
今天是机器学习的第16篇文章,我们来继续上周KD-Tree的话题。
如果有没有看过上篇文章或者是新关注的小伙伴,可以点击一下下方的传送门:
【硬核】机器学习与数据结构的完美结合——KD-tree
旋转不可行分析
上周我们实现了KD-Tree建树和查询的核心功能,然后我们留了一个问题,如果我们KD-Tree的数据集发生变化,应该怎么办呢?
朴素的办法就是重新建树,但是显然我们每次数据发生变动都把整棵树重建显然是不科学的,因为绝大多数数据是没有变化的,并且我们重新建树的成本很高,如果变动稍微频繁一些会导致大量的开销,这明显是不合理的。
另一个思路是借鉴平衡树,比如AVL或者是红黑树等树结构。在这些树结构当中,当我们新增或者是删除节点导致树发生不平衡的情况时,平衡树会进行旋转操作在不改变二叉搜索树性质的前提下维护树的平衡。看起来这是一个比较好的方法,但是遗憾的是,这并不太可行。因为KD-Tree和二叉搜索树不同,KD-Tree中的节点存储的元素都是高维的。每一棵子树的衡量的维度都不同,这会使得旋转操作变得非常麻烦,甚至是不可行的。
我们来看下面这张图:
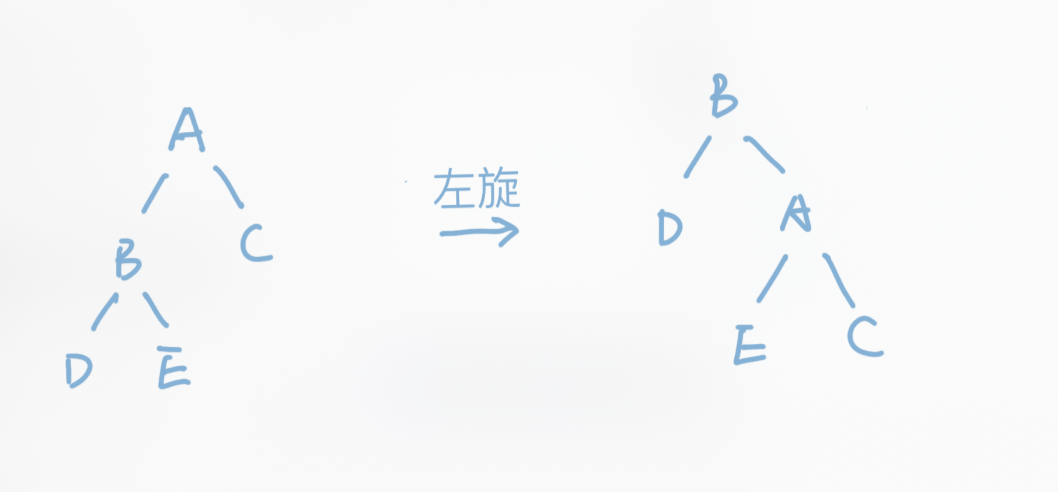
这是平衡树当中经典的左旋操作,它旋转前后都满足平衡树的性质,即左子树上所有元素小于根节点,小于右子树上所有元素。通过旋转操作,我们可以变更树结构,但是不影响二叉搜索树的性质。
问题是KD-Tree当中我们在不同深度判断元素大小的维度不同,我们旋转之后节点的树深会发生变化,会导致判断标准发生变化。这样会导致旋转之后不再满足KD-Tree的性质。
我们用刚才的图举个例子:
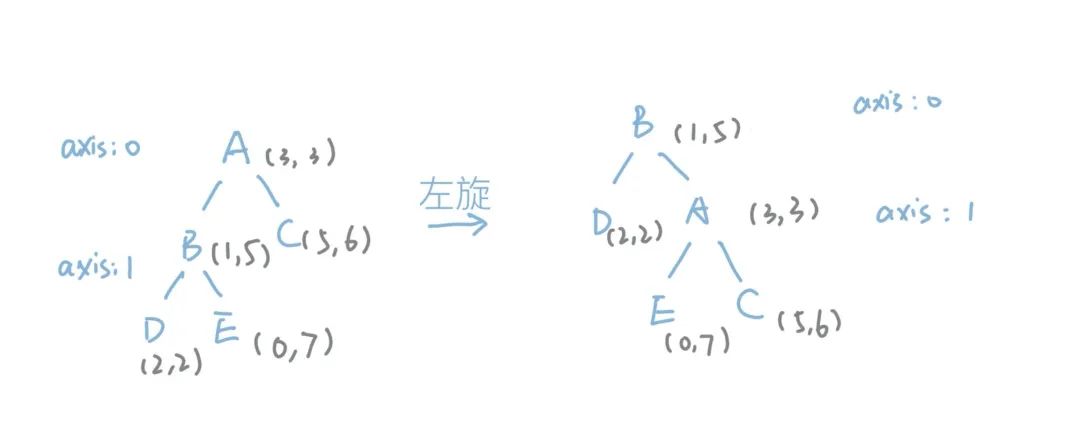
