第 一 部分 ASM条带概述
11GR2的ASM中,有两个很诱人的参数:_asm_stripesize、_asm_stripewidth,条带大小和条带宽度。貌似通过这两个参数,我们可以对条带进行更多的控制。但这两个参数并不是设置了就可以使用的,实际情况如何呢、这两个参数到底对我们的IO有什么影响呢,还要通过实验来确定。
我们可以通过两种方式来观察ASM的条带,一是直接用KFED工具,读取ASM中文件的kfffdb结构,此结构中有kfffdb.strpwdth、kfffdb.strpsz两个域,看名字就知道,这两个域分别刻录了文件的条带宽度和条带大小。 另一种观察ASM条带的方式,就是通过 “揭密Oracle之七种武器二:DTrace语法:跟踪物理IO http://www.itpub.net/thread-1609235-1-1.html ”提到的方法,跟踪操作系统驱动层的IO信息。通过IO的分布、IO大小,来了解条带的影响。 好,我们将两种方式都采用,结合起来判断。 先来个图,了解一下条带大小、宽度,AU大小的影响吧: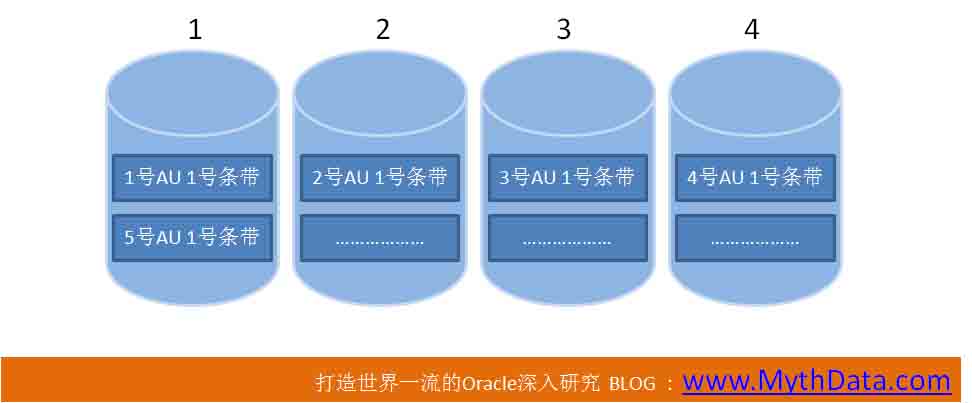
图1
上图例子,磁盘组中共有4块盘,编号分别是1至4。
另外,AU大小和条带大小相同,条带宽度为1。比如,假设上图AU大小为4M。条带大小也是4M,条带宽度为1。一个条带正好占一个AU,每个AU中只有一个条带。
段数据的个4M在1号盘1号AU 1号条带,第二个4M在2号磁盘2号AU 1号条带,等等,以次类推。 11GR2的ASM,可以说一共有两种条带类型:不可调粗粒度,可调细粒度。 粗粒度条带下,条带大小、宽度不可调。条带大小将一直等同于AU大小,条带宽度一直是1。也就是一个条带只在一个磁盘中,不会跨越磁盘。 10G、11G默认的AU大小都是1M,这点不用我强调了吧。而且,默认情况下,ASM的条带是“不可调粗粒度”。也就是AU大小1M,条带大小也是1M,条带宽度为1。这意味着数据会以1M为单位,平均分布到磁盘组所有磁盘中。也就是ASM保证1M数据逻辑上是连续的。如果段的区大小也是1M,哪么,全表扫描时,一次IO可以在一块磁盘上一次读1M数据。 高于1M的AU,个人认为,意义不大。因为大多数OS中,大的IO大小就是1M。 (---------新修改: 这是以前的看法,在之后我又做了很多测试,高于操作系统IO大小限制的IO,对于提高全表扫描的性能,还是很有帮助的。 可以参考30楼、33楼我的回复。) 就像我们上面例子中所说,如果AU、条带大小是4M,ASM虽然可以在每个磁盘上连续存储4M数据,但发生IO操作时,每次IO的大小大还是1M,连续的4M数据,还是需要4次IO才能操作完。 (--------新修改: 这段也是以前的看法,经过测试,如果AU、条带大小是4M,4次IO有可能是连续的。4次连续的IO,比4次不连续的IO性能要好很多) 我们刚才一直在说大IO操作。如果是小IO操作,在OLTP中,更多的是8K的小IO操作。对于Redo,则更多是1K、2K甚至512字节的写IO操作。如果进程要读、写8K数据,AU大小、条带大小是否对8K读、写有影响呢? 答案是基本上无影响。根据AU、条带规,进程先计算出要读、写的8K数据在哪块磁盘中,然后,直接到这块磁盘上读、写8K就行了。 无论条带多大,小的IO大小都是512字节,进程想读、写多大,就读、写多大。不必一次读、写一个条带。 好,下面再看下一个图: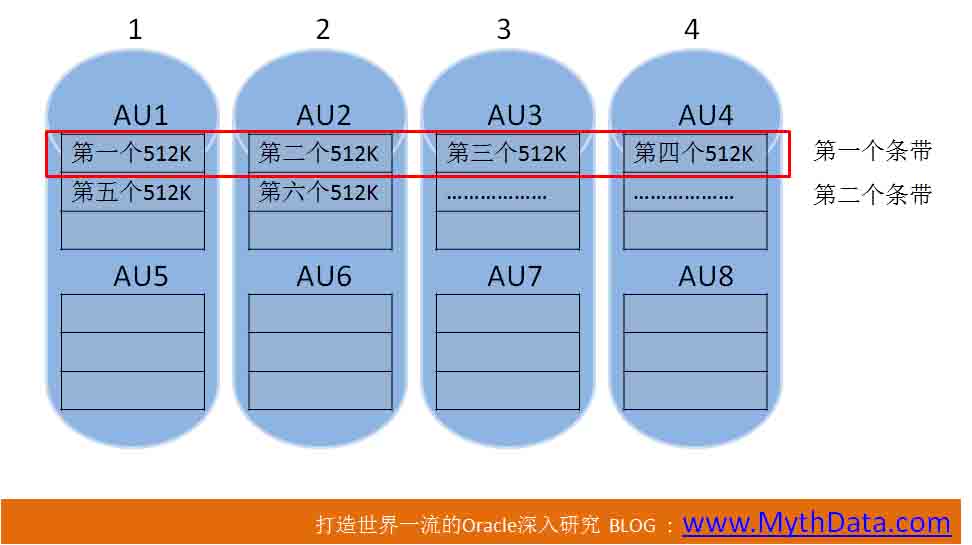
图2
上图仍以四块盘的DG为例。假设AU大小为4M,条带大小为512K,条带宽度为4。
千万不要认为这样的假设在ASM中不成立。有人说条带大小乘以条带宽度必须等于AU大小。Oracle中没有这样的限制,后面我们有这方面的测试。 图中已经画的很明白,表的个512K,在AU1中,第二个512K,在AU2中,等等。 其实,AU、条带这些东西,就是决定了空间是如何被使用的,数据是如何被存放的。 在上图中,如果要读取1M连续数据,要从两个盘读。也就是如果表的区大小是1M,这一M会被分隔到两个盘中。1M的区,在上图中,将占半个条带。 下面,讨论一个常见问题,这种小条带方式,和前面的大条带方式,哪个更好?这个问题真的不能一概而论了,流行的说法:大条带、大AU适合数据仓库,小条带小AU适合OLTP。这种说法太笼统。我们还是要理解ASM的IO方式,根据应用访问数据的特点,做合适的选择。
好,正确的废话我不多说,接前前面的例子,以图1、图2的ASM DG为例,图1是4M AU,4M 条带,条带宽度为1。图2是4M AU,512K条带,条带宽度为4。假设表的区大小是1M,全表扫描时读取一个区,谁更快? 答案是图1中的DG会略快一点点。 只是快一点点,原因是这样的,1M的区,在图2的DG中,会被存放在两个盘中。读取1M数据时,进程要到两个盘中各读512K。这两个读操作,不是同时的,而是先后的。 如果是同时读两个磁盘,哪么图1与图2的方式,读取1M数据的速度将是一样的。我在“35岁总结”哪篇文章中(突然35岁:捡点我的职业生涯 http://www.itpub.net/thread-1602563-1-1.html),提到过Redo同一组中两个成员的写一样。一个进程,怎么能同时向两个磁盘发送命令呢,这不符合现代CPU的运行方式。进程一定是先向一块盘中发送读512K的命令,再向另一块盘发送读命令。正是这一前一后发送两条命令,可能会让图2的方式,比图1稍慢一点点。
