本文目录:
为什么要进行数据库优化 MySql数据库优化 SQL及索引优化 MySQL慢查日志分析工具 通过explain查询分析SQL的执行计划 具体慢查询优化的案例
1. 为什么要进行数据库优化
避免网站页面出现访问错误
由于数据库连接timeout产生页面5xx错误 , to many connection 由于慢查询造成页面无法加载 : 由于数据库无法及时的返回数据, 导致页面一直无法返回 由于阻塞造成数据无法提交 :
很多数据库问题都是由于低效的查询引起的
流畅页面的访问速度 良好的网站功能体验
2. MySql数据库优化
可以从哪几个方面进行数据库的优化?如下图所示:
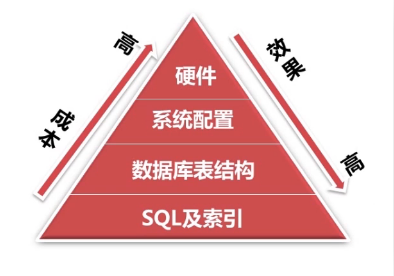
SQL及索引优化
根据需求写出良好的SQL,并创建有效的索引,实现某一种需求可以多种写法,这时候我们就要选择一种效率高的写法。这个时候就要了解sql优化
数据库表结构优化
根据数据库的范式,设计表结构,表结构设计的好直接关系到写SQL语句。
系统配置优化
大多数运行在Linux机器上,如tcp连接数的限制、打开文件数的限制、安全性的限制,因此我们要对这些配置进行相应的优化。
硬件配置优化
选择适合数据库服务的cpu,更快的IO,更高的内存;cpu并不是越多越好,某些数据库版本有大的限制,IO操作并不是减少阻塞。
注:通过上图可以看出,该金字塔中,优化的成本从下而上逐渐增高,而优化的效果会逐渐降低。
3. SQL及索引优化
3.1 准备数据
在mysql官网中, 给我们提供了一个实例数据库, 直接将这个实例数据库导入即可
页面地址: https://dev.mysql.com/doc/sakila/en/sakila-installation.html
点击实例数据下载地址, 下载即可

关于sakila-db.zip压缩包所包含的文件如下解释

sakila-schema.sql文件包含创建Sakila数据库结构所需的所有CREATE语句,包括表、视图、存储过程和触发器。
sakila-data.sql文件包含填充sakila-schema创建的结构所需的INSERT语句。以及必须在初始数据加载之后创建的触发器的定义。
sakila.mwb文件是一个MySQL工作台数据模型,您可以在MySQL Workbench中打开它来检查数据库结构。
将 sakila-db.zip 上传到linux, 并解压
使用rz命令上传即可: 如果使用rz显示没有此命令, 输入 yum -y install lrzsz 下载即可
由于是一个zip文件, 需要下载 unzip 才能解压压缩包: yum -y install unzip
解压压缩包: unzip sakila-db.zip
在数据库中创建对应表和库
连接数据库: shell> mysql -u root -p123456
导入数据: mysql> SOURCE /root/sakila-db/sakila-schema.sql;
导入数据
mysql> SOURCE /root/sakila-db/sakila-data.sql;
验证是否成功
USE sakila; # 使用数据库
SHOW TABLES; # 查看所有表

SELECT COUNT(*) FROM film;
SELECT COUNT(*) FROM film_text;

