前言
有三种技术可以应对不断增大的数据量:
- 读写分离:将数据库设置成读写分离状态,一个 Master 节点对应多个 Salve 节点。
- 垂直分区:将不同的业务表拆散,分别存储到不同的数据库中,仍保持 Master/Salve 模式。
- 水平分区(分库 or 分表,sharding):将同一个业务表(或库)拆解成多个子表(或库),比如 db0、db1。
数据库中间件详解 这篇文章不只介绍了上述三种技术,还道明了数据库中间件设计的两种方案:基于代理服务器的 proxy 模式(需要对接不同数据源、不同应用技术栈的通信协议,必须保持高可用,隔离租户);基于封装 连接池或者 driver 为 sdk 的 smart-client 模式(需要对接不同数据源的通信协议,不需要对接不同应用技术栈的通信协议,天然去中心化)。TDDL 基于 smart-client 模式。DRDS 基于 proxy 模式。
TDDL
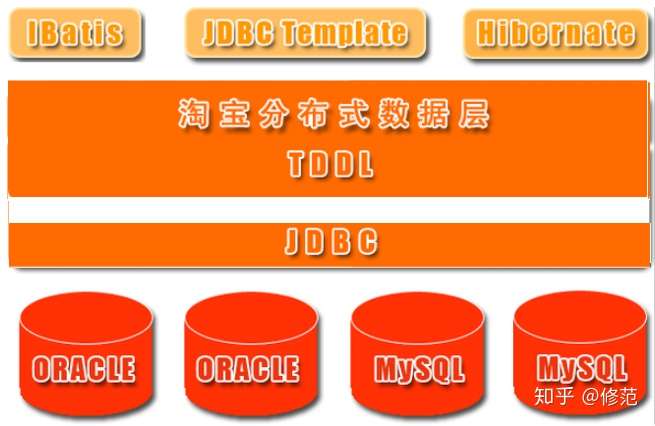
淘宝分布式数据层 Taobao Distributed Data Layer 位于持久层和数据库之间(持久层只关心对数据源的 CRUD 操作,而多数据源的访问并不应该由它来关心),它直接与数据库进行通信。它属于数据访问层(DAL 层),同类产品有 Hibernate Shards、Ibatis-Sharding 等。它基于集中式配置的 JDBC DataSource 实现,对持久层提交的 sql 只拼装不解析。TDDL 主要解决了以下问题:
- 数据访问路由,将数据的读写请求发送到对应的数据库。
- 集中式数据源信息管理和动态变更,支持数据存储的自由扩展。
- 遵守 JDBC 规范,支持 mysql 和 oracle 等多数据源。
- 带权重的读写分离,支持分库分表。
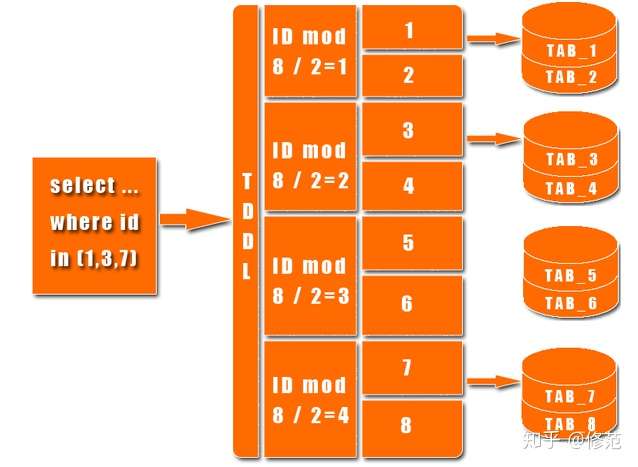
TDDL 是一个客户端 jar,它的结构主要分为三层:
- Matrix 层:核心是规则引擎,实现了分库分表逻辑,持有多个 Group 实例。主要功能逻辑为:sql 解析 => 规则引擎计算(路由) => 执行 => 合并结果集。
- Group 层:实现了数据库的主备分离逻辑,持有多个 Atom 实例。Group 层和 Atom 层共同组成了动态数据源。主要功能逻辑为:读写分离 => 权重计算 => 写 HA 切换(预防节点宕机,需要配置中心配合) => 读 HA 切换 => 动态新增 slave 节点(根据访问压力?)。
