这一次进行SQL语句的常用总结。SAS中的proc sql步骤与传统意义上的SQL语句还是有些不一样的地方,当然大体的思路是没有太大出入的。由于工具依然是SAS BASE所以在这里依然总结的是SAS中的proc sql步骤。proc sql步骤主要用于查询。
一,基本的查询步骤---常见的select子句
select 语句中的字句顺序:
select 你需要的变量字段名(必要)
from 来自哪一张表(必要)
where 对变量的观测进行筛选(如年龄》=25)(选择)
group by 按照什么变量分组(如按照性别分组)(选择)
having 分组之后只能用haveing对变量的观测进行筛选(选择)
order by 按照什么顺序(如年龄大小)(选择)这一次进行SQL语句的常用总结。SAS中的proc sql步骤与传统意义上的SQL语句还是有些不一样的地方,当然大体的思路是没有太大出入的。由于工具依然是SAS BASE所以在这里依然总结的是SAS中的proc sql步骤。
1.select+from子句
原数据集:SASHELP.CLASS(SAS自带数据集)

代码输入:

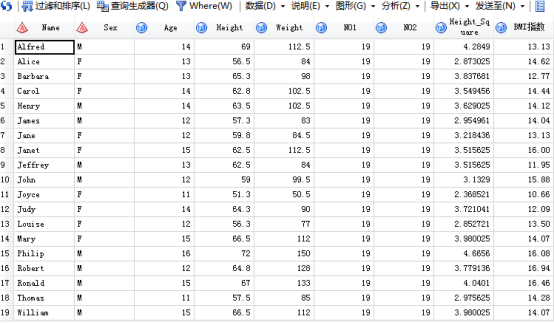
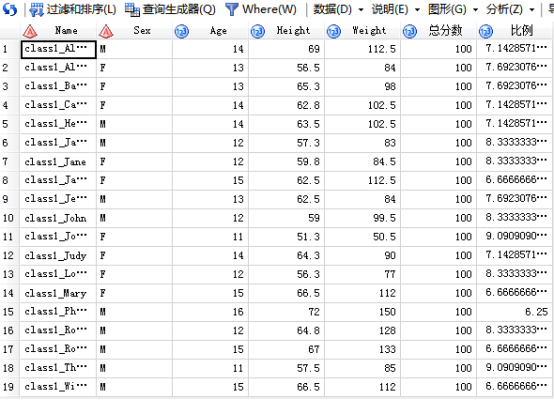
/*整句话的意思是,from从SASHELP.CLASS表中查询输出select这几个变量:*代表所有原数据集变量,后面的都是新增列(as后面是新增列的字段名)No1、NO2、Height_Square和BMI,输出到表CLASS中去。distinct 表示删除重复的观测。COUNT(*) as no1 用了一个count函数告诉我们一共有多少观测输出到新的字段no1(还有其他很多函数常用的有sum(),max(),min(),avg()返回非空值的平均值等等);加工的第二个变量NO2是指name非缺失的个数;加工的第三个变量Height_Square;加工的第四个变量是BMI,这个变量用的不是原数据中的变量,所以要括号括起来然后告诉SAS它用的是上面加工出来的个变量所以必须用CALCULATED作为要用的变量的前缀。后面的label 和 format是将对加工生成的变量的列属性进行定义,label标签,format输出格式,length字段长度等等。*/
SAS输出:
2.where子句
代码输入:
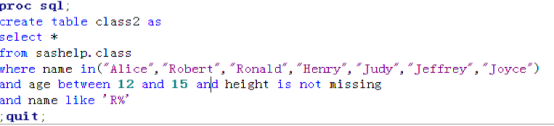
- 比较算符:
算符 等价 定义
= EQ 相等
^= 、~=、<> NE 不等于
> GT 大于
< LT 小于
>= GE 大于等于
<= LE 小于等于
- 条件运算符号:
between and 筛选指定字段在一定区域
contains 检查数据是否包含某个字符串
in 检查数据在自定义列表中
is missing 检查数据是否缺失
like 检查数据是否满足一种样式
SAS输出:

3.group by子句
代码输入:/*按照性别分组*/
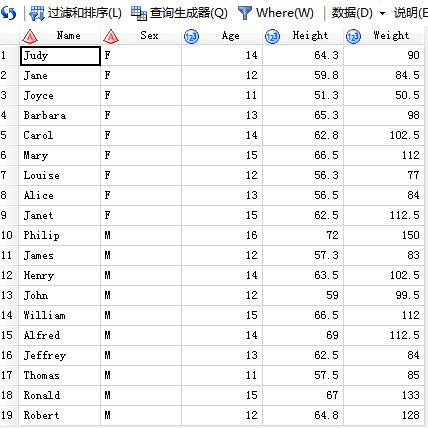
4.having 子句
/*和where功能相似,的不同是它可以对分组后的数据进行筛选所以必须放在group by 的后面*/
5.order by 子句
order by 子句,进行排序,缺失值默认小于非缺失值/直接对计算的新列排序/可以对没有被选择的列排序
代码输入:
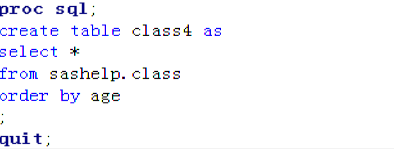
SAS输出:
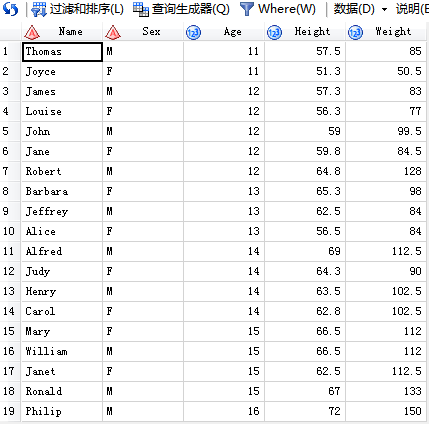
6.常用的分组汇总
/*摘出男生的平均身高,女生的平均体重*/
代码输入:

SAS输出:
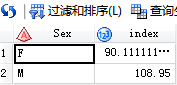
二,连接查询步骤
以上是对一张表的查询,接下来看两张表或者多张表的查询。这里需要说明一下,有时候在SAS中sql和DATA步骤处理数据的时候各有千秋,根据不同的需求同时灵活应用两者才是使得代码更优化,效率更高的捷径。
/*数据集准备,*/
data height(keep=name sex age height)
weight(keep=name sex age weight);
set sashelp.class;
run;
data height;
set height;
if name="威廉" then delete;
run;
data weight;
set weight;
if name="爱丽丝" then delete;
run;
输入的数据集:
个:
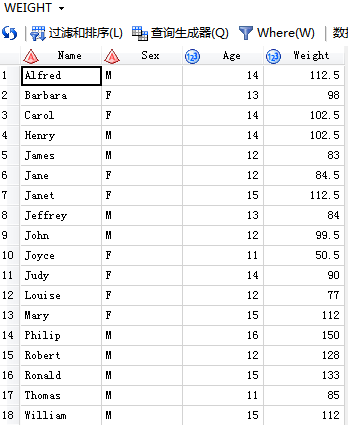
第二个:
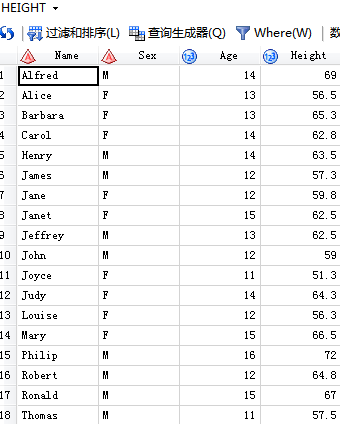
/*1,内部连接:inner join只保留同时在两张表中的数据*/
代码输入:

SAS输出:
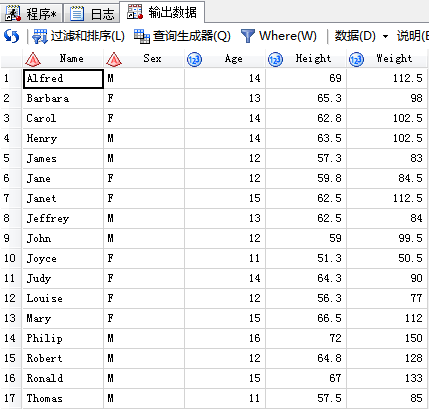
/*在这里需要注意的是缺失值对于关联是有影响的,所以在关联的时候不仅需要考虑是一对多多对一多对多还是一对一,并且要考虑关联的字段中是否缺失如果缺失要去掉缺失值。*/
/*2,左连接:left join保留from后的那张表的所有观测,以及关联上去的后面一张表的值*/
代码输入:

SAS输出:
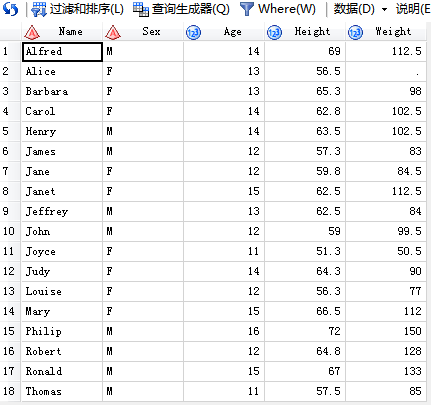
/*3,右连接:right join保留join后的那张表的所有观测,以及关联上去的from后的那一张表的值*/
代码输入:

SAS输出:
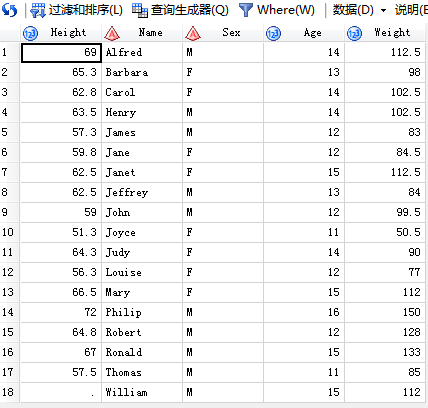
/*4,完全外连接:保留两张表的所有观测*/
代码输入:

/*join与merge的区别结果在于多对多的情况。当关联键在A表中有重复在B表中也有重复的时候称为多对多关联。这时候merge关联出
来的结果是直接把B表横向拼接到A表,按照观测顺序拼接。而join结果是笛卡尔乘积,也就是说假如A表中有三个一样的ID,B表中
有两个一样的ID那么终的结果是6条这样的ID。*/
SAS输出:
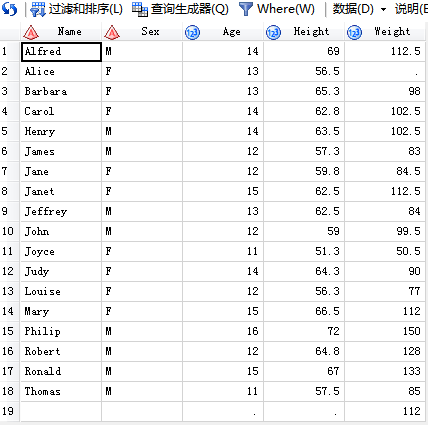
三,子查询步骤
以上from的表都是已有的表,那么在查询过程中可能需要查询来源表示经过一次加工而生成的表,此时就可以用到子查询来完成操作。
/*准备数据*/
data height(keep=name sex height) weight(keep=name sex weight);
set sashelp.class;
run;
输入数据集:
个:
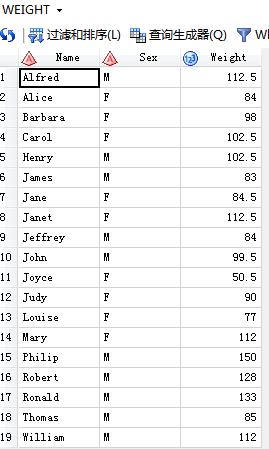
第二个:

/*1.选择体重大于100的同学的身高*/
代码输入:

SAS输出:
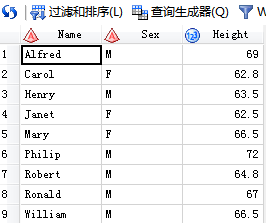
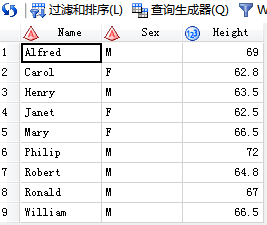
/*2.选择体重大于100的同学的身高*/
代码输入:

SAS输出:
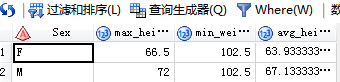
/*3.选择不同性别体重大于100的同学的大小和平均身高*/
/*先合并再分组*/
代码输入:

SAS输出:
四,纵向合并查询步骤
对于两个数据集字段类型一样的数据集进行纵向合并。
/*********************************************合并查询***************************************************/
/*--两个查询的纵向合并,
产生非重复观测 union
产生重复观测 union all
产生属于个查询的观测,第二个查询公共部分会被排除掉 except
产生两个查询中公共部分的观测 intersect
对多个查询结果直接连接 outer union
*/
/*准备数据*/
data boy girl;
set sashelp.class;
if sex="F" or name="Henry" then output girl;
if sex="M" or name="Alice" then output boy;
run;
输入数据集:
个:
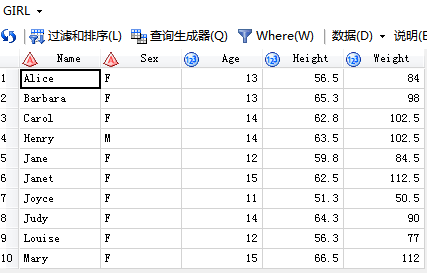
第二个:
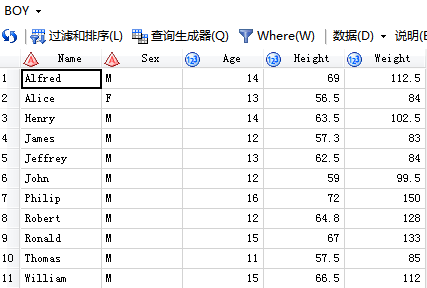
/*1.union重复19条*/
代码输入:

SAS输出:
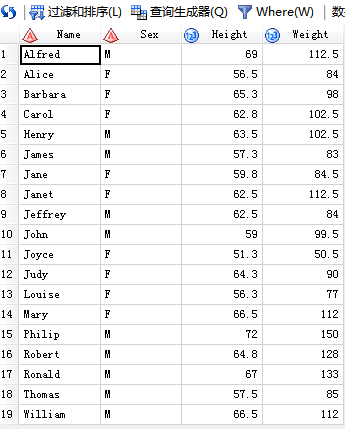
/*2.union all重复21条*/
代码输入:
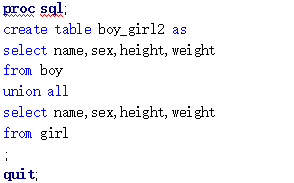
SAS输出:
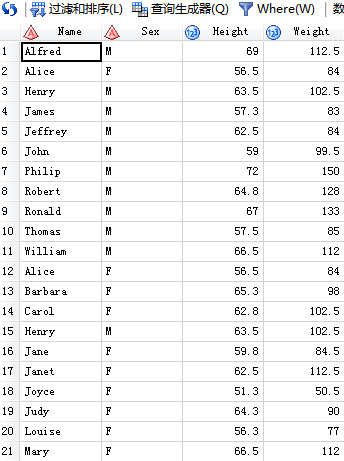
/*3.except除去了公共部分全是 M*/
代码输入:

SAS输出:
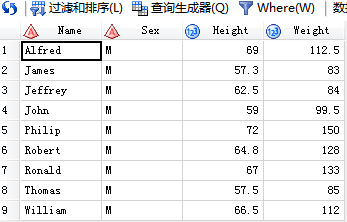
/*4.intersect只留下公共部分*/
代码输入:

SAS输出:
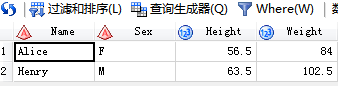
/*5.outer union直接随意连接*/
代码输入:

SAS输出:

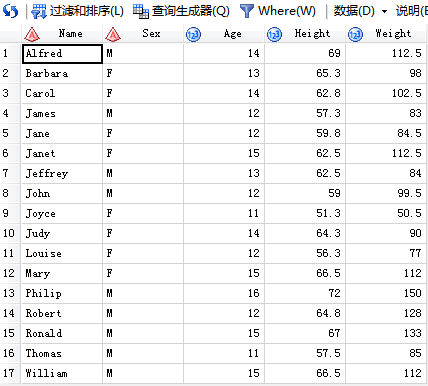
/*6.产生非公共部分*/
代码输入:

SAS输出:
五,查询--创建更新修改表步骤
以下是讲述如何用SQL语句对表进行修改的语句
/****************************************************查询--创建更新修改表**********************************/
/*创建表 create table 任何其他的SAS语句都可以适当得用在SQL中*/
代码输入:

SAS输出:
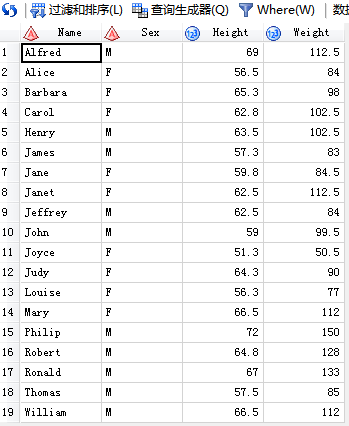
/*1.用insert into--SET子句插入观测*/
代码输入:

SAS输出:
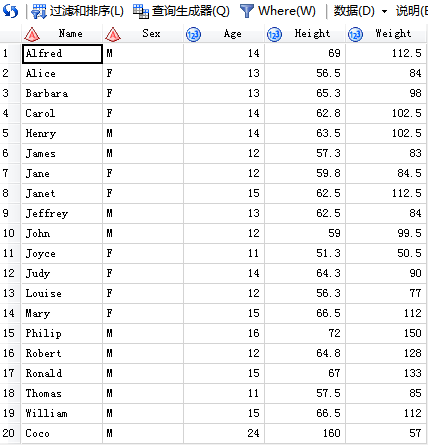
/*2.用DELETE子句删除观测行*/
代码输入:

SAS输出:
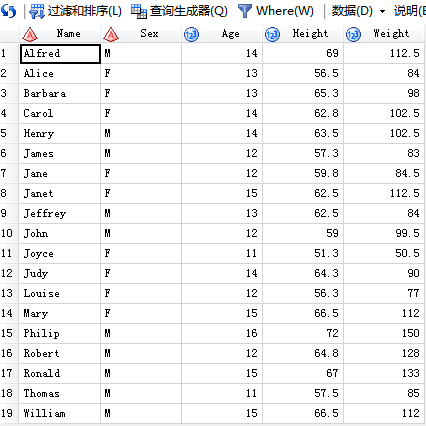
/*3.用alter--add增加列*/
代码输入:

SAS输出:
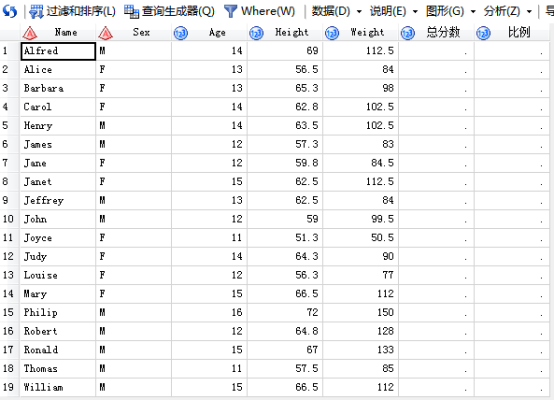
/*4.用update来填值*/
代码输入:

SAS输出:

/*5.用alter--modify修改列属性(但不能rename)--update--修改列值*/
代码输入:

SAS输出:
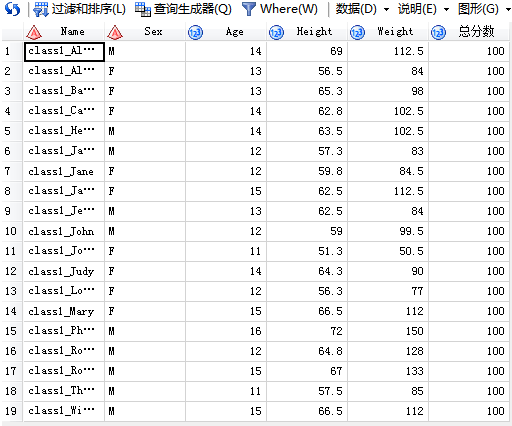
/*6.alter-- drop删除列*/
代码输入:

SAS输出:
SQL基础篇章就到这里了,下一次准备更新,SQL中的如何优化查询以及如何在SQL中使用SAS宏工具。借由此之后下下篇章再引出我的大BOSS--宏的编写!!!
