一些用户在做 DorisDB 的 POC 测试时,参照《DorisDB 企业版文档》进行了表模型选择、分区、分桶等基础配置后,查询性能离期望的理想状况可能还是会有些差异,或者想针对业务进一步优化以达到佳性能。这里,我们就借用一个用户 POC 时的调优场景,来分享一些 DorisDB 系统性能调优中的技巧,同时也简要介绍下 DorisDB 企业版可视化 profiling 工具的使用。如果您使用的是 DorisDB 标准版,可以通过文字版的 profiling 信息,用文中提及的一些方法优化。
下文将先介绍一些基础性的优化内容,包括如何优化 join、group by、索引等,再介绍针对不同方向上的一些优化,比如是提升单个 Query 的性能还是提升整体的 QPS 能力等。
遇到的问题
该用户在 POC 阶段优化性能时,总体遇到了下面 3 个问题,这些问题也是很多用户经常遇到的:
如何优化单个 Query 的性能,以达到秒级甚至亚秒级的响应速度;
如何提升系统整体 QPS 的能力,以让「一个大任务」(会拆分成很多小任务并行跑)的总时间尽可能短;
如何通过适当增加机器数量,进一步提升系统性能。
基本的优化方法上,主要是减少不必要的资源开销、增加并行能力,再利用系统的一些能力,比如 join 方式、谓词下推等,进一步减少资源使用。在每类问题的优化方向上,会有些小的差异,需要根据不同需求使用不同的优化方式和一些参数。
说明一下,下文只单纯考虑如何优化 SQL。至于机器、网络、安全、导入、预聚型合物化视图等方面的优化或使用,不在本文介绍范围。
如何优化
MySQL、Oracle 等数据库系统,都提供了 explain 、show profile 等功能来帮助性能优化。DorisDB 也提供了这两个功能,它会展示一棵“以 Fragment 为节点,以 Exchange 为边的逻辑查询树”。每个 Fragment 节点可能包含 SCAN、JOIN、数据传输等具体操作,Fragment 在执行时分成多少个物理执行实例、具体做什么事、具体的数据读取/计算/hash 构建等步骤的消耗时间等。一般我们直接使用「执行时间」来可视化、结构化地查看 SQL 执行结构、计算资源消耗情况等。
在 DorisDB Manager 的 Web 页面中,点击「查询」页,点击需要的「查询 ID」,就可以看到如下图的功能项,选择并具体查看。

不同优化方向时,需要有区别地看待一些资源消耗的节点。同时,不同数据量、不同类型的 SQL,可能效果也会有些差异。在整体优化思想的指导下,多多实验,对比和思考差异的原因,以得到业务优的 SQL 和配置。
