导读
图像识别任务是计算机视觉领域内的一种基础任务,经过长期发展已经取得了傲人的成绩,现有的识别算法大多只能识别出图像中的单个物体,所以当图像中有多个物体时这类算法将失去作用。然而,现实生活中图片往往包含多个类别的物体,图像多标签识别技术在这种背景下应运而生。通俗来讲,多标签识别就是识别出一个图像中存在的多种物体,这也就意味着我们可以从多标签算法的预测结果中获取更多的图像信息,从而能够更加精准的对图片中场景进行判别。 多标签识别与检测、分割这类识别多物体算法相比也具有较为明显的优势,比如多标签识别不需要标注物体区域,可以极大节省标注成本;并且多标签识别可以识别出检测、分割算法无法识别的更加抽象语义,如黄昏、风景等。本文主要介绍多标签识别技术在58业务中的算法实践。
业务背景
58 同城做为国内领先的分类信息网站、专业的“本地、免费、真实、高效”的生活服务平台,包括本地服务、房产、招聘、二手市场、金融、汽车等业务板块,拥有庞大的活跃用户群,每天接受的图片流量高达数亿。
这也就意味着各个业务领域都有着大量的图像数据积累。在每个业务领域数据中,都会存在一些语义相似的图像。对于这类图像的挖掘,可以服务于发帖推荐、广告展示、违规识别等业务需求。例如在暴恐违规数据推审中,可以基于语义相似性,挖掘出定性为暴恐的违规数据;在黄页和部落中可以基于语义的相似性为用户推荐更加符合其倾向的发帖。

图1暴恐语义相似数据

图2 部落语义相似数据
图1、图2展示了58部分业务领域图库中存在的语义相似图像,我们归纳了业务中对语义识别的大致需求:
1、基于现有图像,推荐具有相似语义图像的发帖。
2、基于已有图像为评价标准,从现有数据库中检索出语义相似图像并对相似度进行排序。
因此设计的图像多标签识别方案,需要解决上述问题并满足相应的业务需求,且能够达到良好的落地性能。
技术背景
图像多标签识别是图像算法领域内基础技术之一,其概念为从一个图像中识别出多个前景类别物体。如图3所示

图3 多标签识别示例
3.1 多标签识别方法
多标签识别方法根据训练数据集是否存在区域标注,可划分为定位方法和分类方法两种。定位方法包括检测和分割算法,这类算法会对图像进行目标定位,检测出图像中的前景目标以及前景目标所在的区域。分类方法会对图像进行多节点二分类,识别出图像中存在那些前景类别。定位方法依赖于训练集合中的定位信息,但是定位信息的标注成本往往非常高,且当前景类别增多时,标注成本会倍数增长,这就导致定位方法在前景类别较多时实用性降低。分类方法不依赖于训练集合中的定位信息,标注成本相对低廉,适用于前景类别数量较大的场景,在实用方面相比定位方法更有优势。
3.2 典型开源数据集
开源数据集合是算法研究的一个重要组成部分,丰富的开源数据集合能够客观的评价算法模型的性能。为算法改进研究提供客观的数据依据。多标签识别领域典型的开源数据集合主要有以下几种。
MS-COCO数据集合为一个大型的、丰富的检测、分割和字幕数据集合,对于多标签识别包含有80类别,标注数据20w+,在算法评价中常作为训练集及测试集来评价算法性能。
PASCAL VOC2012 数据集合为基准数据集合之一、在对象检测、图像分割、多标签对比实验与模型效果评估中频频使用。包含有20类别,标注数据1.1w+ 。
Open Images V6 数据集合是当前规模大的多标签识别数据集合,包含类别为19958类,标注数据为917w+, 其中机器打标数据约894w+, 人工验证约23w+。数据集合多用于预训练模型为自有数据机器打标。
NUS-WIDE 数据集合主要由网站图片构成,包含约26.9w+数据,并包含5018类别。通常作为对比实验和模型效果评估的一种基准数据集合。
3.3 评价指标
3.3.1 mAP
多标签分类通用评价指标为MAP,可以全面评价模型性能,其公式如下
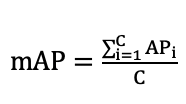
图4 mAP计算公式
其中C表示类别的数量,AP表示每个类别的Average Precision。
其中Average precision 分成宏观和微观两种模式,也就形成了宏观mAP和微观mAP两种mAP计算方式。
微观计算
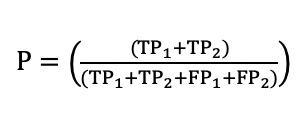
图5 Micro-average of precision
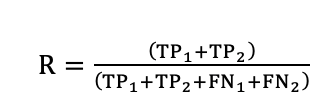
图6 Micro-average of recall
宏观计算
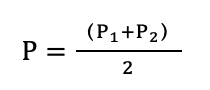
图7 Macro-average of precision
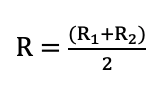
图8 Macro-average of recall
宏观计算区分类别,以类别为计算粒度;微观计算不区分类别,以图像个体为计算粒度。
3.3.2 Hamming Loss
Hamming Loss为直观也是容易理解的一个评价指标,它直接统计被误分类label的个数(不属于这个样本的标签被预测,或者属于这个样本的标签没有被预测)。如果指标值为0,表示所有的每一个data的所有label都被分对了。