慢这一点点是多久,也就是进程多发送了一条从磁盘读数据的命令。 一条命令,多几百个CPU周期,实在是很短的时间。 在CPU不是问题的情况下,这“一点点”基本是可以忽略的。 但要注意,图2的方式,对于读1M连续数据这样的操作,比图1要多浪费点CPU。 刚才说的是读,还有写呢?如果表的区大小是1M,如果是使用append操作,连续写1M数据呢? 如果是写,图1、图2中的DG,性能相同。 因为使用DTrace脚本,打开IO的驱动层探针,大的写IO就是256K。即使区大小是1M,进程也是以256K为单位写。这个写,在图1、图2的方式中,都不会跨越磁盘,因此不会有性能差异。 再来说一种情况,如果不是大批量连续写呢。如果是哪种大量的插入,比如日志型应用,这个情况,今天暂不展开讨论。大概说一下,ASSM的插入,通常只会向一个区中插入。对于图1这种大条带,一个区只在一块盘上。所以脏块集中一块盘上。对于图2的小条带,一个区要跨两个盘,脏块在两块盘上,写也更分散,磁盘的热点也更均匀。但实际上这种情况不便涉及ASSM原理,还要考虑buffer_cache的影响,不单只是IO的问题了。 好,再看一张图吧: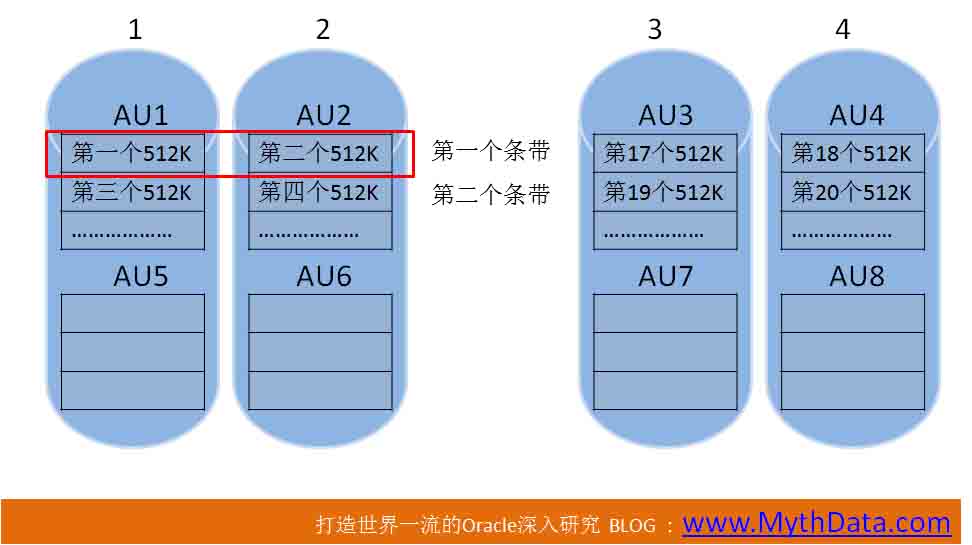 图3
图3
图3中的例子,主要说明一点,条带宽度可以不等于DG中的磁盘数吗?
当然可以。假设为AU大小为4M,条带大小为512K,条带宽度为2。表数据的个512K,在AU1中,第二个在AU2中,第三个又回到AU1中,因为条带宽度为2吗。直到第15、16个512K,分别在AU1中,AU2中,AU1、AU2被占满了。第17个512K,在AU3中,第18个512K,在AU4中,等等,以此类推。 我们后面,会有一个类似的例子。 好了,不同的条带大小、宽度和AU大小,对性能还是多多少少会有些影响的,11GR2的ASM,可以允许我们对这些东西进行控制,是不是动心了,但如何控制,方法还是有点奇怪的。并不是改了隐藏参数就能发挥作用。 还有一点注意事项,在ASM中,AU,是属于磁盘组层面的概念,一个磁盘组,只能有一个统一的AU大小。在创建磁盘组时,要指定AU的大小,一旦指定,在磁盘组创建后无法变更。 而条带,是属于文件层面的概念。同一磁盘组中,各个文件可以有不同的条带大小。在创建表空间时,要同时确定条带信息。也是一旦确定,无法更改。 好了,下面,让我们开始吧。 第 二 部分 不可调粗粒度条带 我们前面说过,我把ASM条带总体上分两种:不可调粗粒度、可调细粒度。 不可调粗粒度其实是我们使用多的一个方式,因为ASM默认的方式就是它。 在这种方式下,条带大小、宽度是不可调的,而且条带大小,就是AU的大小。宽度一直为1。 为了验证我的说法,可以如下测试: 一、环境准备: 10G中,数据文件默认的条带大小是1M,11G中_asm_stripesize参数默认值并不是1M,我们先修改一下这个值,将它设为1M: SQL> alter system set "_asm_stripesize"=1048576; System altered. _asm_stripewidth的值,保留默认值为8。 为了和条带大小有所区别,创建个AU大小为4M的DG: create diskgroup dg2 external redundancy disk '/dev/rdsk/c1t3d0s0', '/dev/rdsk/c1t4d0s0', '/dev/rdsk/c1t5d0s0', '/dev/rdsk/c1t6d0s0' attribute 'compatible.asm' = '11.2','AU_SIZE'='4M'; 注意事项,AU_SIZE是4M,不写4m,小写会报错。 创建区大小为4M的表空间: create tablespace tbs_e4m datafile '+dg2/tbs_e4m_01.dbf' size 100m uniform size 4m; 二、观察kfffdb结构中的条带数据。 注意,前面已经提到过,在ASM中,AU,是属于磁盘组层面的概念,一个磁盘组,只能有一个统一的AU大小。条带,是属于文件层面的概念。 下面,我们可以观察一下刚刚+dg2/tbs_e4m_01.dbf 步1:首先确认ASM中的文件号 col NAME for a40 SQL> select NAME,FILE_NUMBER from V$ASM_ALIAS where name like '%tbs_e4m_01.dbf%'; NAME FILE_NUMBER ---------------------------------------- ----------- tbs_e4m_01.dbf 256 在ASM中,此文件的编号是256。 再次查询X$KFFXP,确认1号文件位置: SQL> select GROUP_KFFXP, DISK_KFFXP ,AU_KFFXP from X$KFFXP where NUMBER_KFFXP=1 and GROUP_KFFXP=2; GROUP_KFFXP DISK_KFFXP AU_KFFXP ----------- ---------- ---------- 2 0 48 为什么要查1号文件,还有X$KFFXP视图的详细说明,参见ASM的文件管理深入解析(内含开源的ASM文件挖掘研究版程序) http://www.itpub.net/thread-1597605-1-1.html 。 