基础优化
优化的主要思路:减少资源使用量。借助「执行时间」中的 profile 图,查看下图中的执行时间占比,优先优化占比高的处理节点。这里:
每个节点(算子)的进度条是执行时间占比。能直观地看到全局图中哪些节点耗 CPU 多、Scan 时间长;
行数是下面节点(算子)的总输出行数。对于性能有很直接的影响,往往“返回量大”代表着数据过滤效果不够、数据传输量大、后续处理更耗时。
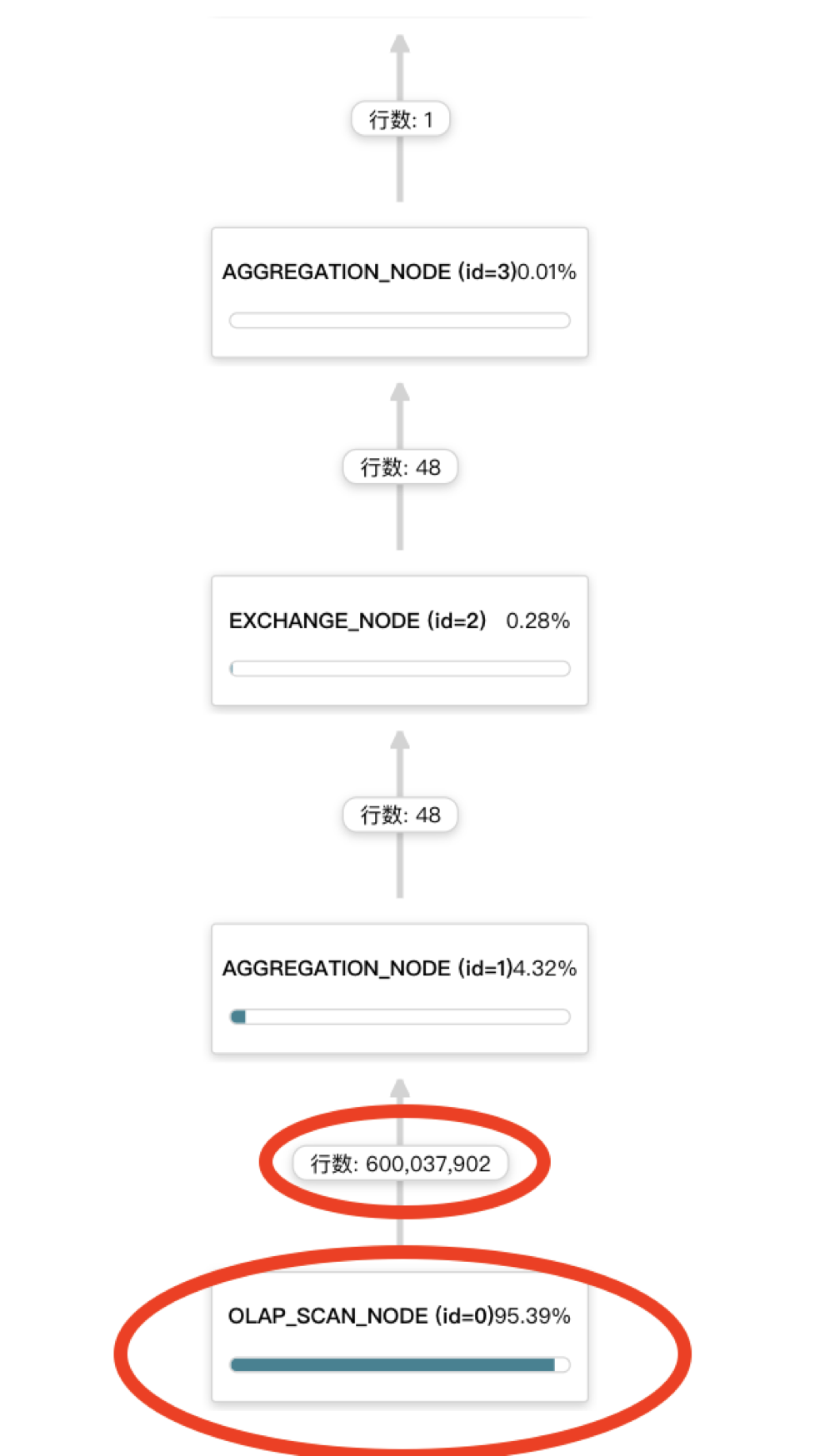
此次 POC 场景有两个 SQL,后续简称 CASE-A 和 CASE-B。可以参见本文后一张图,了解 CASE-A 的大致逻辑结构。其中每个 CASE 中的一些子逻辑会代称为「A 逻辑」、「B 逻辑」等。
一、优化基本的建表 SCHEMA 等
选择合适的表模型、分区、分桶;(这块很重要,后续会有另一个教程来说明)
没有特殊要求,尽量用 int 类型,减少字符串使用;
DATE 、DATETIME,不必要时尽量不要转换成字符串;
特别是会作为 join condition 的列,更应该使用 int、DATE 等简单类型。
在 CASE-A 中,有一个 join 的 on condition 中,原本是“将 DATE 转化成字符串来比较”,而修改成“使用 date_trunc() 函数直接进行比较”后,性能得到明显提升:整个大 SQL 提升5~10%。
-- 修改前
DATE_FORMAT(DATE_N,'%Y-%m-%d') = DATE_FORMAT(DATE_S,'%Y-%m-%d')
-- 修改后
date_trunc('day', DATE_N) = date_trunc('day', DATE_S)
二、优化 Join
一般 Join 操作会是优化中的一个重点,从 profile 看,也往往会发现 Join 节点执行时间占比比较大。
1、broadcast join 场景中调整 Join 的左右表顺序,使得“大表在左边、小表在右边”,以发挥 broadcast join 的优势。
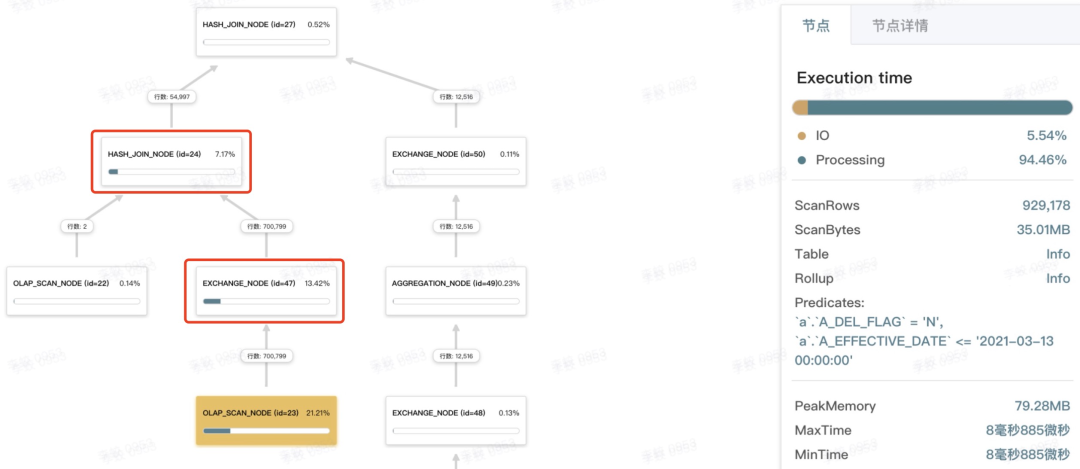
如下图所示,在 CASE-A 的「D 逻辑」中,有一个 hash Join 虽是 broadcast join(可以看到左节点不是 EXCHANGE_NODE),但执行中,需要把右表 700k 行的数据 broadcast 给左表,比较耗时。并且,右表是需要构建 hashmap 的,构建过程也会比较耗时(可以通过右侧「节点详情」进一步查看)。
