## 前言
[Martin Kleppmann],《数据密集型应用系统设计》([Designing target="_blank" rel="nofollow noreferrer" style="color: inherit; text-decoration: none; cursor: pointer; border-bottom: 1px solid rgb(128, 128, 128);">一次演讲中],用了一个标题Is Kafka a Database,他的答案是:Yes。
某种程度,BunnyRedis是这个思想的一个实践,因为BunnyRedis可以简化抽象为:
BunnyRedis = Redis + Kafka
所以,显然我是赞同这个思想的。那么我谈谈我对这个问题的理解。
## 分拆等式
我是学理工的,所以,对Kafka is Database,我的理解完全是一个公式
Log is Database, i.e., Log = Database
Kafka is for Log,i.e., Kafka = Log
所以,一个小学生都能通过上面的逻辑等式,得到下面的等式
Kafka = Database
## 什么是Log?
首先我们要了解什么是Log,以及它有什么特征。
Log具有下面的特性:
1. 它是尾部追加模式,即新的数据写在整个数据结构的尾部,即Append Mode
2. 它是不可改变的,即我们写了这些数据,我们就不指望再次修改它,即Immutable
再用简单的词来抽象上面两个特性,就是Append Only
那么,我们为什么需要这样一个数据结构,以及它有什么特点(好处和坏处)?
Log这个数据结构,可以用在内存,也可以用在磁盘,它具有如下的特点:
1. 从写的Big O看,它是O(1)的操作,不管是在内存上发生,还是在磁盘上发生
2. 从读的Big O看,它也是O(1)的操作,而且特别适合磁盘
### 先看写Write
内存上我们不说了,显而易见,是O(1)操作,而且,如果你用Java ArrayList,或C++的std::vector,它是内存紧凑的,对于CPU cache非常适宜。
磁盘要看两个,一个是HDD,磁力旋转的存储,一个是SSD,芯片并发的存储。
对于HDD,Log非常适合,因为HDD,一个大的cost就是移动磁头重新定位,我们称之为seek time,一般是几个ms的消耗。而如果用Log,磁头无需移动。
[有兴趣的同学可以看一下视频,HDD内部是如何工作的]
对于SSD,情况要复杂很多。SSD的效能的有效利用,来自内部电子单元的并发度,从数据上看,给与SSD越多的数据(以及嫡值合适),它的效果越好。从这个角度看,Log并没有太大的优势,实际测试也是如此。
[有兴趣的同学可以看一下演示,SSD内部是如何工作的]
但如果较真的话,SSD还是有稍微的不同。因为SSD内部就像一个电脑,它有内存高速缓存,它有类似CPU的逻辑芯片和一些算法(比如:GC算法),所以如果Log适合计算机的某些场景,理论上,它也适合SSD这个小型计算机。但Anyway,这个不是主要因素,主要因素还是上面那点,并发度,或者说,足够的数据供给。
SSD真正的麻烦在于写放大Write Amplification,因为SSD内部也是page为单位的,小4K,而且SSD的写不是overwrite,即并不是在原来的位置替换(in-place update),而是一个COW,copy on write,读出旧的page数据,在内存修改好了后,然后在一个新的page,写入修改的数据。如果涉及block的擦除(erase),则写放大更大(block一般以M为单位)。
所以,如果写入不是4K对齐和4K整倍数,比如,我们希望对于某个文件的某个位置修改1个字节,那么在SSD里,是实际需要写入4K大小的一个新的block,这就会有4000倍的写放大。
而对于Log的写,可以减少写放大的伤害。因为不管是用机器的内存,还是用SSD内部的缓存,我们都可以聚集足够的新数据(比如4K),再写入一个必须用到的新的4K block,我们就可以降低甚至避免写放大。这是因为Log的特性是:Append-Only,即没有overwrite的需求。
### 再看读Read
对于读,如果正好需求是一段数据(比如:文件里的1M连续数据),也是O(1)操作。
内存不用说了,我们来看磁盘。
对于HDD,同样不需要移动磁头,或者说,只要一次磁头定位即可。这就省了多次seek time这个大cost。
对于SSD,它效能的根本,仍是并发性。所以,如果从Log连续读1M的数据,还是随机读总共1M数据,差别不大,只要读取的请求足够多。
但是和写放大类似,假设我们读4K数据正好在一个block,和读4000个1字节分布在文件不同的位置(比如分布在4000个block上),显然读1个block的效能要高。由于Log一般是把近相关的一些数据写到同一个block里,所以Log还是有利于这个场景,至少可以保证读的blocK数足够少。
### Log不利的地方
任何数据结构都不是的,都有trade off。
对于Log不利的地方在于:如果我们希望通过一个key找到对应的数据,我们就不是O(1)操作,而是O(N)操作,不管这个Log是在内存上,还是在磁盘上。
所以,对于Log,我们想实现key的检索,我们需要添加其他数据结构,比如Hash或Tree。用Hash的O(1),以及Tree的O(lg(N))来避免Log的O(N)的key检索。
