
原文链接:http://blog.csdn.net/Linkthaha/article/details/100575651
近,在对公司容器云的日志方案进行设计时,发现主流的 ELK 或者 EFK 比较重,再加上现阶段对于 ES 复杂的搜索功能很多都用不上,终选择了 Grafana 开源的 Loki 日志系统,下面介绍下 Loki 的背景。
背景和动机
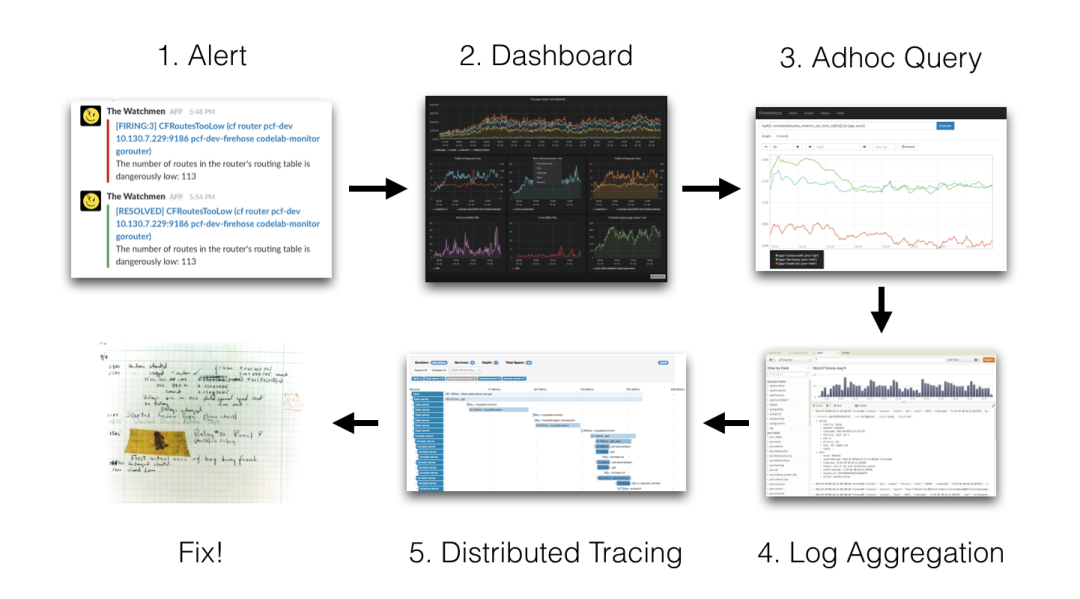
我们的监控使用的是基于 Prometheus 体系进行改造的,Prometheus 中比较重要的是 Metric 和 Alert。
Metric 是来说明当前或者历史达到了某个值,Alert 设置 Metric 达到某个特定的基数触发了告警,但是这些信息明显是不够的。
我们都知道,Kubernetes 的基本单位是 Pod,Pod 把日志输出到 stdout 和 stderr,平时有什么问题我们通常在界面或者通过命令查看相关的日志。
举个例子:当我们的某个 Pod 的内存变得很大,触发了我们的 Alert,这个时候管理员,去页面查询确认是哪个 Pod 有问题,然后要确认 Pod 内存变大的原因。
如果,这个时候应用突然挂了,这个时候我们就无法查到相关的日志了,所以需要引入日志系统,统一收集日志。
而使用 ELK 的话,就需要在 Kibana 和 Grafana 之间切换,影响用户体验。
所以 ,Loki 的目的就是小化度量和日志的切换成本,有助于减少异常事件的响应时间和提高用户的体验。
ELK 存在的问题
现有的很多日志采集的方案都是采用全文检索对日志进行索引(如 ELK 方案),优点是功能丰富,允许复杂的操作。但是,这些方案往往规模复杂,资源占用高,操作苦难。