通过调整左右表顺序,必要时增加 [broadcast] 的 hint,以实现“大表 join 小表”的优化。
SELECT *
FROM big_table JOIN [broadcast] small_table
ON big_table.x = small_table.x
调整后的效果是“立竿见影”(见下图):
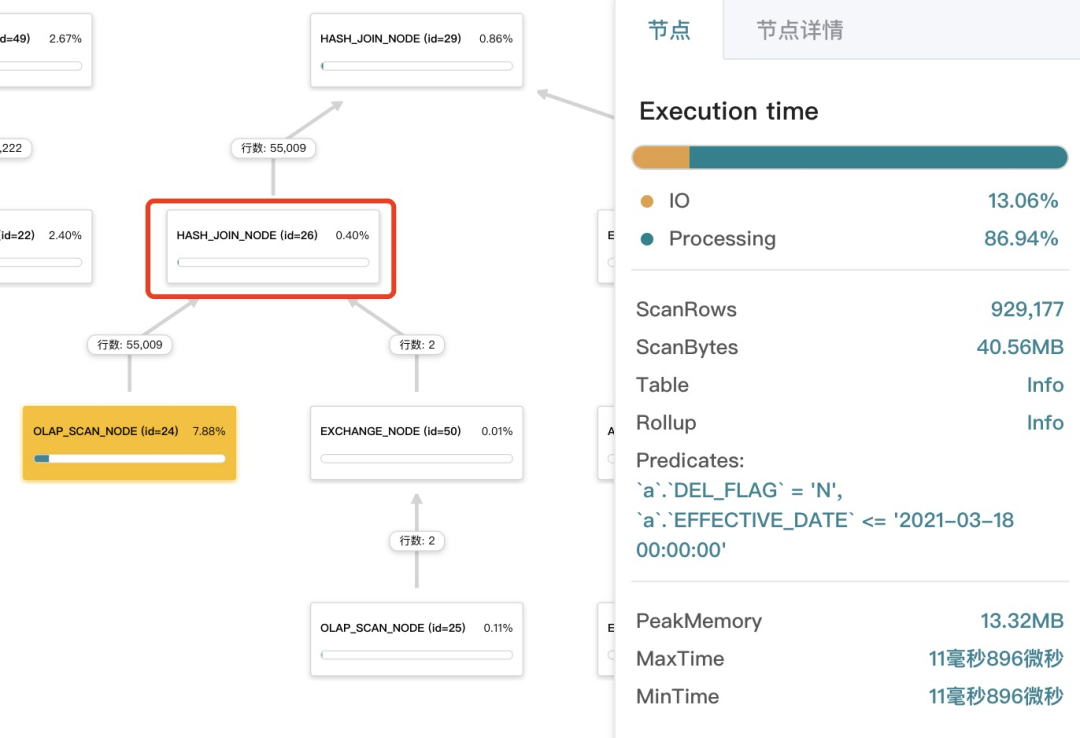
一方面,broadcast 右表数据以及构建 hashmap的耗时都急剧减小(见上下图中红线框的节点),直接减少约 20%;
同时,可以看到左节点 OLAP_SCAN_NODE 返回的行数也变少了很多(见上下图中黄底的节点)。这个功能叫「Join 的右表往左表谓词下推」:右表过滤结果很小时,DorisDB 可能会将右表谓词往左表下推,从而直接减少了左表的返回数据量(可以通过设置 hash_join_push_down_right_table 开关变量来验证效果)。终也节省了约13%。
新版本发布了基于 CBO 的 SQL 优化器,能够在很多场景下自动进行优化调整,就省去了上面手动优化的过程。不过,在某些场景下,CBO优化器的结果还有手动优化调整的空间。后续我们会持续优化CBO优化器。
2、适当的时候,可以修改 broadcast join 为 shuffle join。
在这个 POC 场景中,有几个 join 的左右表差不多大,并且数据量不大也不是很小(几百 K 行),系统可能默认会使用了 broadcast join,导致右表数据需要复制多份到多个 BE 节点。如果 BE 上还开启了并行度 parallel_fragment_exec_instance_num(设置大于 1 时),则就可能需要拷贝更多份的右表数据了:BE 数量 * 并行度。从而,导致 JOIN 节点的右子节点的 EXCHANGE 节点花费很多的执行时间。
这种情况下,可以尝试采用 shuffle join(在 SQL 中 join 修改成join [shuffle],即增加 shuffle 的 hint),看整体资源开销是否能降低。在这个 CASE-A 中,有个「C 逻辑」中调整 TA1/TA2/TA3/TA4 的 join 方式后,也有少量优化。
3、大表的 join,能用 colocate join 的尽量使用。