1号文件在0号盘48号AU上。下面,确定0号盘是谁: SQL> select DISK_NUMBER,path from v$asm_disk where GROUP_NUMBER=2; DISK_NUMBER PATH ----------- ------------------------------ 0 /dev/rdsk/c1t3d0s0 1 /dev/rdsk/c1t4d0s0 2 /dev/rdsk/c1t5d0s0 3 /dev/rdsk/c1t6d0s0 0号盘是/dev/rdsk/c1t3d0s0,使用kfed读取它的48号AU的256号块: -bash-3.2$ kfed read /dev/rdsk/c1t3d0s0 AUSZ=4194304 BLKSZ=4096 aun=48 blkn=256|more ……………… kfffdb.strpwdth: 1 ; 0x04c: 0x01 kfffdb.strpsz: 22 ; 0x04d: 0x16 ……………… 上面这两个,就是256号ASM文件的条带宽度和条带大小。但是很遗憾,我们无法获知这两个值的意义。 但是,虽然无法知道这里的条带宽度为1、大小为22具体的意义。但在后面,我们可以通过改变_asm_stripesize、_asm_stripewidth,比较这两个值的变化,来分析_asm_stripesize、_asm_stripewidth这两个参数的意义。 暂时记着这两个值,后面会有点用。 三、观察IO的脚本 真正要搞清楚ASM的IO,还是要靠DTrace,可以使用如下脚本: # cat dfio.d #!/usr/sbin/dtrace -s char *rd; char bn[4]; int file_id; int block_id; BEGIN { i=0; } io:::start / args[2]->fi_pathname=="[url=]/devices/pci@0,0/pci15ad,1976@10/sd@3,0:a,raw[/url]"|| args[2]->fi_pathname=="[url=]/devices/pci@0,0/pci15ad,1976@10/sd@4,0:a,raw[/url]"|| args[2]->fi_pathname=="[url=]/devices/pci@0,0/pci15ad,1976@10/sd@5,0:a,raw[/url]"|| args[2]->fi_pathname=="[url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url]" / { rd=copyin((uintptr_t )(args[0]->b_addr),16); bn[0]=rd[4]; bn[1]=rd[5]; bn[2]=rd[6]; bn[3]=rd[7]; file_id=(*((int *)&bn[0])) >> 22; block_id=(*((int *)&bn[0])) & 0x003fffff; printf("IO number:%d %s %s %d %s pid=%d file_id:%d,block_id:%d",i,args[1]->dev_statname,args[2]->fi_pathname,args[0]->b_bcount/1024,args[0]->b_flags&B_READ?"R" :"W",pid,file_id,block_id); i++; } 这块脚本意义说来话长,还是要参看“揭密Oracle之七种武器二:DTrace语法:跟踪物理IO http://www.itpub.net/thread-1609235-1-1.html ”。 和“揭密Oracle之七种武器二”之中的区别是,这个脚本是针对数据文件,不是针对日志。为了多输出信息,我读取了每次IO的4至7字节。Oracle的数据块,4-7字节是RDBA,然后我从RDBA中解析出文件号和块号。这样,我们可以知道每次IO是访问的哪个文件几号块。 四、观察IO 先创建个测试表: drop table iotest1; create table iotest1 (id int,name varchar2(30)) tablespace tbs_e4m; 运行下面的命令,观察IO: ./dfio.d 向测试表中以直接路径方式写入数据: insert /*+append*/ into iotest1 select rownum,'AAAAAA' from lhb.a2_70m; commit; 然后,./dfio.d脚本会跟踪到很多IO信息,下面是跟踪结果: number:0 sd4 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@3,0:a,raw[/url] 8 W pid=1172 file_id:5,block_id:1033 次IO是写1033号块,目的是什么不太清楚。这个块只是一个普通的数据块。 下面,从第2号IO开始,连续对[url=]/devices/pci@0,0/pci15ad,1976@10/sd@6[/url]这个设备写了16次。这个设备其实是/dev/rdsk/c1t6d0s0,2号磁盘组的第4块盘。 