因此,Loki 的第二个目的是,在查询语言的易操作性和复杂性之间可以达到一个权衡。
成本
全文检索的方案也带来成本问题,简单的说就是全文搜索(如 ES)的倒排索引的切分和共享的成本较高。
后来出现了其他不同的设计方案如:OKlog(https://github.com/oklog/oklog),采用终一致的、基于网格的分布策略。
这两个设计决策提供了大量的成本降低和非常简单的操作,但是查询不够方便。因此,Loki 的第三个目的是,提高一个更具成本效益的解决方案。
整体架构
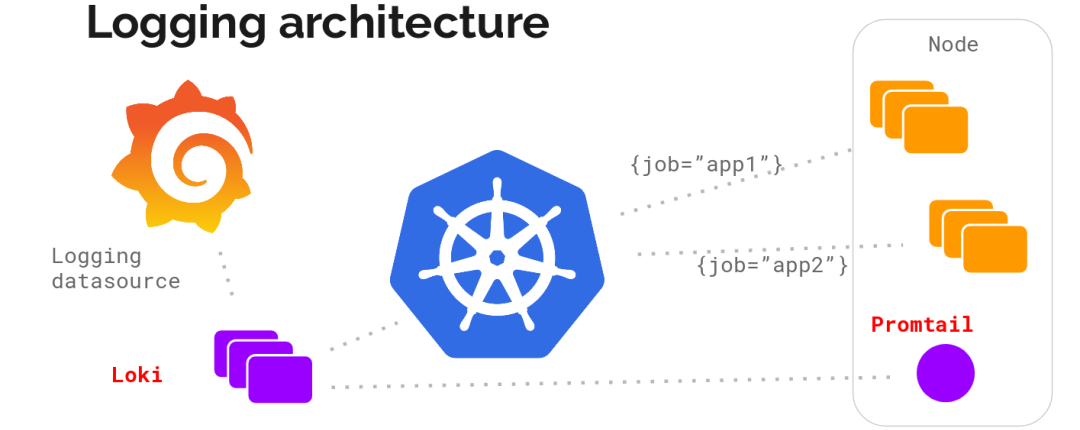
不难看出,Loki 的架构非常简单,使用了和 Prometheus 一样的标签来作为索引。
也就是说,你通过这些标签既可以查询日志的内容也可以查询到监控的数据,不但减少了两种查询之间的切换成本,也极大地降低了日志索引的存储。
Loki 将使用与 Prometheus 相同的服务发现和标签重新标记库,编写了 Pormtail,在 Kubernetes 中 Promtail 以 DaemonSet 方式运行在每个节点中,通过 Kubernetes API 等到日志的正确元数据,并将它们发送到 Loki。
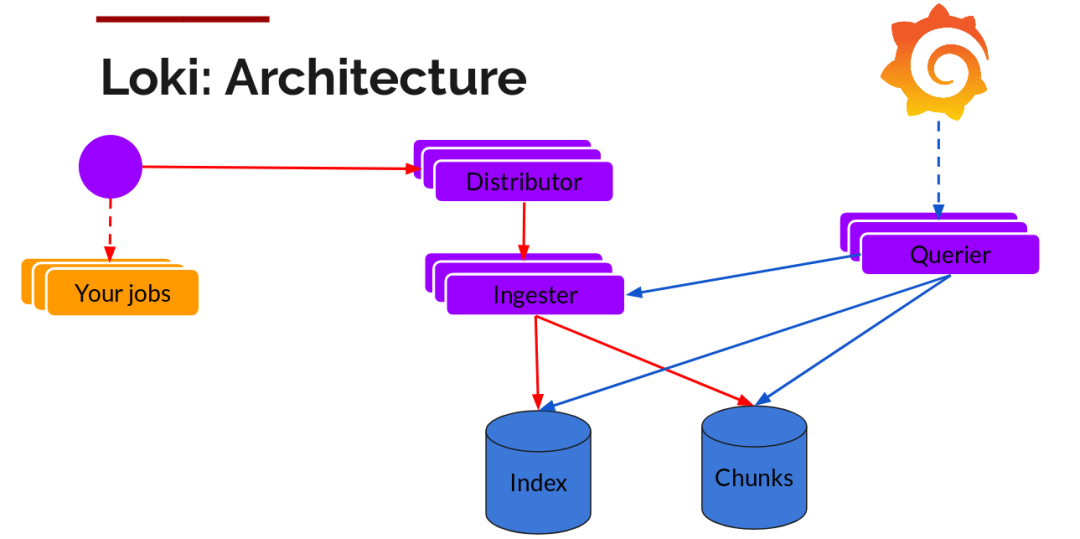
读写
日志数据的写主要依托的是 Distributor 和 Ingester 两个组件,整体的流程如下:

Distributor
一旦 Promtail 收集日志并将其发送给 Loki,Distributor 就是个接收日志的组件。
由于日志的写入量可能很大,所以不能在它们传入时将它们写入数据库。这会毁掉数据库。我们需要批处理和压缩数据。