在 CASE-B 中,TX 表需要和 TA1/TA2/TA3/TA4 做 join,数据量中等(几百 K 到几 M 行)。其中 TA1~TA4 的表结构差异不大,但和 TX 的表结构不一样。从而 TX join TA1 join TA2 的过程中,都采用了 shuffle join, 这种类似的 4 个 JOIN 节点 + 4 对 EXCHANGE节点,耗费了整个 SQL 50% 多的执行时间。
虽然 TA1 先 join TX 后,能够过滤掉一些数据,使后续的 join 的数据量都变小,但是,这就不能使用上 colocate join 了。通过修改 join 顺序为 TA1 join TA2 join TX,并配置 colocate group:
-- 修改 TA1~TA4 的 colocate 属性
ALTER TABLE TA1 SET ("colocate_with" = "TA_group");
-- 查看是否修改完成。输出中几个表的`IsStable`为 true 时表示处理完成
SHOW PROC '/colocation_group';
此修改后,虽然导致后续输出数据量变大了一些,以及 JOIN 节点耗时也增加了一些,但由于减少了 EXCHANGE 阶段,从而整体还是节省了约 7% 的执行时间。
4、有条件的,可以尽量在多个语句中增加 where 条件。
一些复杂的 SQL 中,有些 on / where 条件可能并不一定能够完美地下推给每一个 SCAN、JOIN 节点。此时,可以尝试增加一些冗余的条件,以充分下推谓词,减少 EXCHANGE、JOIN 等节点处理时的数据量,减少执行时间。
三、优化 group by / group_concat
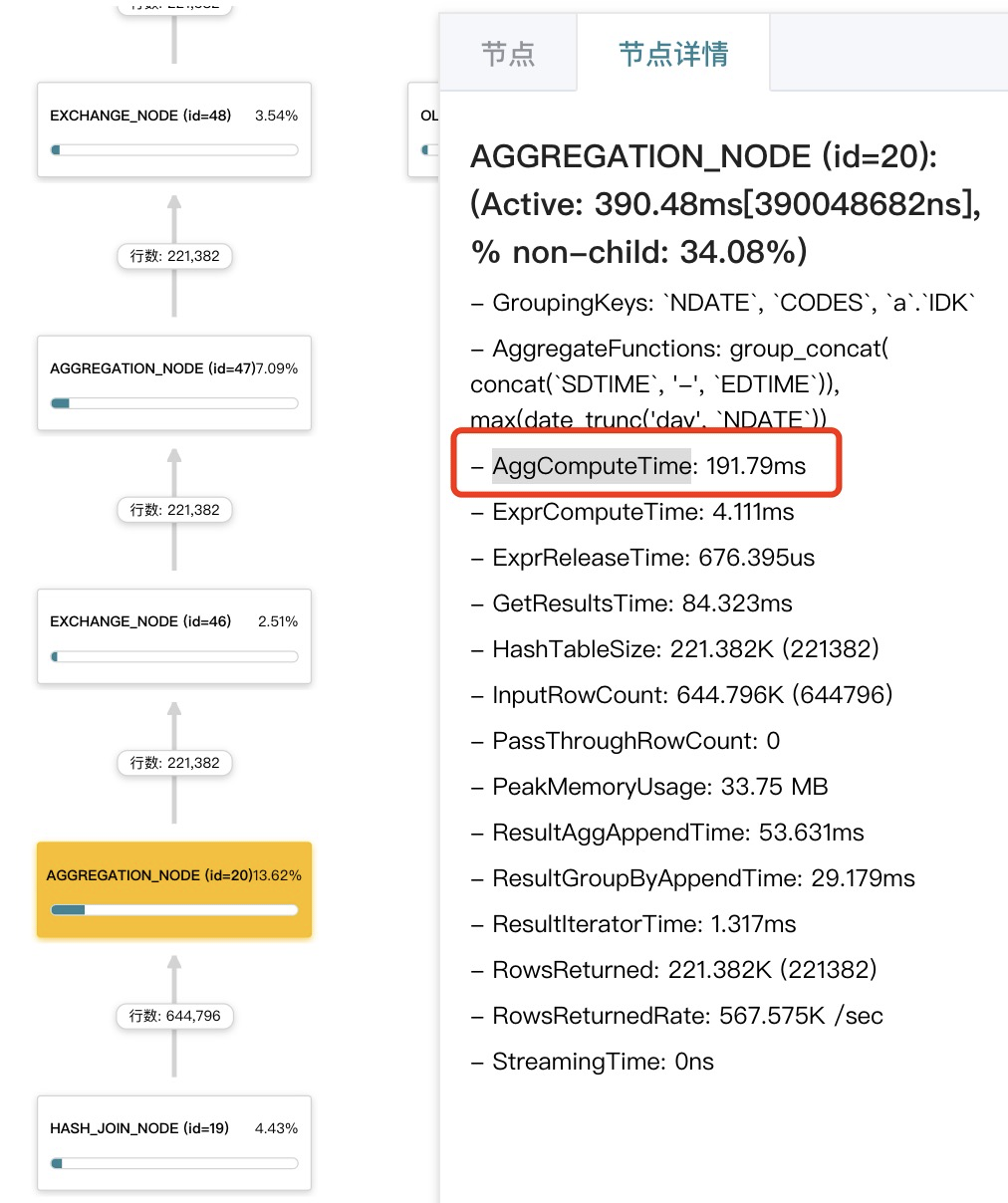
我们发现,CASE-A 中的「B 逻辑」很耗资源,占约 30%的执行时间,其中 group by + group_concat 的逻辑约占 20%。还可以在「节点详情」中看到 AggComputeTime 的时间,占了整个 AGGREGATE 节点一半的执行时间。
这个 POC 场景里,这里的 group_by + group_concat 其实是个「行列转换」,是否值得用「group by 的计算开销」来换「后续行数减少带来的性能提升」呢?我们做了一些如下的实验:
1、试验「列转行」是否有提升。
「B 逻辑」 中去掉 group by(从而也没有了 group_concat,这部分约占「B 逻辑」的20~30%的计算资源),减少了「B 逻辑」 本身的开销,但变成多行后,导致后续 3 个 join 的数据量变大(使得处理数据量变成原来的 2~3 倍),整体性能反而下降 3.3%左右。
