Overview
本文将 Spark 作业称为 Spark Application 或者简称为 Spark App 或者 App。目前我们组内的计算平台的 Spark 作业,是通过 Spark Operator 提交给 Kubernetes 集群的,这与 Spark 原生的直接通过 spark-submit 提交 Spark App 的方式不同,所以理解 Spark Operator 中提交 Spark App 的逻辑,对于用户来说是非常有必要的。本文将就其具体的提交逻辑,介绍一下。
Spark Operator 中的 spark-submit 命令
熟悉 Spark 的同学未必对 Kubernetes 和 Operator 熟悉,所以看 Spark Operator 的逻辑的时候有可能会遇到一些问题,我的建议是先从提交 spark-submit 命令相关的逻辑开始看就会很容易理解。Spark Operator 的提交作业的逻辑主要在 pkg/controller/sparkapplication/submission.go。
func runSparkSubmit(submission *submission) (bool, error) {
sparkHome, present := os.LookupEnv(sparkHomeEnvVar)
if !present {
glog.Error("SPARK_HOME is not specified")
}
// 这个就是 Spark 用户熟悉的 spark-submit 命令
var command = filepath.Join(sparkHome, "/bin/spark-submit")
cmd := execCommand(command, submission.args...)
glog.V(2).Infof("spark-submit arguments: %v", cmd.Args)
output, err := cmd.Output()
glog.V(3).Infof("spark-submit output: %s", string(output))
if err != nil {
var errorMsg string
if exitErr, ok := err.(*exec.ExitError); ok {
errorMsg = string(exitErr.Stderr)
}
// The driver pod of the application already exists.
if strings.Contains(errorMsg, podAlreadyExistsErrorCode) {
glog.Warningf("trying to resubmit an already submitted SparkApplication %s/%s", submission.namespace, submission.name)
return false, nil
}
if errorMsg != "" {
return false, fmt.Errorf("failed to run spark-submit for SparkApplication %s/%s: %s", submission.namespace, submission.name, errorMsg)
}
return false, fmt.Errorf("failed to run spark-submit for SparkApplication %s/%s: %v", submission.namespace, submission.name, err)
}
return true, nil
}
controller 里有个 submitSparkApplication() 这个方法是用来提交 Spark Application 的。NewState 的情况就是 Controller 发现有处于这个状态下的 Spark Application ,然后就会调用这个方法。
case v1beta2.NewState:
c.recordSparkApplicationEvent(appToUpdate)
if err := c.validateSparkApplication(appToUpdate); err != nil {
appToUpdate.Status.AppState.State = v1beta2.FailedState
appToUpdate.Status.AppState.ErrorMessage = err.Error()
} else {
appToUpdate = c.submitSparkApplication(appToUpdate)
}因为将代码放在 markdown 里做注释不是特别的明显,所以这里截个图可以看看。之前的文章有提到过,在 Spark Operator 里提交 Spark 任务,spark-submit 的过程是很难 Debug 的,原因就在于下面的截图代码里,这里的 output 是执行 spark-submit 之后的输出,而这个输出是在 Spark Operator 的 Pod 里执行的,但是这部分的日志由于只能输出一次,所以用户不能像原生的 spark-submit 的方式,可以看到提交任务的日志,所以一旦是 spark-submit 过程中的问题,在 Spark Operator 中就难以体现了。
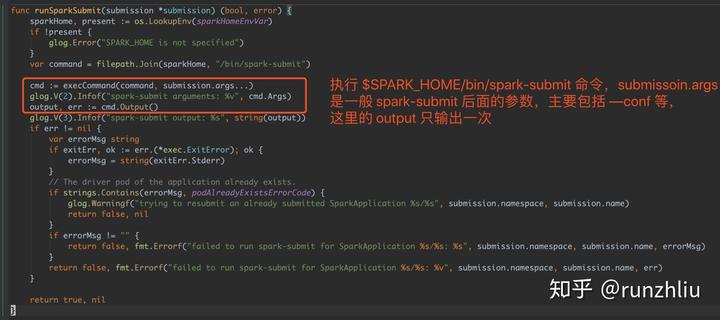
下面是 Spark Operator 日志里,这个 output 输出的内容,这里的输出是曾经在通过 spark-submit 提交过 Spark 任务在 Kubernetes 的用户熟悉的提交日志,不过可以看到光凭一次 output 的内容,是无法理解提交任务哪里出了问题的。

Spark Operator 文档中说明了,默认是以 Spark 新的 Release 版本作为 base 镜像的,所以如果需要修改 Spark 源码,那就必须在编译 Spark Operator 的镜像的是,同时将 SPARK_ARGS 修改成用户新更改的 Spark 源码。这里必须注意到,一般上来说,base 镜像只会影响 spark-submit 的过程,如果用户修改的代码逻辑不影响 spark-submit,那么就没有必要重新编译 Spark Operator 的镜像,因为 Driver 是通过 spark-submit 传递的参数 spark.kubernetes.container.image 或者 spark.kubernetes.driver.container.image 的镜像里的 jar 包依赖影响,而 Executor 的依赖同样是来源于 spark-submit 传递的参数 spark.kubernetes.container.image 或者 spark.kubernetes.executor.container.image 里的 jars 影响,因此用户一定要注意这样的依赖关系,通过下面的图,可以更清晰的理解其中的逻辑。

Summary
本文主要介绍了 Spark Operator 中提交 Spark 作业的代码逻辑,也介绍了在 Spark Operator 中检查提交作业逻辑的问题,由于 Operator 依赖于 Spark 镜像,因此,如果用户对作业提交的过程有其他定制化的需求,就需要重新 build Spark Operator 的镜像了。
