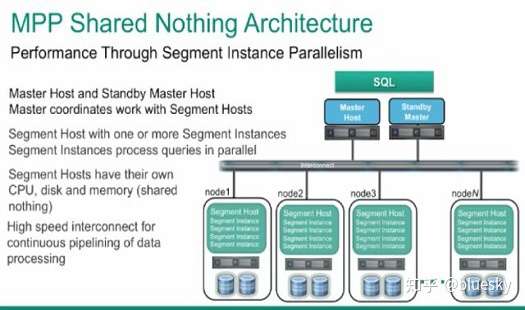
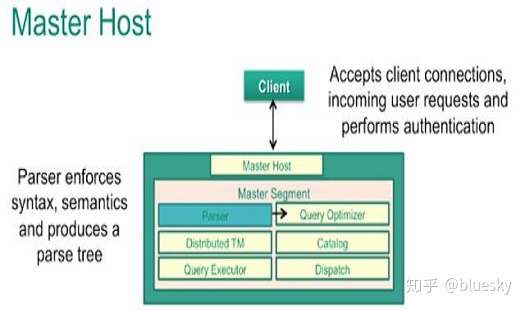
这是GreenPlum的master节点的一个处理流程,可以看出来这个过程就是PostgreSQL的执行处理模块:
parser:把客户的SQL输入转化成计算机能够识别的表达式
Query Optimizer:计算出数种可能的执行方案,选择一个可行的出来(可行的方案一般就是成本低的方案),实际上这是一个非常困难的任务,所以对于此模块,它需要知道整个cluster中的所有节点工作状态,比如节点的网络状况,存储状况,处理能力,当前繁忙程度等,通过这些细节的数据才能更加准确的找到一个合适的方案。实际上这里的Query Optimizer跟单节点的工作方式已经有了很大的不同,他将会是一个更复杂的,更加强大的控制中心。
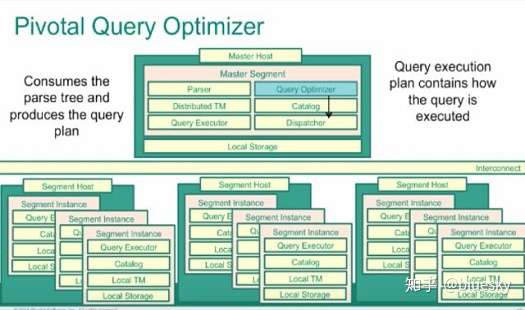
当处理优化完成之后,会把请求分发到优方案中涉及到的segment节点,这里实际上每一个segment节点都是一个独立PostgreSQL节点,负责存储整合整个cluster数据中的一部分。master把优化之后的查询任务分发给需要参与的segment节点,然后并行的去执行任务,后把结果返回给master节点,master节点在统一的对所有结果进行汇总整理。这里说明的是,GreenPlum大的架构两点就是他的MPP(Massively Parallel Processing)结构,此结构中为核心的就是master节点对所有segment节点的管理,能够产生能大化够并行处理的查询方案,也就是说多大程度的并行处理方案,就多大程度的能够利用分布式的segment节点,从而提供更高的性能。
如果你有阅读过google的关于MapReduce和DFS相关论文的话,对这个架构应该会非常的熟悉。
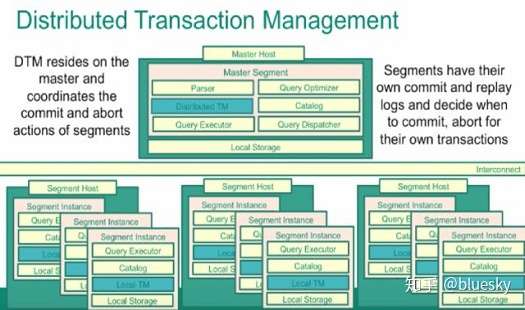
作为一个能够支持ACID的cluster数据库系统,必须要拥有一个强大的全局事务系统。GreenPlum同样使用了MVCC来做为并行事务处理的机制, 他拥有一个全局的统一的事务id,全局事务管理的逻辑在master中执行,虽然MVCC的工作原理类似于单节点的PostgreSQL,但是MVCC中涉及到的一些概念已经得到了扩展,比如snapshot,已经不单纯的指本机的在执行的TransactionID集合,而是整个cluster的TransactionID集合。当然由于每一个Segment节点还是一个PostgreSQL,所以他还是会有自己的commit和日志操作。也许就是因为全局事务管理的复杂性,和各自segment还拥有自己的部分重复处理,会导致一部分的性能影响。