2、试验 group_concat 的两阶段聚合是否有必要。
关于 group_concat 的两阶段聚合,系统中有个设置阶段聚合方式的参数:
-- 阶段的预聚合方式:auto, force_streaming, force_preaggregation
set streaming_preaggregation_mode = 'force_streaming';
如果阶段的预聚合前后的数据行数相差不大,也就是“预聚合没多大效果”,此时可以采取“关闭预聚合”。如上图中,预聚合前后分别是 644K、221K,算是有些聚合效果(见图中 id=20 的节点),但第二阶段的聚合基本没有多大效果,却也消耗了不少执行时间(见图中 id=47 的节点)。通过关闭预聚合(设置为force_streaming),整体性能提升约 3%(虽然节省了阶段的 group by 和聚合开销,但也导致了更多的网络数据传输开销)。
不过, 一般情况下,建议用户保留默认的“auto”设置,因为在不同的 SQL 和数据量下可能会有不同的效果。
四、优化索引
虽然 DorisDB 扫描数据的能力是很彪悍,但如果能减少数据扫描量,就能让查询变得更快。除了合理地使用聚合型物化视图(rollup 表)以减少数据扫描量外,一些场景下,通过增加“只改变 key 排序顺序”的物化视图,也能大大减少数据扫描量。
这里“只改变 key 排序顺序”的物化视图,类似 MySQL 中的能“索引覆盖”的二级索引。
在 CASE-A 中,对 SD 表新建了一个将 CODE_S 字段(一个 join 中很重要的条件过滤字段)放在前面的“只改变 key 排序顺序”的物化视图,从而迅速减少数据扫描量,终减少了约 3~5%的开销。
除了在普通扫描时增加“只改变 key 排序顺序”的物化视图能减少数据扫描量,在 broadcast join 场景下,对左表增加“只改变 key 排序顺序”的物化视图,也一样能减少数据扫描量,原理见上面「优化 Join」一节中说明的。在 CASE-A 中,TA3/TA4/KE2 的 3 个 join 分别建立“只改变 key 排序顺序”的物化视图,每个 join 减少约 2%的开销。
注意:建立“只改变 key 排序顺序”的物化视图,会导致表数据量增加,实际中需要酌情使用。或者,在明细模型中,可以去掉不必要的 key 和 value 列建立物化视图;在聚合模型中,可以去掉不必要的 value 列(不能减少 key 列,因为减少 key 列会导致聚合、改变语义)建立物化视图,从而减少物化视图的数据增长量。