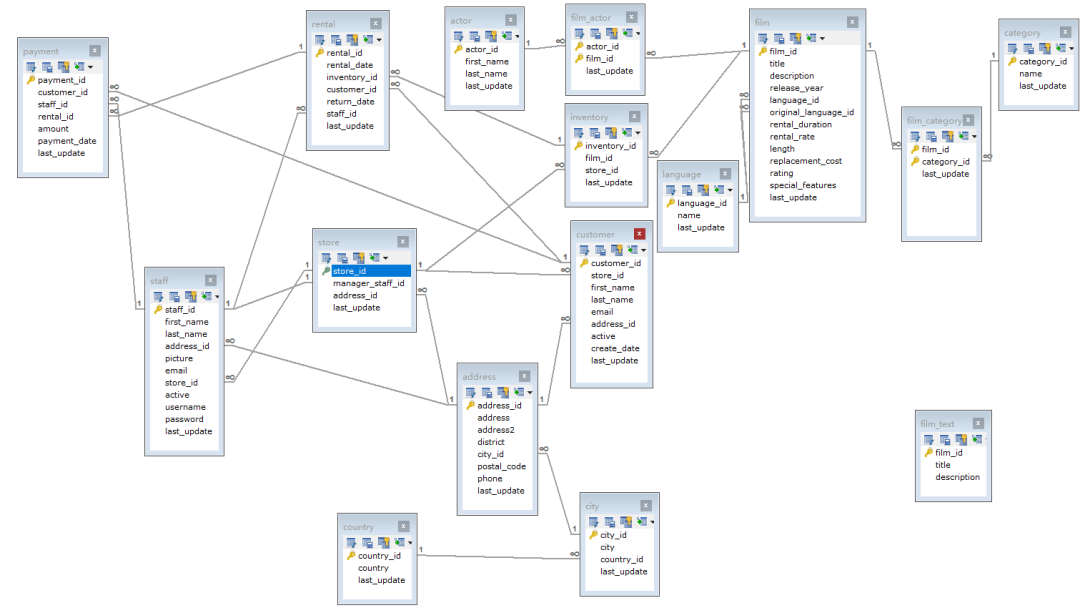
3.2 查看表结构
可通过sqlyog查看基本结构关系
3.3 如何发现有问题的SQL
mysql提供了慢查询日志查看功能, 可以帮助查询某一条SQL执行的一些状态
查询mysql是否开启慢查询日志
show variables like 'slow_query_log';

开启mysql的慢查询日志:
show variables like 'slow_query_log' ;
//查看是否开启慢查询日志
set global log_queries_not_using_indexes=on; // 将不使用索引的慢查询日志进行记录
set global slow_query_log=on; //开启慢查询日志
show variables like 'slow_query_log_file';
//查看慢查询日志存储的位置
set global long_query_time=1;
//大于1秒钟的数据记录到慢日志中,如果设置为默认0,则会有大量的信息存储在磁盘中,磁盘很容易满掉
检测是否已经开启:
Show databases;
Use sakila;
select * from store; // 执行查询
select * from staff; // 执行查询
监听日志文件,看是否写入 : 注意 后面的日志文件的路径需要通过查询slow_query_log_file参数
tail -100f /var/lib/mysql/node01-slow.log

mysql慢查询日志存储的格式说明:

说明:
1、# Time: 190412 22:05:02 >>> 查询的执行时间
2、# User@Host: root[root] @ localhost [] Id: 2 >>> 执行sql的主机信息
3、# Query_time: 0.001274 Lock_time: 0.000164 Rows_sent: 7 Rows_examined: 7 >>>> SQL的执行信息:
Query_time:SQL的查询时间
Lock_time:锁定时间
Rows_sent:所发送的行数
Rows_examined:所扫描的行数
4、SET timestamp=1555077861; >>>> SQL执行时间
5、select * from shop; >>>>> SQL的执行内容
如何通过慢查日志发现有问题的SQL
查询次数多且每次查询占用时间长的sql
通常为pt-query-digest分析的前几个查询;该工具可以很清楚的看出每个SQL执行的次数及百分比等信息,执行的次数多,占比比较大的SQL
注意pt-query-digest分析中的Rows examine项。扫描的行数越多,IO越大。
注意pt-query-digest分析中的Rows examine 和Rows Send的对比。说明该SQL的索引命中率不高,对于这种SQL,我们要重点进行关注。
4.MySQL慢查日志分析工具
4.1 mysqldumpslow
如何进行查看慢查询日志,如果开启了慢查询日志,就会生成很多的数据,然后我们就可以通过对日志的分析,生成分析报表,然后通过报表进行优化。
如何使用此工具: 可通过命令 : mysqldumpslow -h 查看使用教程