Loki 通过构建压缩数据块来实现这一点,方法是在日志进入时对其进行 Gzip 操作,组件 Ingester 是一个有状态的组件,负责构建和刷新 Chunck,当 Chunk 达到一定的数量或者时间后,刷新到存储中去。

此外,为了冗余和弹性,我们将其复制 n(默认情况下为 3)次。
Ingester
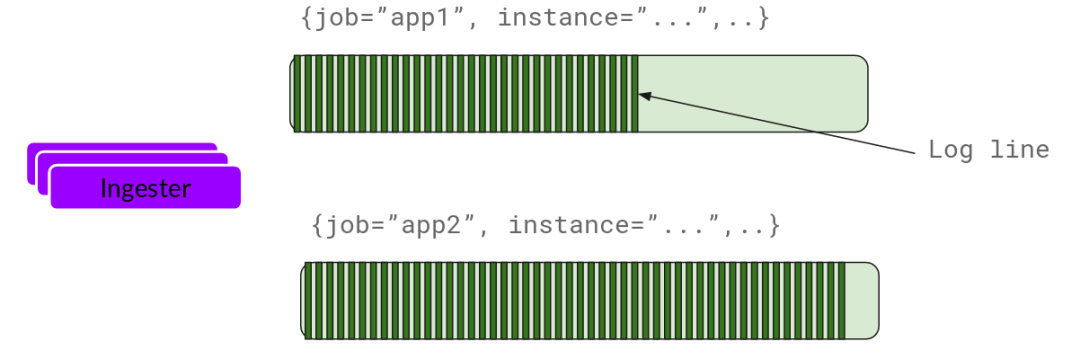
基本上就是将日志进行压缩并附加到 Chunk 上面。一旦 Chunk“填满”(数据达到一定数量或者过了一定期限),Ingester 将其刷新到数据库。
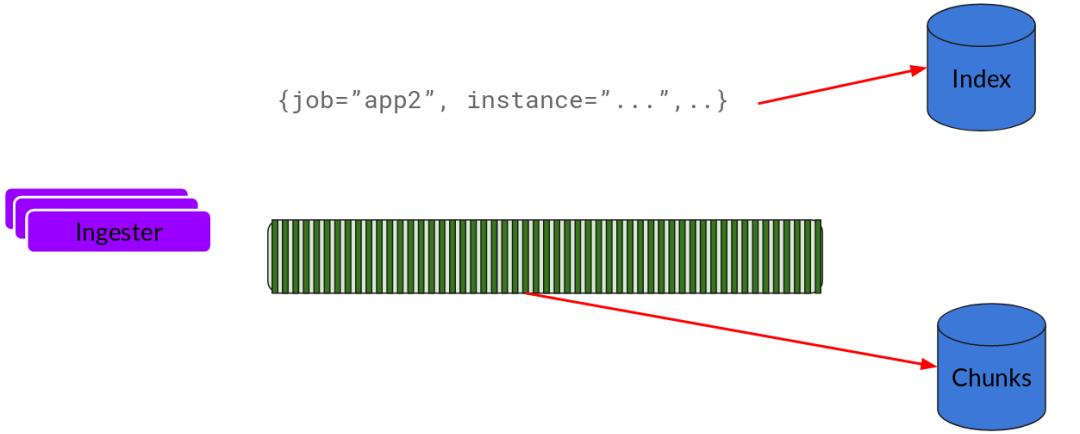
刷新一个 Chunk 之后,Ingester 然后创建一个新的空 Chunk 并将新条目添加到该 Chunk 中。
Querier
读取就非常简单了,由 Querier 负责给定一个时间范围和标签选择器,Querier 查看索引以确定哪些块匹配,并通过 greps 将结果显示出来。它还从 Ingester 获取尚未刷新的新数据。
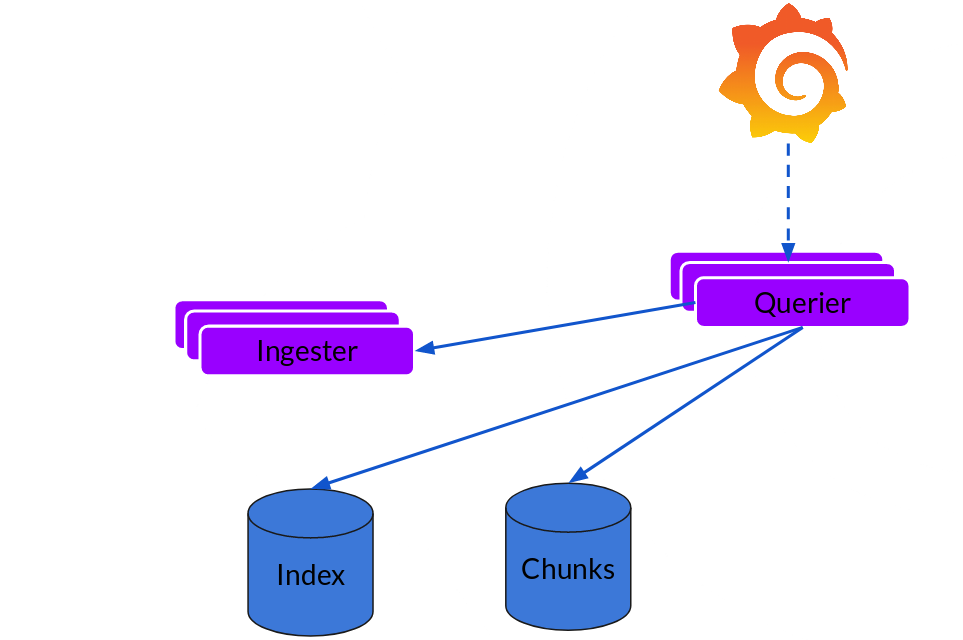
可扩展性
Loki 的索引存储可以是 cassandra/bigtable/dynamodb,而 Chuncks 可以是各种对象存储,Querier 和 Distributor 都是无状态的组件。
对于 Ingester 他虽然是有状态的但是,当新的节点加入或者减少,整节点间的 Chunk 会重新分配,已适应新的散列环。
而 Loki 底层存储的实现 Cortex 已经在实际的生产中投入使用多年了。有了这句话,我可以放心的在环境中实验一把了。