五、其他一些优化探索
在这个 POC 场景中,还可以结合具体的业务特点,做一些 SQL 方面的特殊优化。比如 CASE-B 中,左右表数据量都不大的 3 个 join 也有不少开销,原因是 join on condition 的列很多,而这些列是由属性 ID_K 打成大宽表后的列,有上百个(即上百个 value 变成了上百个新列),然后其中有如下两段逻辑:
(A.k1 = 1 AND B.k1 = 1) OR (A.k2 = 1 AND B.k2 = 1) OR ...
A.k1 is null OR A.k2 is null OR A.k3 is null ...
段逻辑,理论上可以采用“两个二进制串求「位与」运算”;第二段逻辑,可以采用类似“判断整个二进制位串为 0”。不过,这个逻辑优化需要业务方先做字典,并求出固定的二进制串,同时系统当前也还不支持“二进制串位运算”,故而终没有实现。如果能实现,按 profile 图估计,将节省约 10%的计算量(3 个 join,每个约 3%)。
针对性优化
一、进一步提升单个 Query 的性能
如果系统整体计算资源充足,业务方更关注单个 Query 的时效性,则可以进一步优化“耗时关键路径”上的节点,从而让单个 Query 的时间尽可能短。
在 profile 图中,点击任意一个节点,可以看到如下图所示的信息。「节点」中的 MaxTime、MinTime,分别表示此节点的多个不同“执行实例”的大、小执行时间。同时 MaxTime 和 MinTime 差异过大时,一般说明有数据倾斜,或者有慢节点。
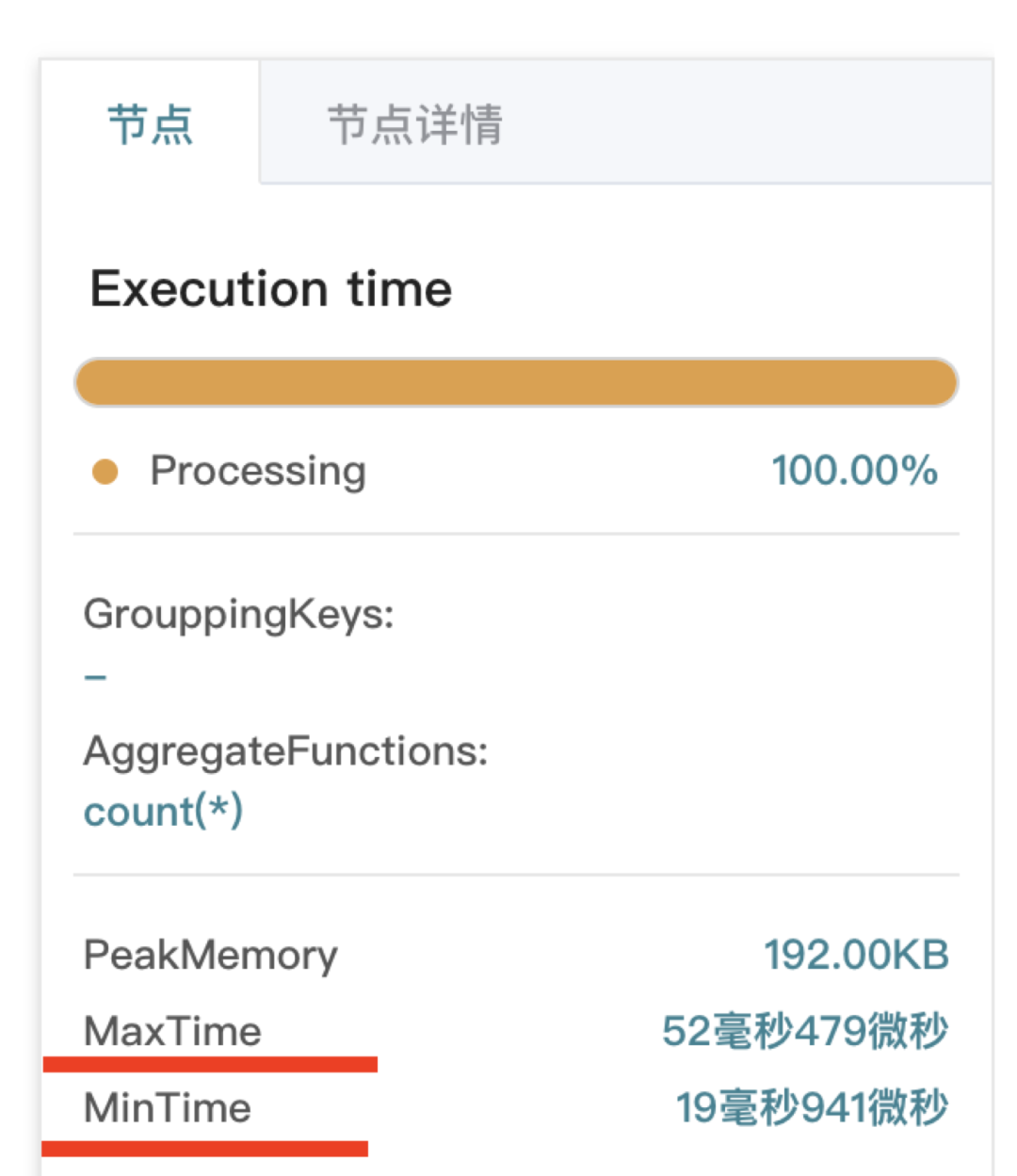
并且,任一父节点的 MaxTime 大于其所有子节点的大 MaxTime,将父节点与其具有大 MaxTime 的子节点相连,一层一层,组成一条“耗时关键路径”。如下表和下图所示,由 N1 -> N2 -> N4 -> N7 组成了此 Query 耗时的关键路径。下表为这颗逻辑树的几个重要节点的 MaxTime 情况。
节点
N1
N2
N3
N4
N5
N6
N7
耗时(毫秒)
698
579
63
540
176
158
347
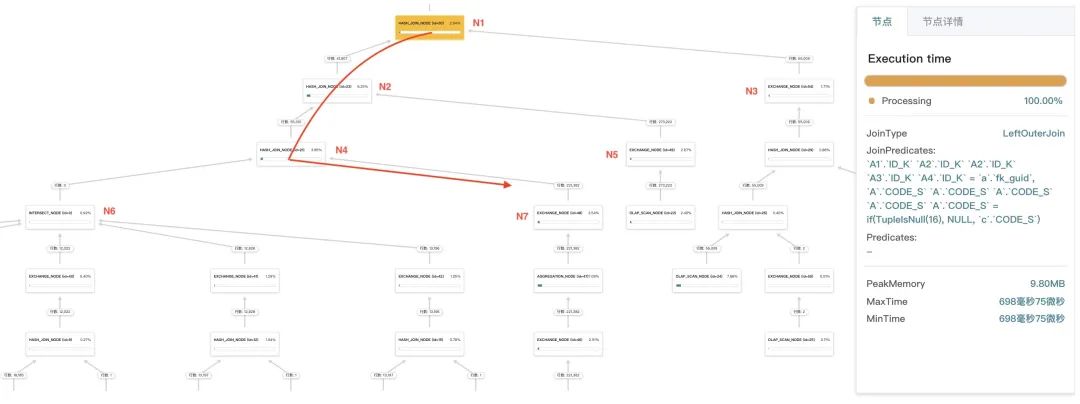
通过优先优化这条耗时关键路径上的节点,能不断降低整个 Query 的耗时。并且,除了前面的优化手段外,往往还有个简单而有效的优化方式,就是开启较多的并行度,以充分利用多核 CPU 的计算能力:
-- 一个查询,发到单个 BE 上的并发度,一般会设置 CPU核数/2 ~ CPU核数
set global parallel_fragment_exec_instance_num = 16;
注意:这里的一个节点的 MaxTime,一般是包含其所有子节点的执行时间的,也即这个节点从起始到结束的总的时间长度,一般会和子节点并行执行,或等待子节点部分或全部完成后再执行。因此,这个 MaxTime 并不是此节点的真正执行开销(称为ActiveTime)。
一些时候,随着优化的进行,关键路径可能会发生变化,从而也需要作出优化方向的调整。
一般情况下,往往 SCAN 节点会消耗比较多的计算资源,但由于其良好的并行效果和同步性,MaxTime 往往却比较小,因而在优化方向上,更多会优先优化 EXCHANGE 和 JOIN 节点。
二、进一步提升 QPS 的能力
在前面优化单个 Query 的性能时,常常会开启“较高的并行度”,以充分并行化利用资源。但是,在较高 QPS 情况下,开“较高的并行度”时,会有一些额外的代价,包括线程占用/切换、数据传输量(特别是在 broadcast join 时)、数据 cache 命中率等方面。因此,一般首先会调节并行度为 1:
set global parallel_fragment_exec_instance_num = 1;
而后,优先要优化大量消耗 CPU/IO 等资源的节点(如之前图中每个节点蓝色的滚动条占比大的节点),一般也往往是 Scan Node、Hash Join Node、Aggregation Node 等。
并且,往往会适当牺牲一下单个 Query 的性能,更多提高 QPS 进行压测,以充分利用系统的资源。同时,还可以根据业务特性,适当调整业务 SQL 逻辑,进一步提升业务性能。在这个 POC 场景中,有做如下一些调整,提升了整体性能:
一个查询中包含更多个 CODE_S。
业务的终需求是要查询几万个 CODE_S 得到几万份结果数据,通过一个 Query 中设置多个 CODE_S,牺牲单个 Query 的性能,却使得总体查询性能提升一倍。
耗时的类似/重复逻辑先进行整体物化,再进行后续查询。
CASE-A 中的「B 逻辑」资源消耗比较多,而这个逻辑的输入表其实不大,并通过 cross join 生成大量的结果数据。如果不分 CODE_S,先全部几万个 CODE_S 一起计算,并将结果存入临时表;而后使用到「B 逻辑」数据时,直接 join 这个临时表,性能应该能有 20%的提升。不过,由于业务逻辑变化和当时的 POC时间限制,终没有实施。