图9 Hamming Loss
3.4 主流算法
图像多标签识别分类算法,当前主流方向主要为图像卷积网络,其基本的操作为将网络后输出的SoftMax层,替换成单节点的Sigmoid层,每个类别的输出为0~1 的一个概率值,可以根据设定阈值来确定图像中是否存在对应类别物体。
但是仅仅替换SoftMax层,会造成每个类别物体相互独立预测的现象,忽略了物体共生出现产生的关联性。近年来新的方法主要侧重于挖掘类别之间的关联性。主要的研究方法分成以下几个方向。
3.4.1 CNN+LSTM
这个方向比较有代表性的研究为2018CVPR的文章 《Multi-label Image Classification with Regional Latent Semantic Dependencies》,文中对RPN推荐区域特征进行编码,将区域编码输入到LSTM中产生区域编码特征的交互,输出交互特征进行多标签识别。

图10 RLSD网络结构图
网络挖掘类别相关性的方法主要基于LSTM中特征交互实现。
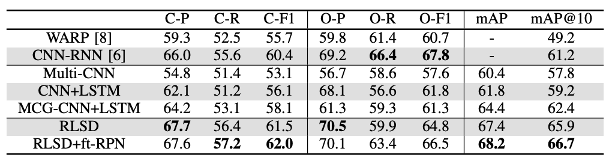
图11 RLSD中MS-COCO数据集合对比
3.4.2 多模态Attention
此领域内比较有代表性的研究为2020AAAI 文章《Cross-Modality Attention with Semantic Graph Embedding for Multi-Label Classification》,文中使用基于类别邻接矩阵的辅助网络生成类别编码。并将CNN提取的特征图与类别编码交互产生每个类别的激活图,从而生成每个类别对应的聚合特征,用来预测图像中所存在的前景物体。
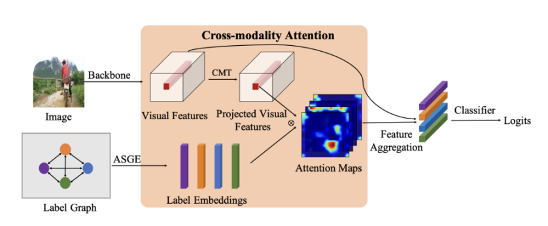
图12 CMA网络结构图
网络挖掘类别之间的关系是通过类别编码以及语义特征的跨模态attention实现的。
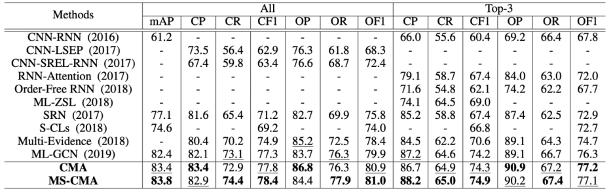
图13 CMA MS-COCO数据集合对比
3.4.3 图卷积网络
在这一领域比较具有代表性的研究为CVPR2019 《Multi-Label Image Recognition with Graph Convolutional Networks》,文中基于GCN图卷积网络学习各个类别的二值分类器,并对CNN提取的特征进行每个类别的二值分类,从而获得图像中是否存在具体类别。