number:1 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 176 W pid=1371 file_id:5,block_id:522 number:2 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:544 number:3 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:576 number:4 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:608 number:5 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:640 number:6 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:672 number:7 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:704 number:8 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:736 number:9 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:768 number:10 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:800 number:11 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:832 number:12 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:864 number:13 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:896 number:14 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:928 number:15 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:960 number:16 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:992 第17次IO从992号块开始读,读了256K,也就是32个块。也就是992号块到1023号块。到此为止,IOTEST表的个区正好被读完。下面是IOTEST1的区信息: SQL> select extent_id, file_id, block_id ,blocks from dba_extents where segment_name='IOTEST1'; EXTENT_ID FILE_ID BLOCK_ID BLOCKS ---------- ---------- ---------- ---------- 0 5 512 512 1 5 1024 512 2 5 1536 512 3 5 2048 512 4 5 2560 512 5 5 3072 512 6 5 3584 512 7 5 4096 512 8 5 4608 512 9 5 5120 512 10 5 5632 512 11 5 6144 512 12 5 6656 512 13 5 7168 512 14 5 7680 512 编号为0的区,从512号块开始,到1023号块止,共4M。AU大小也是4M,这应该也是256号文件的个AU。 下面,从第18次IO开始,开始写另外一个设备:[url=]/devices/pci@0,0/pci15ad,1976@10/sd@3,0:a[/url],也就是/dev/rdsk/c1t3d0s0,DG2的0号盘: number:17 sd4 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@3,0:a,raw[/url] 192 W pid=1371 file_id:5,block_id:1032 number:18 sd4 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@3,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:1056 number:19 sd4 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@3,0:a,raw[/url] 256 W pid=1371 file_id:5,block_id:1088 从上面的结果来看,Oracle要写满一个4M的AU,才会再写另一个设备中的下一个AU。 我的条带大小是1M,看到没,1M的条带大小,并没有启到什么限制作用。在“揭密Oracle之七种武器二”中,我对10G的ASM观察,如果AU是1M,条带是128K,Oracle在个AU中写128K,然后换到下一个AU中再写下一个128K。 下面,继续探索,有没有可能,这4M的AU中,数据是不连贯的。