mysqldumpslow -v : 查看verbose(详细配置)信息

mysqldumpslow -t 10 /var/lib/mysql/mysql-slow.log : 查看慢查询日志的前10个分析结果
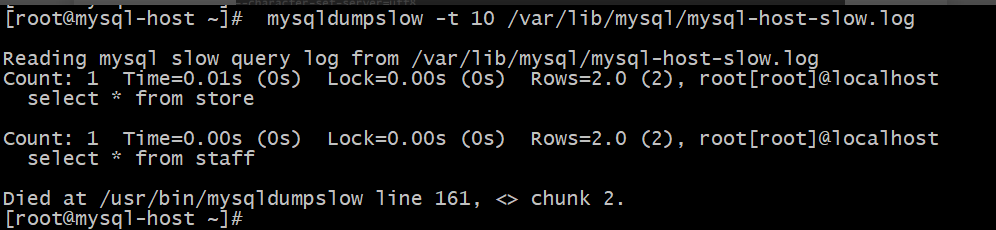
上图两条就是分析的结果,每条结果都显示是执行时间,锁定时间,发送的行数,扫描的行数
这个工具是常用的工具,通过安装mysql进行附带安装,但是该工具统计的结果比较少,对我们的优化锁表现的数据还是比较少. (可以看下这个: pt-query-digest)
5. 通过explain查询分析SQL的执行计划
explain : SQL的执行计划侧面反映出了SQL的执行效率,具体执行方式只需要在执行的SQL前面加上explain关键词即可。