我们给每个节点标上了数据,在树深为0的节点当中,划分维度是0,树深为1的节点划分维度是1。当我们旋转之后,很明显可以发现KD-Tree的性质被打破了。
比如D节点的第0维是2,B节点是1,但是D却放在了B的左子树。再比如A节点的第1维是3,E节点的第1维是7,但是E同样放在了A的左子树。
这还只是二维的KD-Tree,如果维度更高,会导致情况更加复杂。
通过这个例子,我们证明了平衡树旋转的方式不适合KD-Tree。
那么,除了平衡树旋转的方法之外,还有其他方法可以保持树平衡吗?别说,还真有,这也是本篇文章的正主——替罪羊树。
替罪羊树
替罪羊树其实也是平衡二叉树,但是它和普通的平衡二叉树不同,它维护平衡的方式不是旋转,而是重建。
为什么叫替罪羊树呢,替罪羊是圣经里的一个宗教术语,原本指的是将山羊献祭作为赎罪的仪式,后来才衍生出了代人受过,背锅侠的意思。替罪羊树的意思是一个节点的变化可能会导致某一个子树或者是整棵树被摧毁并重建,相当于整棵子树充当了某一个节点的”替罪羊“。
替罪羊树的原理非常简单粗暴,不强制保证所有子树完全平衡,允许一定程度的不平衡存在。当我们插入或者删除使得某一棵子树的节点超过平衡底线的时候,我们将整棵树拍平后重建。
比如下图红框当中表示一棵不平衡的子树:
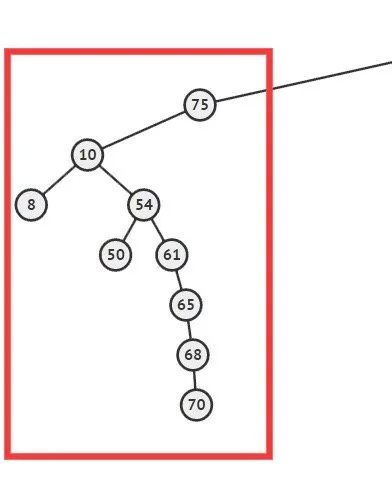
很明显,它不平衡地十分严重,超过了我们的底线。于是我们将整棵子树拍平,拍平的意思是将子树当中所有的元素全部取出,然后重建该树。
拍平之后的结果是:

拍平之后重建该子树,得到:
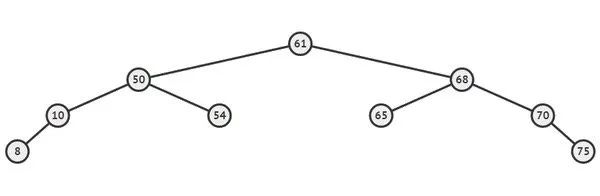
我们把重建的这棵子树插回到原树上,代替之前不平衡的部分,这样就保证了树的平衡。
整个原理应该非常简单,底层的细节也只有一个,就是我们怎么衡量什么时候应该执行拍平重建的操作呢?