比如,以1M为单位。或者,以256K为单位。因为DTrace跟踪结果,每次写IO,大小基本都是256K。我是如下验证的: 步1:获得256号ASM文件的AU分布: SQL> select GROUP_KFFXP, DISK_KFFXP ,AU_KFFXP from X$KFFXP where NUMBER_KFFXP=256 and GROUP_KFFXP=2; GROUP_KFFXP DISK_KFFXP AU_KFFXP ----------- ---------- ---------- 2 1 5 2 3 7 2 0 7 ………………………… 个AU是1号盘5号AU,第二个AU是3号盘7号AU,等等。这里,个AU中是文件头,位图块和一些空块。从第二个AU开始,才是段数据。这一点,从上面我们显示的IOTEST1的区信息就可以确定: EXTENT_ID FILE_ID BLOCK_ID BLOCKS ---------- ---------- ---------- ---------- 0 5 512 512 1 5 1024 512 2 5 1536 512 …………………… IOTEST1的个区,从512号块开始。也就是文件的个AU被跳过去了。 下面,已经确定表段数据从第二个AU开始,继续确认一下第二个AU中,表数据是以什么单位存放的,是条带大小的1M,还是IO大小的256K。 步2:确定第二个AU中数据是否连续: 确认这个有点困难,但一定要去确认一下。如果1M的条带大小发挥了作用,哪么,AU中个1M和第二个1M中的数据,是不连贯的。 文件的第二个AU是3号盘7号AU,这个盘是/dev/rdsk/c1t6d0s0,也就是我们的脚本跟踪出的2至17次IO的目标设备。 我用如下命令观察表数据: dd if=/dev/rdsk/c1t6d0s0 bs=8192 skip=3584 count=1|od -x|more 我们要跳过前7个AU,每个AU是4M,所以,7*1024*4/8,等于3584。结果如下: -bash-3.2$ dd if=/dev/rdsk/c1t6d0s0 bs=8192 skip=3584 count=1|od -x|more 0000000 a220 0000 0200 0140 47eb 0006 0000 0404 0000020 f71c 0000 0000 0000 0000 0000 0000 0000 …………………… 注意,“0200 0140”,这是块的RDBA。因为大小端的原帮,要前后颠倒一下,01400200。根据前十个二进制位是文件号,后面是块号的算法,这是5号文件512号块。正是我们要找到iotest1表的个块。 将skip=3584改成skip=3585,就是读取IOTEST1的下一个块了。 我用这种方式,比了一下,结果/dev/rdsk/c1t6d0s0中这个AU是完整连续的4M数据。可以这样说,1M的条带没发挥作用。 实际上我不单查看RDBA,还对比了表中数据,可以百分之百确定,数据不是以1M为单位,而是以4M为单位存放。 五、换个条带大小再测: 删除原来的表空间和数据文件,修改隐藏参数,改变条带大小再测: SQL> alter system set "_asm_stripesize"=524288; System altered. SQL> alter system set "_asm_stripewidth"=4; System altered. 这次分别在ASM实例和数据库实例中做修改,将条带宽度定为4,条带大小改为512K。再重建表空间和表: drop tablespace tbs_e4m INCLUDING CONTENTS AND DATAFILES; create tablespace tbs_e4m datafile '+dg2/tbs_e4m_01.dbf' size 100m uniform size 4m; drop table iotest1; create table iotest1 (id int,name varchar2(30)) tablespace tbs_e4m; 然后启动跟踪脚本,再执行如下的命令: insert /*+append*/ into iotest1 select rownum,'AAAAAA' from lhb.a2_70m; commit; 我就不再粘跟踪结果了,无论是终的跟踪结果、还是dd命令查看的结果,都和前面一样。kfffdb.strpwdth和kfffdb.strpsz也和以前一样。 _asm_stripesize和_asm_stripewidth根本就没发挥作用。搞这样两个参数,不过是个摆设而已。 所以,我把这种条带称为“不可调粗粒度条带”。第 二 部分 可调细粒度条带