作为一个cluster级别的系统,高可用肯定是一个再重要不过的话题了。为了提升系统的高可用级别,使用了基本的master节点镜像系统,会有一个独立的用于同步的进程来同步主节点的active主机和他的standby主机。实际上这个同步的过程的机制使用了PostgreSQL 的wal日志replication的机制。每一个segment节点也会有一个相应的镜像节点,如果一个节点宕机,会快的切换到他的备用节点。虽然这里没有讲述如何做到快速切换,但是我想肯定少不了一些辅助的监控和切换goon工具,还有就是配置Virtual IP的机制。
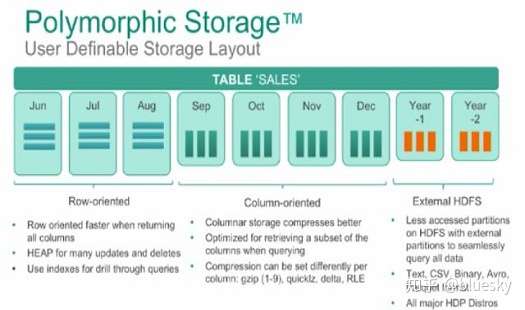
Greenplum支持多种类型的存储方式,行存储,列存储,第三方的分布式文件系统。关于这几种文件系统的选择,可以同样采用存储模式的通用的选择策略,比如OLTP选择行存储,OLAP选择列存储等。当然还要根据自己业务的情况来选择和使用。
关于更多的关于Greenplum的列存储的技术内容,请查看下面链接:
https://wiki.hsr.ch/Datenbanken/files/SEM_DBS_HS1516_Column_Stores_Greenplum_Egloff_Paper.pdf

在添加记录的时候,会引入一个关键的技术,就是distribution key,这个key就是我们用来把数据分配到不同的segment上面的依据。在创建table 的时候通过参数选项来制定distribution key的使用方式。下图就是一个根据distribution key来分配节点的数据结构图:
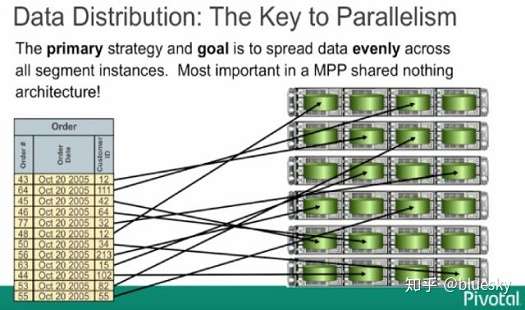
Greenplum分片处理机制
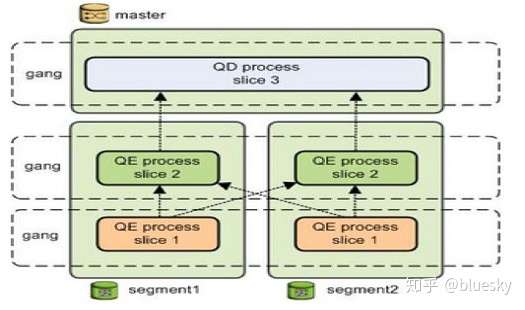
事实上,master节点在对客户发过来的请求进行分片的时候,会给每一个分片至少安排一个相应的处理segment节点,当然也会存在一个处理分片也需要多个主机一起协同完成的情况,这里Greenplum叫他gang,需要协同的segment会通过segment之间的内部网络进行通信,这里需要注意的是,虽然每一个请求的分片处理都是并行的,但是每一个分片中的涉及到多个机器协作的情况,实际上每一个分段的工作都是串行处理的,即个处理完成之后,把得到的结果发送给下一个处理分段,直到处理完所有的分片工作。
来源 https://zhuanlan.zhihu.com/p/263415513
