本文来源:可译网
译者:CY2
原文链接:https://coyee.com/article/12148-partitioning-in-apache-hive
◆◆◆
Hive 是用于大数据集查询的好工具 —— 特别是当数据集需要全表扫描时。但用户经常需要对某个列的值进行过滤,这时候分区就非常有效。分区是一个包含数据块的目录。当我们做分区的时候,会为某个列的值创建一个分区。
让我们来运行一个简单的示例来了解分区特性。创建分区表的语法是:
create table tablename(colname type) partitioned by(colname type);
如果 hive.exec.dynamic.partition.mode 设置为 strict,那么你至少需要一个静态分区。而 non-stric 模式下,所有的分区都是动态的。


如果 hive.exec.dynamic.partition.mode 设置为 strict,那么你至少需要一个静态分区。而 non-stric 模式下,所有的分区都是动态的。
下面是插入 values 的语法:
insert into partition values();
首先我们插入一个 id=1 的记录,然后插入 id=2 的另外一条记录。
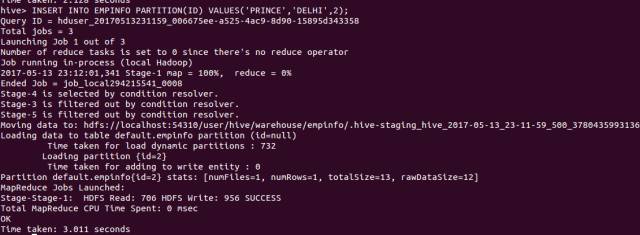
现在,进入 Hadoop 文件系统的 /user/hive/warehouse/default/empinfo 目录。
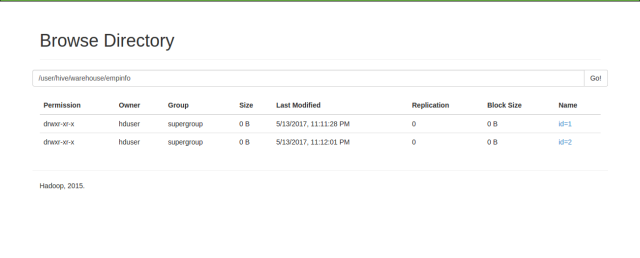
正如我们所看到的,这里有两个分区:一个名是 id=1 ,另外一个 id=2。当我们执行带 where 语句的查询时,就不会进行全表扫描,而只是扫描所需的分区。

如果你尝试对一个未分区的大数据集表,就会花很长时间,因为要进行全表的扫描。
希望这篇文章对你有用。 祝编码快乐!