一、传统的细粒度条带测试结果: 10G开始,有两种条带,细粒度128K,粗粒度1M。下面,用10G中传统的方式再设置一次,比较一下。 创建一个细粒度条带的模版(在ASM实例中运行): SQL> alter diskgroup dg2 ADD TEMPLATE stp_fine ATTRIBUTES (UNPROTECTED fine); Diskgroup altered. 创建使用此模版的表空间: SQL> create tablespace tbs_e4m4 datafile '+dg2(stp_fine)/tbs_e4m4_01.dbf' size 100m reuse uniform size 4m; Tablespace created. 创建测试表: SQL> create table iotest2 (id int,name varchar2(30)) tablespace tbs_e4m4; Table created. 开启跟踪脚本,插入: SQL> insert /*+append*/ into iotest2 select rownum,'AAAAAA' from lhb.a2_70m; 3087162 rows created. SQL> commit; Commit complete. 查看跟踪结果: number:0 sd5 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@4,0:a,raw[/url] 176 W pid=1173 file_id:6,block_id:74 number:1 sd5 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@4,0:a,raw[/url] 256 W pid=1173 file_id:6,block_id:96 number:2 sd6 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@5,0:a,raw[/url] 256 W pid=1173 file_id:6,block_id:128 number:3 sd6 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@5,0:a,raw[/url] 256 W pid=1173 file_id:6,block_id:160 number:4 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1173 file_id:6,block_id:192 number:5 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1173 file_id:6,block_id:224 number:6 sd4 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@3,0:a,raw[/url] 256 W pid=1173 file_id:6,block_id:256 number:7 sd4 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@3,0:a,raw[/url] 256 W pid=1173 file_id:6,block_id:288 number:8 sd5 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@4,0:a,raw[/url] 256 W pid=1173 file_id:6,block_id:320 number:9 sd5 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@4,0:a,raw[/url] 256 W pid=1173 file_id:6,block_id:352 根据结果很容易发现,每个盘Oracle写512K。 下面,看一下每个盘中连续的数据,根据这个,确认一下条带的大小。 我不再详细描述此过程了,查询select GROUP_KFFXP, DISK_KFFXP ,AU_KFFXP from X$KFFXP where NUMBER_KFFXP=257 and GROUP_KFFXP=2; ,找到257号文件的第2个AU所在磁盘。使用dd if=/dev/rdsk/c1t4d0s0 bs=8192 skip=5184|od -tx|more,观察结果,每个AU Oracle的确使用了512K,就开始使用下一AU。 也就是说,细粒度条带下,条带大小不再是等同AU大小,而是512K。 查看257号文件kfffdb结构: bash-3.2$ kfed read /dev/rdsk/c1t3d0s0 AUSZ=4194304 BLKSZ=4096 aun=48 blkn=257|more ………………………… kfffdb.strpwdth: 4 ; 0x04c: 0x04 kfffdb.strpsz: 19 ; 0x04d: 0x13 ………………………… kfffdb.strpwdth、kfffdb.strpsz和以前果然不一样了。kfffdb.strpwdth不再是以前的1,而是4。kfffdb.strpsz变为了19。 但有一点很不巧,我之前曾把_asm_stripesize调为512K,是否这个参数终于发获了作用? 我不再详细列出测试步骤,在ASM实例和数据库实例分别修改参数,我是将宽度修改为2,将大小改为256K。删除表空间再重建,条带大小、IO大小依旧。 正在我将要宣判这两个参数是无意义的参数时。转机出现了。但只要不放弃,转机一定会出现。 二、如何让_asm_stripesize、_asm_stripewidth发挥作用: 这两个参数还是有很大作用的,并不只是个摆设。要不然,全球哪么多尖子DBA,又是和IO相关这么重要的问题,总会有人发现这两个摆设。