这一点在替罪羊树当中也非常简单粗暴,我们维护每一棵子树中的节点数,然后通过一个参数alpha来控制。当它的某一棵子树的节点数和当前树节点数量的占比超过alpha的时候,我们就认为不平衡性超过了限度,需要进行拍平和重建操作了。
一般alpha的取值在0.6-0.8之间,因为理论上完全平衡的树这个占比值应该是0.5左右。
删除
在替罪羊树当中删除节点有很多种方法,但是大都大同小异,核心的思想是我们删除节点并不是真的删除,而是给节点打上标记,标记这个节点在查询的时候不会被考虑进去。
但是节点被打上标记而不是真的删除虽然实现起来简单,但是也有隐患,毕竟一个节点被删除了,我们把它留在树上一段时间还可以接受,一直留着显然就有问题了。不仅会占用空间,也会给计算增加负担。
针对这种情况,也有几种不同的解决策略。一种策略是不用理会,等待某一次插入的时候发现树不平衡,进行拍平重构的时候将已经删除的节点移除。另一种策略是我们也删除设置一个参数,当某棵子树上被删除的元素的比例超过这个阈值的时候,我们也同样进行子树的拍平重建。但是不论选择哪一种,本质上来说都是惰性操作。
所谓的惰性操作一般是通过标记代替原本复杂的运算,等待以后需要的时候执行。这个所谓需要的时候可以是以后查询到的时候,也可以是积累到一定阈值的时候。总之通过这样的设计,我们可以简化删除操作,因为加上标记不会影响树结构,所以也不用担心不平衡的问题。
新增和修改
对于KD-Tree的常规实现来说,修改和新增是一回事,因为我们会通过删除新增来代替修改。这么做的原因也很简单,因为修改某一个节点的数据可能会影响整个树结构,尤其是KD-Tree中的数据是多维的,所以我们是不能随意修改一个节点的。
实际上不只是KD-Tree如此,很多平衡树都不支持修改,比如我们之前介绍过的LSMT就不支持。当然不支持的原因多种多样,本质上来说都是因为性价比太低。
我们再来看新增操作,二叉搜索树的纯新增操作其实是很简单的,我们只需要遍历树找到可以插入的位置即可。KD-Tree当中的新增也是如此,虽然KD-Tree当中是多个维度,但是查找节点的逻辑和之前相差并不大。我们就顺着树结构遍历,找到需要插入的叶子节点即可。由于我们使用替罪羊树的原理来维护树的平衡,所以我们在插入的是时候也需要维护子树当中节点的数量,以及会不会出发拍平操作。
如果存在子树违反了平衡条件,我们需要找到上层的满足拍平条件的子树来进行拍平,否则的话底层的子树平衡了,但是上层的子树可能仍然需要拍平。注意这两个细节即可,其他的原理和普通的二叉树插入节点一致。
我们来看下代码,寻找更多细节:
def _insert_data(self, node, data):
# 子树节点的数量+1
node.size += 1
axis = node.axis
new_axis = (axis + 1) %% self.K
flat = False
# 当前节点的判断条件
# 小于等于则进入左子树,否则进入右子树
if data[axis] <= node.boundray:
# 如果子节点为空,说明已经到叶子节点,创建新节点
if node.lchild is None:
new_node = KDTree.Node(
data[new_axis], data, new_axis, node.depth + 1, 1, None, None)
new_node.father = node
node.lchild = new_node
else:
# 递归
self._insert_data(node.lchild, data)
# 回溯的时候判断是否引发树不平衡
if node.lchild.size >= self.alpha * node.size:
self.rebuildNode = node
else:
# 逻辑同上,找到叶子节点,回溯的时候判断是否不平衡
if node.rchild is None:
new_node = KDTree.Node(
data[new_axis], data, new_axis, node.depth + 1, 1, None, None)
new_node.father = node
node.rchild = new_node
else:
self._insert_data(node.rchild, data)
if node.rchild.size >= self.alpha * node.size:
self.rebuildNode = node
我们再来看下拍平的逻辑,拍平其实就是拿到子树当中所有的节点。如果是二叉搜索树,我们可以通过中序遍历保证元素的有序性,但是在KD-Tree当中,元素的维度太多,再加上存在被删除的节点,所以有序性无法保证,所以我们可以忽略这点,拿到所有数据即可。
def flat_data(self, node, data):
if node is None:
return
# 跳过删除元素
if not node.deleted:
data.append(node.value)
self.flat_data(node.lchild, data)
self.flat_data(node.rchild, data)
拿到所有数据之后也简单,我们只需要调用之前的建树函数,获得一棵新子树,然后将新子树插回到原树上对应的位置。
def rebuild(self):
data = []
# 拍平以rebuildNode节点为根的子树
node = self.rebuildNode
if node is None:
return
# 拿到所有数据
self.flat_data(node, data)
# 塞回到父节点当中去代替旧子树
father = node.father
if father is None:
# 如果父节点为空说明是整棵树重建了
self.root = self._build_model(data, node.depth)
self.set_father(self.root, None)
else:
# 判断是左孩子还是右孩子
position = 'left' if node == father.lchild else 'right'
node = self._build_model(data, node.depth)
if position == 'left':
father.lchild = node
else:
father.rchild = node
self.set_father(node, father)
这样一来,我们带增删改查功能的KD-Tree就实现好了。到这里,我们还有一个问题没有解决,就是复杂度的问题。
