。
Comp(sec) 是从Level N到N+1做compaction的总时间。
Comp(cnt) 是从Level N到N+1做compaction的总次数。
Avg(sec) 是从Level N到N+1做compaction的平均数。
KeyIn 是从Level N到N+1做compaction时比较record的数量。
KeyDrop 是从Level N到N+1做compaction时丢弃的record数量。
每个统计参数的具体计算值可以参考include/rocksdb/internal_stats.cc。
每层的Level compaction信息之后是一个compaction的汇总统计信息。包含cumulative和interval,cumulative信息是从运行开始到现在的总统计信息,interval是从上一次统计到现在的信息。

主要关注一下上图信息,关于Stall的信息,也就是停写。如果出现了停写,说明外部写压力太大,compaction不够及时,导致写入被阻塞中。
DB 信息
除了Compaction的统计信息,还有DB的总的统计信息:
updates: 从启动到现在的时间和上一次统计到现在的时间。
write:
wirtes: 总写入次数
keys: 总写入key的数量
commit groups: 总批量写入提交的数量
write per commit groups: 每次批量写入的写入次数
ingest: 写入RocksDB 的总数据量
WAL:
wirtes: 总写入次数
syncs: sync的次数
writes per sync: 每次sync的写入次数
written: WAL总写入数据量
stall
H:M:S: 总的停写时间
percent: 停写时间在总时间的比例
在WTable中,我们定时每10分钟会将统计信息输出,同时也会汇总这些信息和其他关键信息到WTable本身的日志和绘制图表来供我们分析瓶颈。
Perf Context and IO Stats Context
在实际使用中,我们可能需要跟踪一些读写请求延迟都耗费在哪里了。比如我们Get某一个key,但发现其耗时非常长,这时候我们就可以通过Perf Context and IO Stats Context对一个操作进行分析。
#include “rocksdb/iostat_context.h”#include “rocksdb/perf_context.h”rocksdb::SetPerfLevel(rocksdb::PerfLevel::kEnableTimeExceptForMutex);rocksdb::get_perf_context()->Reset();rocksdb::get_iostats_context()->Reset();... // run your query
下面是WTable实际使用中的一些请求耗时日志信息。

这样,我们就可以通过write_wal_time、write_memtable_time了解到Put的实际耗时在写入WAL和memtable中花费了多少时间。
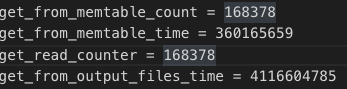
同理,我们也可以得到Get请求有多少次是读memtable,从memtable读取数据的耗时如何。
在WTable中,并没有实时收集这些信息,只有需要时候才打开的这个功能,用来定位一些请求的异常耗时问题。
下面我们看一下一些常规性能优化。
“停写” 调优
在WTable发布之初,对于RocksDB配置不是很高效,写入压力总会受制于RocksDB的Write Stall。通过iostat命令发现I/O使用率很小,但在RocksDB经常会出现Stall状态。我们一起分析下当时的原因。
如何触发的停写?
首先,先看下Stall出现的原因:
Too many memtables. 如果当需要flush的memtable数量大于等于max_write_buffer_number,写入就会完全停止等待所有memtable flush完成。
Too many level-0 SST files.如果Level-0文件数量大于等于level0_slowdown_writes_trigger,就会发生Write Stall。如果数量到达level0_stop_writes_trigger,写入就是完全停止。
缓解停写
对于上述两个问题,WTable实际做过很多测试,但具体什么配置会适用你的机器,就需要根据实际去分析与测试了。下面解释一下我们的分析方法和思路。
Too many memtables 解决思路
针对点,WTable实际上并没有做太多的工作,只要控制 memtable 的总数量不触发阈值就能保证Stall不会发生。具体统计信息如下:

RocksDB的memtable在Write Stall大可以缓存数据量是 max_write_buffer_number* write_buffer_size。
解决思路:
如果写入压力过大时发现num_memtables的值很大,并且机器内存充足情况下,我们只需要调整上述两个参数即可。如果机器内存不足情况下,我们只能加快消费者的flush速度,RocksDB有个参数max_background_flushes(新版已经用max_background_jobs替代)可以增加flush线程数。但是增加flush消费速度并不是没有代价的,会有瞬间很大的I/O消耗。
Too many level-0 SST files 解决思路
在解决上一问题中,如果已经调整过write_buffer_size,那么会发现Level-0已经可以存储更多数据量。实际上,跟上一个问题的思路基本一致,要么增加缓存生产者的缓存队列存储的数据量,或者加快消费者的消费速度。Level-0的存储数据量是write_buffer_size * level0_slowdown_writes_trigger。解决Level-0文件过多的问题,我们先关注RocksDB的一些统计信息:

lsm_state是每层Level的文件数量的数组输出,个数字代表的就是Level-0的文件个数。
解决思路:
如果Level-0文件个数过多,调整write_buffer_size可以让每个Level-0文件可以存储更多的数据量。如果某个时间段的写入压力特别大,而磁盘IO也到了瓶颈,可以考虑level0_slowdown_writes_trigger设置一个足够大的参数,也就是相当于关闭compaction(需配合关闭disable_auto_compactions),但相对的也会一定的空间放大,会浪费一定的磁盘空间。增加max_background_compactions可以增加compaction线程数,进而增加compaction处理能力,同理,也可能会造成很大的I/O压力。
Compaction 调优
上面描述了处理Write Stall的问题,再调整max_background_compactions和 max_background_flushes加速处理compaction和flush的同时,也会占用一定 I/O 资源。在WTable实际使用中,因为compaction和flush造成的瞬时I/O占用过高,导致线上服务有很多慢请求。所以,我们也针对写入压力情况下的compaction的优化。
RateLimiter* rate_limiter = NewGenericRateLimiter(rate_bytes_per_sec /* int64_t */,refill_period_us /* int64_t */,fairness /* int32_t */);
在RocksDB里面,我们可以通过Rate Limiter来控制 I/O,有三个参数:
rate_limit_bytes_per_sec:控制每秒的compaction和flush的写入量。
refill_period_us:控制tokens多久被再次充满。比如,rate_bytes_per_sec是10M/s,同时refill_period_us是100ms,那么每100ms 的流量就是1MB。
fairness:用来均衡compaction和flush任务的参数。避免因为flush任务过多,导致compaction被饿死。
RocksDB支持动态调整rate_limit_bytes_per_sec参数
rate_limiter->SetBytesPerSecond(bytes_per_second);
或者单独调整compaction或者flush的写入量
// block if tokens are not enoughrate_limiter->Request(1024 /* bytes */, rocksdb::Env::IO_HIGH);Status s = db->Flush();
关于Rate Limier更多API的功能,查看include/rocksdb/rate_limiter.h。
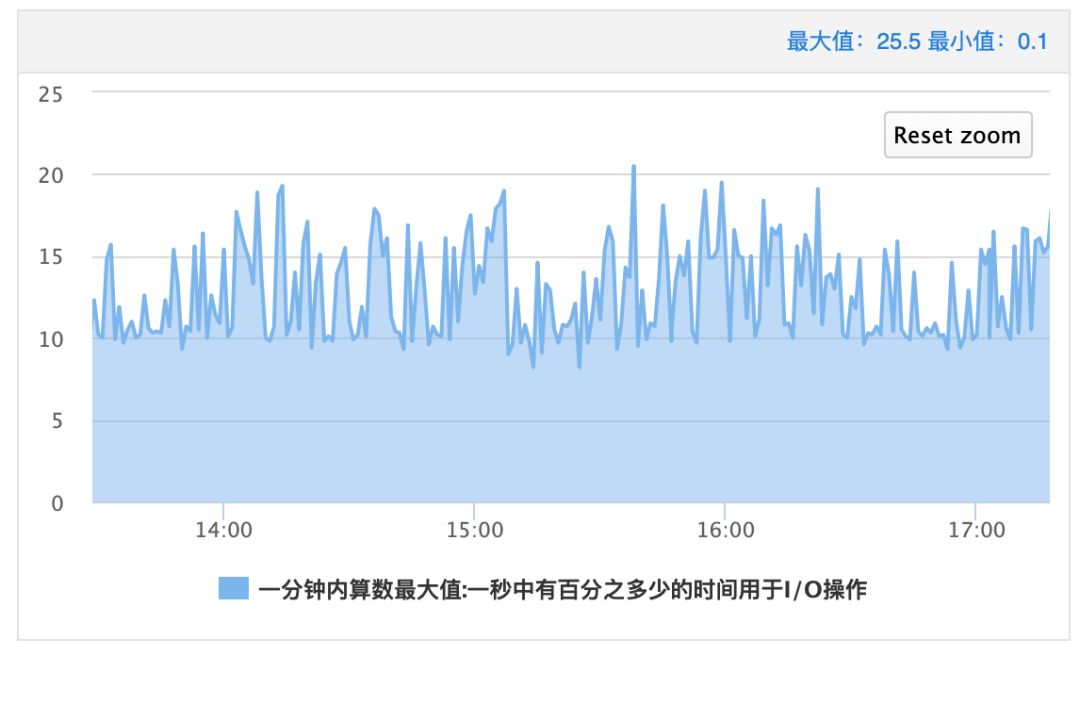
在WTable中,由于compaction和flush执行时写入流量过快,所以,造成IOUtil有很多“锯齿”,瞬时的峰值甚至会造成IO超时,进而影响线上服务。

为了保证线上服务的稳定性,我们通过上述的方式去不断尝试修改compaction和flush执行时期的写入速度。从而让IOutil使用量看起来相对平滑一些,避免瞬时IO超时的问题。
当然,目前我们的调整参数时候还需根据线上负载情况进行相应的调整,这给我们运维带来很大的工作量。近看到一篇Paper,Auto-tuning RocksDB(
https://brage.bibsys.no/xmlui/bitstream/handle/11250/2506148/19718_FULLTEXT.pdf?sequence=1
),关于自动调优RocksDB,给了我们很多思路,也在往这个方向尝试,评估WTable当前的机器实际负载来调整RocksDB参数。但是,自动调优的可靠性和难度也有很大的挑战。
总结
总的来说,通过上面的统计信息,我们可以监控很多系统的指标,并及时发现问题,提前调整参数避免一定问题,也可以让你的系统发挥很好的性能。很多时候,我们并不能一次在不同机器上配对RocksDB,绝大多数都是根据机器性能评估一个相对优的配置,然后在根据实际进行动态调优。
来源 https://www.modb.pro/db/58517