到哪时,Oracle的脸往哪儿搁。 如下步骤调整参数,才会有意义: 步1:删除表空间,调整参数,再建表空间: SQL> drop tablespace tbs_e4m4 INCLUDING CONTENTS AND DATAFILES; Tablespace dropped. SQL> alter system set "_asm_stripewidth"=2; System altered. SQL> alter system set "_asm_stripesize"=262144; System altered. 注意,调整参数,在ASM实例和数据库实例都做。条带宽度调为2,条带大小为256K。 步2:在调整参数后,在ASM实例中再添加一个模版: SQL> alter diskgroup dg2 ADD TEMPLATE stp_fine2 ATTRIBUTES (UNPROTECTED fine); Diskgroup altered. 这一步是关键,在修改参数后,我们要明确创建新的模版。这样,我们修改的参数,才会有意义。 步3:在数据库实例中创建使用这个模版的表空间: SQL> create tablespace tbs_e4m4 datafile '+dg2(stp_fine2)/tbs_e4m4_01.dbf' size 100m reuse uniform size 4m; Tablespace created. 在ASM中,删除文件马上再建,文件号不变,tbs_e4m4_01.dbf还是257号文件,可以马上确认一下kfffdb结构中的条带信息: bash-3.2$ kfed read /dev/rdsk/c1t3d0s0 AUSZ=4194304 BLKSZ=4096 aun=48 blkn=257|more ………………………… kfffdb.strpwdth: 2 ; 0x04c: 0x02 kfffdb.strpsz: 18 ; 0x04d: 0x12 ………………………… 的确已经变了。宽度已经变为了2。大小变为了18。目前还不知道18和我们的条带大小256K之间具体的联系。 下面,进一步用dfio.d脚本观察IO: 在数据库实例中完成一个插入: SQL> create table iotest2 (id int,name varchar2(30)) tablespace tbs_e4m4; Table created. SQL> insert /*+append*/ into iotest2 select rownum,'AAAAAA' from lhb.a2_70m; 3087162 rows created. SQL> commit; Commit complete. 用dfio.d观察: bash-3.2# ./dfio.d dtrace: script './dfio.d' matched 7 probes 下面是观察结果: number:0 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 176 W pid=1194 file_id:6,block_id:42 number:1 sd5 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@4,0:a,raw[/url] 256 W pid=1194 file_id:6,block_id:64 number:2 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1194 file_id:6,block_id:96 number:3 sd5 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@4,0:a,raw[/url] 256 W pid=1194 file_id:6,block_id:128 ……………………………… ……………………………… ……………………………… number:29 sd5 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@4,0:a,raw[/url] 256 W pid=1194 file_id:6,block_id:960 number:30 sd7 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@6,0:a,raw[/url] 256 W pid=1194 file_id:6,block_id:992 ……………………………… ……………………………… ……………………………… number:31 sd6 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@5,0:a,raw[/url] 256 W pid=1194 file_id:6,block_id:1024 number:32 sd4 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@3,0:a,raw[/url] 192 W pid=1194 file_id:6,block_id:1064 number:33 sd6 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@5,0:a,raw[/url] 256 W pid=1194 file_id:6,block_id:1088 number:34 sd4 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@3,0:a,raw[/url] 256 W pid=1194 file_id:6,block_id:1120 ……………………………… DG2磁盘组中,共有4块盘,因为我的条带宽度是2,条带大小是256K。