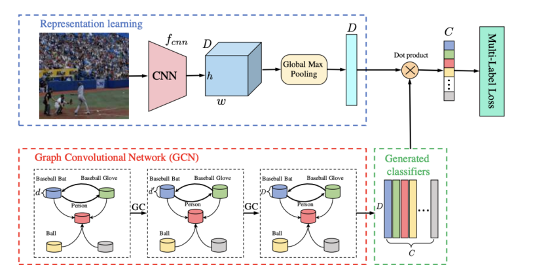
图14 ML-GCN网络结构图
文中网络关联提取方式为GCN,基于GCN网络产生类别间的交互,学习每个类别分类器。
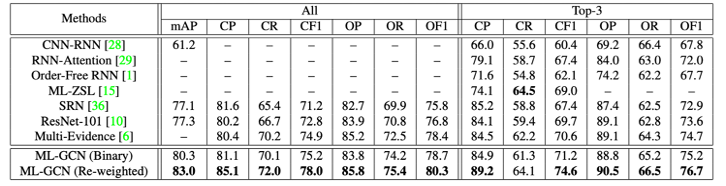
图15 ML-GCN在MS-COCO对比试验
3.4.4 损失函数改进算法
此研究方向比较有代表性的为阿里巴巴在2020年开源的算法《Asymmetric Loss For Multi-Label Classification》,文中主要考虑了图像中正负标签的不均衡问题。设计了新的Loss function 来解决这类问题,在不提升计算代价的同时能够有更高的率。我们在58场景下多标签分类所采用的方案即为此方案,具体详见4.2模型优化方案。
技术方案
为了满足当前的业务需求,我们设计了相应的技术方案,技术方案主要分成三个部分,部分为多标签数据集合构建方案,第二部分为算法模型优化方案,第三部分为算法输出方案。多标签数据集合构建方案主要是为了,构建适用于58场景下大规模多标签数据集,同时形成覆盖58大多场景的图像标签体系。算法模型优化方案主要对模型训练做相关优化,使得模型能够适用于类别多、数据量大的数据集合训练,同时着重于多标签识别存在的正负标签不均衡这一缺陷进行改进。算法输出方案主要是对算法后输出形式界定,输出形式的设定是以检索和推荐业务需求为基础。
4.1 数据构建方案
由于多标签打标随着数据增加,以及数据类别的增加,人工标注难度极高,且耗费成本极大,本方案中给出一种基于预训练模型加共生矩阵打标的方案,实现对无标签和单标签的数据进行多标签打标,构建训练和验证集合。打标策略步骤如下
(1)使用基于Open Image数据集合的预训练模型,对单标签和无标签数据集进行多标签打标。
(2)统计机器打标后每个标签的图像数量,如果小于整体数量的0.5‰则为稀有标签,去除此标签。
(3)剩余标签计算共生矩阵,当共生矩阵对应的标签概率小于0.01,则认为标签和其他标签相关性比较低。去除这些独立标签。
(4)将剩余标签基于wordnet进行语义合并,得到终打标的多标签数据集合。
使用多标签打标策略能够去除类别中稀有、独立的标签类别。
如图16展示在部落8346数据中使用预训练直接打标,与预训练+共生矩阵打标对比。展示方案打标策略有效性。
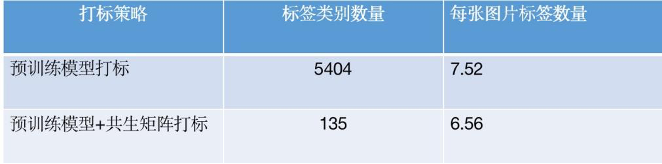
图16 机器打标方案对比