三、进一步提升多机并行性能
随着业务要求变高,或者业务处理量变大,业务方往往会希望通过增加机器,线性地满足不断增长的业务需求。
一方面,我们会通过 mysqlslap 或自制压测脚本等,通过压测得到实际的性能提升效果。另一方面,随着机器数量的变多,一些节点的 ActiveTime 却并不一定随着资源变多而相应地减少,甚至变得更多。
在 CASE-B 中,几个 JOIN 节点原本选择使用 broadcast 会稍微优一些,随着 POC 阶段从1 台机器变 2 台,再到 3 台甚至更多台,broadcast 的开销越来越大(因为需要复制多份数据),对于中等大小的表(几百 K 到几 M 行),可能会变成用 shuffle 更优。并且,当前 broadcast 时,是按照总的执行实例而不是 BE 的数量来分发数据的,会进一步加剧这个问题。因此,实际业务中,还是需要更多的测试和看 profile,以进一步确认效果,并选择合适的优化方式。
其他优化
除了以上的优化之外,DorisDB还有很多其他可以分析和优化的地方,比如优化数据倾斜问题、合适地分区分桶裁剪、更好的物化视图选择、判断网络传输是否成为瓶颈并优化等等。在实际的测试中,如果想进一步利用 DorisDB 和机器的性能,多多分析 SQL 和 profile,一定可以收获更多。我们也会在后续分享更多优化案例。
总结
本文通过案例,介绍了如何做一些有针对性的优化工作,同时也介绍了如何使用好 DorisDB 的可视化 profile 功能,帮助优化工作事半功倍。
说明一下,DorisDB的新版本发布了基于 CBO 的全新的 SQL 优化器,支持更复杂的相关子查询,支持更多启发式优化规则,基于统计信息进行 Cost 估算,可以更准确地进行 Join 左右表调整、Join 多表 Reorder、Join 分布式方式选择,以及列裁剪、更多谓词下推、等价谓词传递、公共表达式复用等等,能够让 TPC-H 执行总时间变成原优化器的1/3,部分 TPC-DS 复杂查询有30到50倍的提升。一些场景在新版中已经能够很好地被系统优化,也经过了很多用户的线上验证。新优化器可以帮助大家节省很多手工优化的时间。
————————————————
版权声明:本文为CSDN博主「weixin_42073629」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_42073629/article/details/120109010