Oracle 0至30次IO,交替写[url=]/devices/pci@0,0/pci15ad,1976@10/sd@6[/url]、[url=]/devices/pci@0,0/pci15ad,1976@10/sd@4[/url]这两个设备。也就是/dev/rdsk/c1t6d0s0、/dev/rdsk/c1t4d0s0这两个盘,每次写256K。写了31次,也就是8M了。 接下来的32次IO,是交替写另外两块磁盘:/dev/rdsk/c1t5d0s0、/dev/rdsk/c1t3d0s0,每个盘各写16次。也就是每个盘各写满一个AU。 注意,我们不能放过每一个细节。/dev/rdsk/c1t6d0s0、/dev/rdsk/c1t4d0s0这两个盘,交替写了31次,8M差256K。 对比IOTEST2的区信息: SQL> select extent_id, file_id, block_id ,blocks from dba_extents where segment_name='IOTEST2'; EXTENT_ID FILE_ID BLOCK_ID BLOCKS ---------- ---------- ---------- ---------- 0 6 32 512 1 6 544 512 2 6 1056 512 3 6 1568 512 4 6 2080 512 5 6 2592 512 6 6 3104 512 7 6 3616 512 8 6 4128 512 9 6 4640 512 10 6 5152 512 11 6 5664 512 12 6 6176 512 13 6 6688 512 14 6 7200 512 15 rows selected. 前两个区是32号块到543号块,544号块到1055号块。再对比我们观察到的IO情况: number:31 sd6 [url=]/devices/pci@0,0/pci15ad,1976@10/sd@5,0:a,raw[/url] 256 W pid=1194 file_id:6,block_id:1024 0至30次IO写的是另外两个设备:[url=]/devices/pci@0,0/pci15ad,1976@10/sd@6[/url]、[url=]/devices/pci@0,0/pci15ad,1976@10/sd@4[/url]。31次IO写的是[url=]/devices/pci@0,0/pci15ad,1976@10/sd@5[/url]。文件号是6,块号是1024,到1056号块开始,才是第三个区。这意味着什么,第二个区横跨了4块盘中的三个盘。原因是区大小为4M,但257号文件的个AU前面的块,是文件头。在原来条带宽度为1、大小为4M的情况下,个AU中块条带(其实就是整个个AU)被做为文件头。当然,文件头用不了4M,其他空间由于不满4M,被废弃不用。现在条带大小是256K,个AU中块条带同样被占用做文件头。由于有4M的AU中被占了256K,4M的区无法完全放的下,到另一个盘中再占256K的情况也就出现了。所以,偶而有一个区会横跨3个盘(两块盘是条带,一块盘是放多出的256K)。 三、总结 我做过测试,修改条带参数,以这样的方式创建模版: alter diskgroup dg2 ADD TEMPLATE stp_c1 ATTRIBUTES (UNPROTECTED coarse); 哪么,参数是不会发挥作用的。 总结一下ASM的条带设置: 1、UNPROTECTED coarse 粗粒度条带下,条带宽度、条带大小不可改变。条带宽度将一直是1,条带大不等同于AU大小。这就是我所说的“不可调粗粒度条带”。 2、UNPROTECTED fine 细粒度条带下,条带宽度、条带大小可使用_asm_stripesize、_asm_stripewidth两个隐藏参数调节。这就是“可调细粒度条带”。 Oracle对_asm_stripesize参数的大值有要求,大不能超过1M。因此,使用UNPROTECTED fine方式,条带大只能是1M。 而UNPROTECTED coarse下,条带大小随AU而定,条带大小可以很大。 还有两个疑问,一是我的DTrace脚本,都是观察的写IO,观察到的读IO,大的IO大小,根据条带大小而定。 对于不可调粗粒度条带,AU大小为4M,将表的区也定为4M,大的IO,不会超过1M。 对于可调细粒度条带,条带大小为512K时,大IO是512K。条带大小是256K,大的IO是256K。 这些也都是可以观察到的。但是读IO会同时观察到很多很小的64K为单位的IO,且RDBA并非正常的数据块。这些IO是干码的,还没有进一步研究。 另外一个疑问,全表扫描的读IO,大会是1M,但写IO,大只是256K,还没进一步研究是否有方法提高这个值。