图17 打标方案实例对比展示
根据图17展示,基于预训练模型+共生矩阵打标减少了稀有、语义重复、独立标签,但是剩余标签依然可以表示出图像本身的语义。
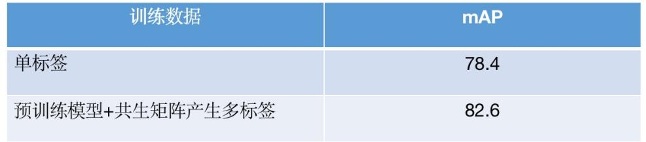
图18 自有数据单标签与预打标多标签对比
在完成上述可行性实验验证后,我们使用此数据构建方案完成58场景下500w+级别多标签数据集合构建。数据构建耗时约3周,与人工标注评估时间3人约1年相比节约大量成本。图19、20展示图像数据详细信息。
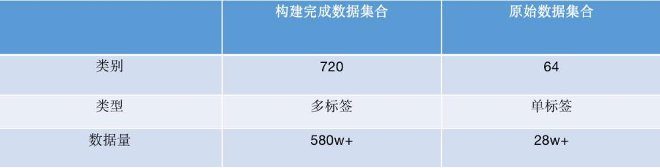
图19 构建后数据集合与原始数据集合对比
在构建数据集合的同时,对58场景下标签体系也做了相关梳理。构建类别约720类。如图20所示,标签体系划分为17个门类。
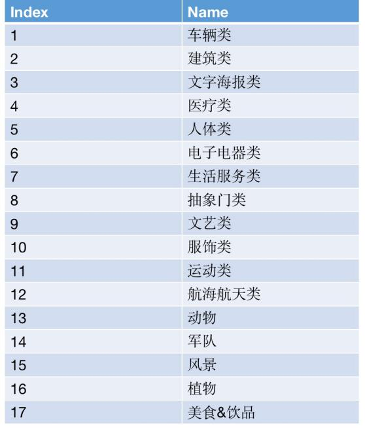
图20 标签体系门类
4.2 模型优化方案
模型优化方案主要采用文献4 中提出的ASL方法。ASL方法在单标签识别网络的基础上做了部分改进。其主要改进点有两部分,部分改进点为,将单目标识别网络后一层Softmax层替换成,与全集类别数量致的单节点Sigmoid层。这一改进主要是为了使得网络能够完成多标签识别任务。第二部分改进为,将通用的Focal loss(图21)变为新的ASL loss(图22)。
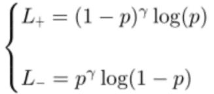
图21 Focal loss
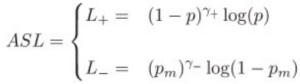
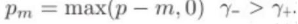
图22 ASL loss
4.2.1 ASL 优化分析
ASL方法改进的两个点中,第二部分loss function的改变对于多标签分类的性能提升至关重要。其改进思路如下,一张图像中只包含整体标签中的几类标签。包含的这几种标签我们称之为正标签,这张图片中没有包含的标签我们称为负标签。显然正负标签在一张图像中是极度不均衡,这将会导致在模型训练过程中正标签的梯度强调不足,从而导致准确性降低。为了解决这一问题,如图22 ASL loss function 对损失函数优化有如下两点。
(1)正负样本设置不同超参,对正负样本损失赋予不同权重。
(2)将原始负样本的P设置为Pm, 过滤掉评分低的样本,过滤正样本中负样本标记噪声。
经过优化后,ASL loss训练网络性能要优于通用的交叉熵以及Focal loss训练网络性能。基于loss function 性能对比如图23
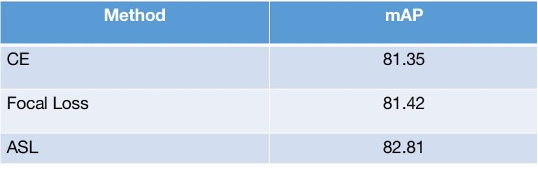
图23 loss function 在自有验证集合对比
与其他主流方案对比,ASL方案也有诸多优势。主要体现在,训练不需要辅助网络参数量少,更加适用于标签数量多、数据规模大的场景。如图24,ASL在取得以上优势的同时其在标准数据集合表现性能也优与其他主流方案。
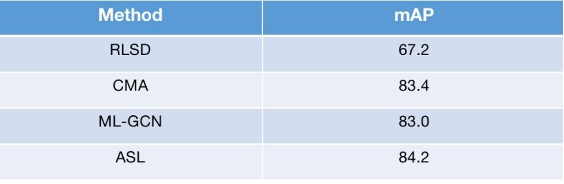
图24 MS-COCO数据集本方案与主流算法对比
4.2.2 ASL 应用
为了适用于58场景数据的训练,我们在ASL使用的过程中做了一些改变。为了增加模型推理速度,我们将原始的resnet101 大backbone 改变成resnext50 backbone。经过这一改变,模型推理速度明显加快, 且mAP指标降低较少(如图25)。

图25 Pascal-Voc数据集对比
同时借鉴文献3, 我们把resnext50 后feature map的pooling操作从Global avg pooling 更改为Global max pooling。在公开数据集合的验证,如图26 模型性能也有所提升。
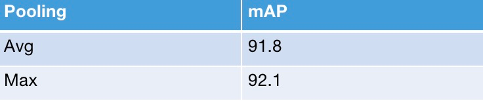
图26 Pascal-Voc数据集对比
在4.1方案构建的58场景数据集合中,模型的一些训练参数展示如图27