## 什么是Database?
这个题目太大,Martin Cleppmann的答案是:ACID
我的想法更简单,只要能放数据(写入write),然后能再次获得数据(读取read),那么,它就是Database。从这个意义上讲,一个csv文件,都是一个数据库,而且csv文件是没有索引的。
也许有人有不同的想法,不过没有关系,大家不过是广义或狭义之分,Database大致要提供哪些基本功能,其实我们大家都清楚。
## Log is Database
那么我们如何理解Log is Database这句话?
### 单机系统
我们来看一下单进程的MySQL。
MySQL有两个的Log,一个是redo log,一个是binlog。
#### redo log
redo log,是数据库将修改的结果,记录在一个Log文件上。它的好处在于,避免了对于整个dataset的修改和即时落盘(fsync)的要求。
假设我们数据库很大,有1TB,但一个Transaction修改的数据一般并不大,我们假设每个Transaction只修改了1K数据,每个Transaction修改的位置,对于整个1TB dataset而言,是随机的。
如果我们每次修改1K字节,我们都要落盘的话,这个同步fsync操作,是非常大的cost,对于HDD,它要不停地移动磁头,对于SSD,它有写放大。
而且,如果每次修改都先落盘,然后再给客户确认消息的话,时间Latency很长,会大大降低整个数据库的效能Throughput。
所以,一个优化的方案如下:
我们对于整个数据集的改变,先将要改的数据只修改对应的内存页page,并不马上刷盘。晚些时候再在后台,通过集中的方式写盘(比如15分钟一次刷盘,将修改的内存页page,即dirt page,写到对应的磁盘页page)。
同时,我们对于修改的数据,写到redo log里,并快速地刷盘(比如:1秒钟1次刷盘),这样,万一掉电,损失的数据较小。
这样的好处在于:
1. 如果同一内存页在后台刷盘前,被修改了两次,那么我们就省了一次刷盘
2. 对于HDD,如果两次修改的两个页,在磁盘上位置上很接近,我们可以省一次磁盘定位的cost
3. 对于SSD,我们可以将一次一次零碎的写盘请求,集中大批量发送,从而提高SSD的并发度
4. 同时,异步写盘降低了Latency和提高了Throughput
所以,redo log是个冗余。如果不发生掉电事件,它可以不存在。但为了避免掉电损失全部的数据,以及顾虑每次都对page进行及时同步式地刷盘所带来的性能惩罚,我们做了个优化,利用Log对于磁盘的友好,来提高整个系统的性能Throughput同时将数据丢失data loss降低到较小。
#### binlog
binlog和redo log,有点类似。但redo log一般循环使用,所以,redo log只保持很少一段时间的操作记录(这样就节省磁盘),而binlog是将很长一段时间(你可以认为是历史所有的操作记录)保存下来。
binlog是为另外一个目的服务的:它不是为当前这个机器上的数据库服务,而是为其他数据库服务的。
对于MySQL,它可以组建成master/slave的replication模式,那么这个slave,要形成和master一模一样的数据,它就需要binlog这个Log。
类似地,我们可以在binlog里记录SQL语句,这样binlog不仅可以让MySQL再创建一个同样数据的slave,而且可以让其他类型的数据库(比如:PostgreSQL),也创建一个同样数据的数据库。
所以,从这个意义上讲:binlog就是一个数据库的数据。
### 集群系统
#### Aurora范例
随着互联网和云时代的到来,我们不满足一台数据库系统,我们希望数据库上云,而且是集群的。