- Atom(TAtomDataSource)层:可以理解为一个数据库。主要功能逻辑为:ip, port, password, connectionProperties 等信息动态修改,动态化 jboss 数据源 => try catch 模式对线程计数,保护业务处理线程 => 动态阻止某些 sql 的执行 => 执行次数的统计和限制。
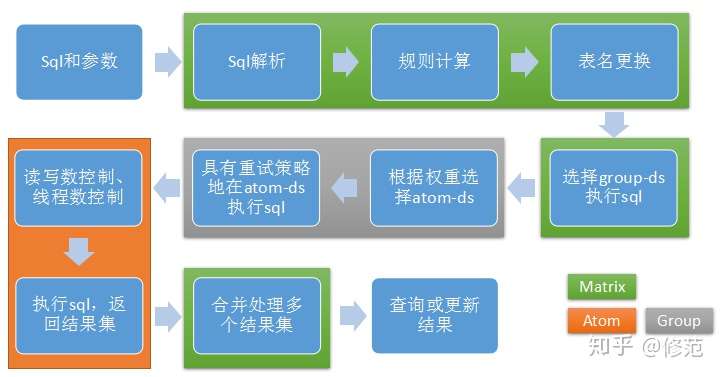
其他结构包含:
- tddl-client:应用启动时初始化配置信息(规则信息,各层数据源拓扑结构)
- tddl-rule:分库分表规则解析
- tddl-sequence:统一管理和分配全局 sequence(序列号)
- tddl-druid-datasource:数据库连接池(高效,可扩展性好),类 dbcp、c3p0
TDDL剖析 这篇文章介绍了基于 TDDL 已开源的模块以及 diamond 实现主备分离、分库分表逻辑的方法。
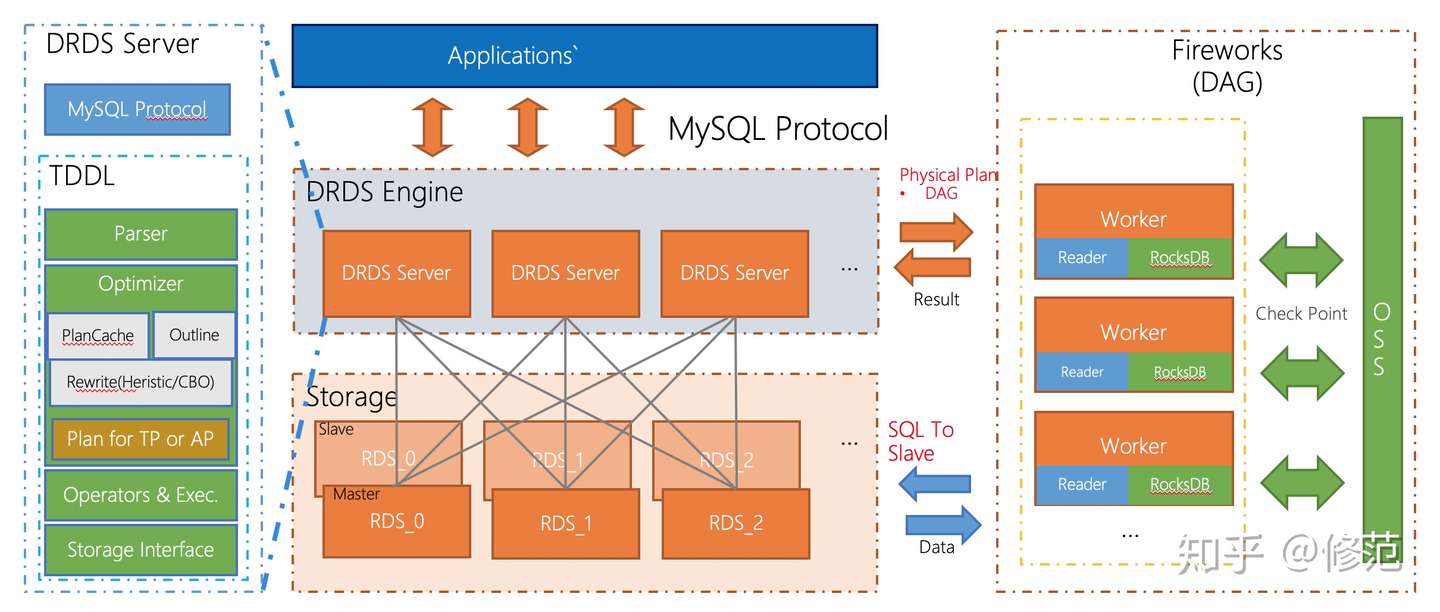
DRDS
分布式关系型数据库服务 Distributed Relational Database Service 的前身是 TDDL。它支持垂直拆分和水平拆分,因此有良好的扩展性;它通过两阶段提交支持分布式事务(此时 DRDS 服务器作为事务管理器,首先等待所有 MySQL 服务器 PREPARE 成功,然后再向各个 MySQL 服务器发送 COMMIT 请求。如果事务中的 SQL 仅涉及单个分片,DRDS 会将其作为单机事务直接下发给 MySQL;反之才会升级为分布式事务);它允许增加 RDS 实例的数量,以达到平滑扩容的效果;它支持读写分离,强读(显式事务中的读请求和写入操作将在主实例中执行,弱读在只读实例中执行;它支持通过全局二级索引能力创建二级索引表,以应对业务上的快速索引查询需求。计算能力上,DRDS 额外扩展了单机并行处理器(SMP,Symmetric Multi-Processing)和多机并行处理器(DAG),前者完全集成在 DRDS 内核中,后者,DRDS 构建了一个计算集群,运行时动态获取执行计划进行分布式计算,通过增加节点提升计算能力。
后记
今天我只是搬运工。
参考
分布式数据库中间件TDDL、Amoeba、Cobar、MyCAT架构比较
来自:https://zhuanlan.zhihu.com/p/100291291