图27 模型训练各项参数以及结果
4.3 算法输出方案
方案的输出模式主要分成两种,一种输出为多个类别标签,另一种为多标签模型提取特征生成的2048维特征编码。两种输出的应用流程如图28所示。
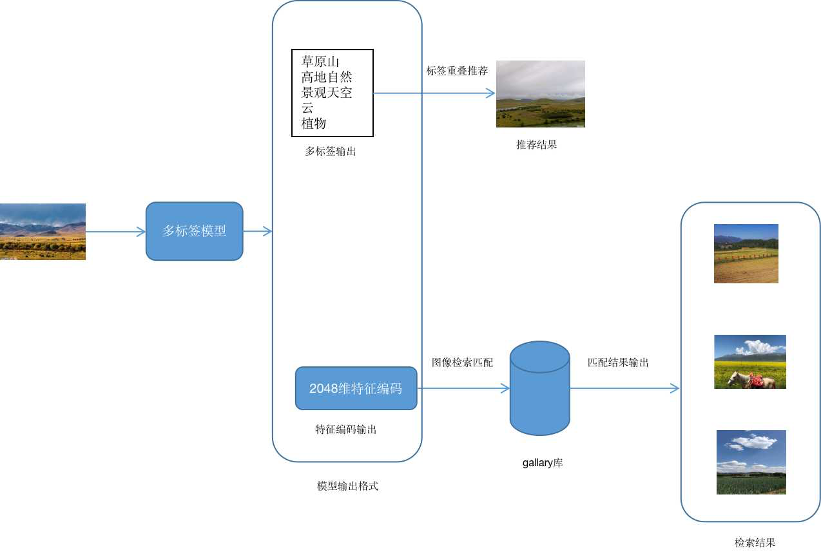
图28 模型两种输出应用流程图
种多标签输出如图29中实例展示。


图29 多标签输出
第二种编码输出,是由多标签模型语义特征图和编码算法结合生成。图30展示这类编码在中立暴恐数据中的验证结果。

图30 多标签backbone top-k召回率对比
图30 展示编码输出在中立暴恐数据集合中实际测试,随机选取135张图片作为query, 22000+图片作为gallary。
基于种多标签输出模式,可以对图像进行内容整合,将类别重叠较多的图像定义为语义相似图像,进而对相似语义的图像进行推荐。第二种特征编码输出模式,可以通过对图像编码相似度量计算,来评估图像之间是否相似,适用于相似图像推荐、异常图像检出等场景,如图31直观展示了在模型在图像检索场景下部分实例。


图31 多标签embedding 搜索top3
图31 展示query 搜索的top3, 列为query, 第2~4列为top3。
模型的第二种模型输出编码的区分度,依赖于模型对于图像特征提取能力,具体表现在模型能否激活图像中信息的重点区域。图32直观展示了模型对于中立图像的激活。其中蓝色区域为激活区域。


图32 模型对图像激活区域展示
经过对上述方案验证以及展示,证明我们设计58场景多标签方案有效性,经过数据构建方案能够快速有效的构建贴合于业务的多标签数据集合,节省了大量人工成本。经过模型优化方案可训练出推理速度快,训练显存小,易收敛,性能优的算法模型。经过输出模式设计方案输出两种模式,使得业务方能够灵活的根据需求选择推荐以及检索方案。
总结展望
我们基于实际业务场景,提出一套定制化的多标签识别算法方案,在当前验证中取得较好的结果。本文多标签算法研究是多部门技术团队共建项目的一个部分。在未来,我们将与共建项目其他技术相结合,形成多技术融合的特征编码以及多标签研究方案,进一步提升模型的特征提取能力,以提供通用化且有辨别性的特征编码。同时拓展业务应用场景,使得算法能够应用于推荐、异常挖掘、广告展示等诸多领域。
参考文献:
[1] Zhang J , Wu Q , Shen C , et al. Multi-Label Image Classification with Regional Latent Semantic Dependencies[J]. IEEE Transactions on Multimedia, 2016:1-1.
[2] You R , Guo Z , Cui L , et al. Cross-Modality Attention with Semantic Graph Embedding for Multi-Label Classification[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7):12709-12716.
[3] Chen Z M , Wei X S , Wang P , et al. Multi-Label Image Recognition With Graph Convolutional Networks[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019.
[4] Ben-Baruch E , Ridnik T , Zamir N , et al. Asymmetric Loss For Multi-Label Classification[J]. 2020.
[5] Kalantidis Y , Mellina C , Osindero S . Cross-Dimensional Weighting for Aggregated Deep Convolutional Features[C]// Springer, Cham. Springer, Cham, 2016.
[6] Ahrnbom M , Astrom K , Nilsson M . Fast Classification of Empty and Occupied Parking Spaces Using Integral Channel Features[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, 2016.
[7] Babenko A , Lempitsky V . Aggregating Deep Convolutional Features for Image Retrieval[J]. Computer Science, 2015.
[8] Wei X S , Luo J H , Wu J , et al. Selective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval[J]. IEEE transactions on image processing : a publication of the IEEE Signal Processing Society, 2017, 26(6):2868.