一个比较经典的案例是Amazon的Aurora,它基于MySQL的底层,实现了云上的集群化,而且成功实践了"日志即数据库"(Log is Database)这个口号(slogan)。
下面两个架构图都是源自AWS的论文
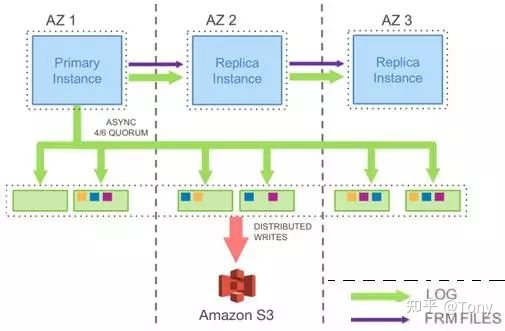
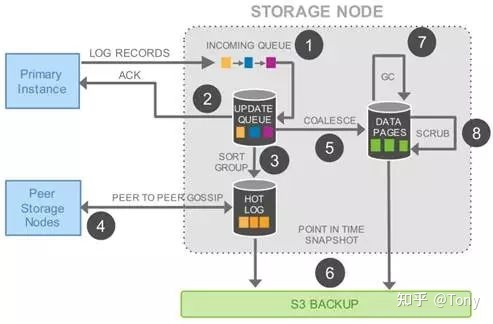
从上面两个图我们可以看出,Aurora在实现集群方案时,充分利用了Log
1. 计算和存储分离的核心,是Log
2. 多机集群同步的核心,还是Log,不管这个集群是计算集群,还是存储集群
#### 为什么Log适合集群
除了上面分析的Log的那些好处,我们看看集群还有什么特殊要求:
集群还有重大的要求,两个关键点:
1. 希望所有的data,在每个机器上都是一致的
2. 希望集群的任意一个组件,都不要只有一个
我们来看看Log,是如何适用这两个需求的
Log是Append-Only的,也就意味,我们不会对历史做出修改。不改的东西,非常容易保证一致性。
Log是高效的,不管是对内存,还是磁盘,而且特别适合磁盘。所以,我们可以让集群里的一个而且只有一个机器负责决定,如何wrie这个Log,这样,我们不仅高效,而且一致。
我们希望数据是多份,不要只有一个点才拥有数据,因此,我们可以让Log进行多机拷贝,从而避免单点的风险。
## Kafka is for Log
地球人(后端程序员)都知道,Kafka是为Stream服务的。而Stream,从其内部数据结构看,就是Log。
Kafka很庞大,我也无力对整个系统进行剖析,我只是做几个简单的总结:
1. Kafka内部的数据结构就是Log,而且Kafka只做好一件事,只为这个Log服务,因此高效
2. Kafka是分布式的(Distributed),因此,committed data会在所有集群的机器(node)上都有同样一份拷贝
3. 尽管Kafka只有一个master(或者叫leader),而且这个master可能变动,而且可能出现brain split现象(某个时刻有两个机器都认为自己是master),但是,它通过集群所有机器的共识(consensus),让committed data保值一致
4. Kafka这个共识(consensus),并不是通过Raft这种共识协议达成的,因此它还需要依赖Zookeeper这个底层来保证meta data的一致(Zookeeper内部的ZAB协议,类似Raft的基本原理,大道至同),这是个非常聪明的做法。因为Raft这种共识协议,并不高效(因为Raft做了两件事,即有Log,也有state machine,而且Raft必须依赖磁盘,而Kafka理论上可以不要磁盘)
如果想要详细了解这个不同,请参考我的另外一个文章:
## BunnyRedis向Kafka学习
不光BunnyRedis简单抽象为: Redis + Kafka
更重要的是:BunnyRedis依赖Kafka,从而实现了**Half Master/Master**这种架构,详细可参考:
1. [Redis的一致性问题](https://github.com/szstonelee/bunnyredis/wiki/Why-redis-consistency-problem)
2. [BunnyRedis的一致性](https://github.com/szstonelee/bunnyredis/wiki/BunnyRedis-consistency)
3. [BunnyRedis是什么](https://github.com/szstonelee/bunnyredis/wiki/Home)
4. [从Raft角度看Half Master/Master(两层解耦)](https://zhuanlan.zhihu.com/p/407603154)