各个字段说明


id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询。
select_type列常见的有:
A:simple:表示不需要union操作或者不包含子查询的简单select查询。有连接查询时,外层的查询为simple,且只有一个
B:primary:一个需要union操作或者含有子查询的select,位于外层的单位查询的select_type即为primary。且只有一个
C:union:union连接的两个select查询,个查询是dervied派生表,除了个表外,第二个以后的表select_type都是union
D:dependent union:与union一样,出现在union 或union all语句中,但是这个查询要受到外部查询的影响
E:union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null
F:subquery:除了from子句中包含的子查询外,其他地方出现的子查询都可能是subquery
G:dependent subquery:与dependent union类似,表示这个subquery的查询要受到外部表查询的影响
H:derived:from字句中出现的子查询,也叫做派生表,其他数据库中可能叫做内联视图或嵌套select
table
显示的查询表名,如果查询使用了别名,那么这里显示的是别名,如果不涉及对数据表的操作,那么这显示为null,如果显示为尖括号括起来的
就表示这个是临时表,后边的N就是执行计划中的id,表示结果来自于这个查询产生。如果是尖括号括起来的<union M,N>,与 类似,也是一个临时表,表示这个结果来自于union查询的id为M,N的结果集。 type
依次从好到差:system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery,index_subquery,range,index_merge,index,ALL,除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一个索引
A:system:表中只有一行数据或者是空表,且只能用于myisam和memory表。如果是Innodb引擎表,type列在这个情况通常都是all或者index
B:const:使用索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const。其他数据库也叫做索引扫描
C:eq_ref:出现在要连接过个表的查询计划中,驱动表只返回一行数据,且这行数据是第二个表的主键或者索引,且必须为not null,索引和主键是多列时,只有所有的列都用作比较时才会出现eq_ref
D:ref:不像eq_ref那样要求连接顺序,也没有主键和索引的要求,只要使用相等条件检索时就可能出现,常见与辅助索引的等值查找。或者多列主键、索引中,使用个列之外的列作为等值查找也会出现,总之,返回数据不的等值查找就可能出现。
E:fulltext:全文索引检索,要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引
F:ref_or_null:与ref方法类似,只是增加了null值的比较。实际用的不多。
G:unique_subquery:用于where中的in形式子查询,子查询返回不重复值值
H:index_subquery:用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重。
I:range:索引范围扫描,常见于使用
>,<,is null,between ,in ,like等运算符的查询中。J:index_merge:表示查询使用了两个以上的索引,后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取所个索引,性能可能大部分时间都不如range
K:index:索引全表扫描,把索引从头到尾扫一遍,常见于使用索引列就可以处理不需要读取数据文件的查询、可以使用索引排序或者分组的查询。
L:all:这个就是全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录。
possible_keys : 在查询一条SQL的时候, 这个SQL有可能会使用到多个索引,但是SQL在执行的时候, 只会选择其中的一个索引来使用
查询可能使用到的索引都会在这里列出来
key : 两个以上的索引称为复合索引
查询真正使用到的索引,select_type为index_merge时,这里可能出现两个以上的索引,其他的select_type这里只会出现一个。
key_len
用于处理查询的索引长度,如果是单列索引,那就整个索引长度算进去,如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列,这里不会计算进去。留意下这个列的值,算一下你的多列索引总长度就知道有没有使用到所有的列了。要注意,mysql的ICP特性使用到的索引不会计入其中。另外,key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
ref
如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
rows
这里是执行计划中估算的扫描行数,不是值
extra
这个列可以显示的信息非常多,有几十种,常用的有
A:distinct:在select部分使用了distinc关键字
B:no tables used:不带from字句的查询或者From dual查询
C:使用not in()形式子查询或not exists运算符的连接查询,这种叫做反连接。即,一般连接查询是先查询内表,再查询外表,反连接就是先查询外表,再查询内表。
D:using filesort:排序时无法使用到索引时,就会出现这个。常见于order by和group by语句中
E:using index:查询时不需要回表查询,直接通过索引就可以获取查询的数据。
F:using join buffer(block nested loop),using join buffer(batched key accss):5.6.x之后的版本优化关联查询的BNL,BKA特性。主要是减少内表的循环数量以及比较顺序地扫描查询。
G:using sort_union,using_union,using intersect,using sort_intersection:
using intersect:表示使用and的各个索引的条件时,该信息表示是从处理结果获取交集
using union:表示使用or连接各个使用索引的条件时,该信息表示从处理结果获取并集
using sort_union和using sort_intersection:与前面两个对应的类似,只是他们是出现在用and和or查询信息量大时,先查询主键,然后进行排序合并后,才能读取记录并返回。
H:using temporary:表示使用了临时表存储中间结果。临时表可以是内存临时表和磁盘临时表,执行计划中看不出来,需要查看status变量,used_tmp_table,used_tmp_disk_table才能看出来。
I:using where:表示存储引擎返回的记录并不是所有的都满足查询条件,需要在server层进行过滤。查询条件中分为限制条件和检查条件,5.6之前,存储引擎只能根据限制条件扫描数据并返回,然后server层根据检查条件进行过滤再返回真正符合查询的数据。5.6.x之后支持ICP特性,可以把检查条件也下推到存储引擎层,不符合检查条件和限制条件的数据,直接不读取,这样就大大减少了存储引擎扫描的记录数量。extra列显示using index condition
J:firstmatch(tb_name):5.6.x开始引入的优化子查询的新特性之一,常见于where字句含有in()类型的子查询。如果内表的数据量比较大,就可能出现这个
K:loosescan(m..n):5.6.x之后引入的优化子查询的新特性之一,在in()类型的子查询中,子查询返回的可能有重复记录时,就可能出现这个
除了这些之外,还有很多查询数据字典库,执行计划过程中就发现不可能存在结果的一些提示信息
filtered
使用explain extended时会出现这个列,5.7之后的版本默认就有这个字段,不需要使用explain extended了。这个字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数。
6. 具体慢查询优化的案例
6.1 函数 max() 的优化
例如: 查询订单的后支付时间
select max(payment_date) from payment;
优化前: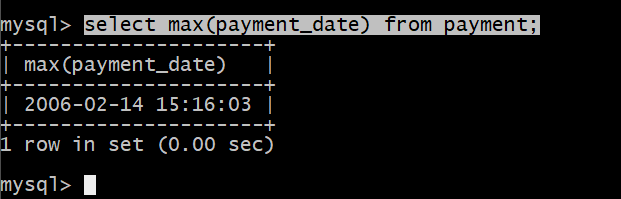
查看执行计划 :
explain select max(payment_date) from payment;

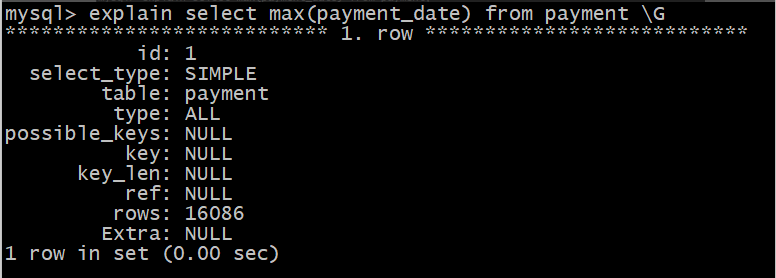
可以看到显示的执行计划,并不是很高效,可以拖慢服务器的效率,如何优化了?
创建索引 :
create index inx_paydate on payment(payment_date);

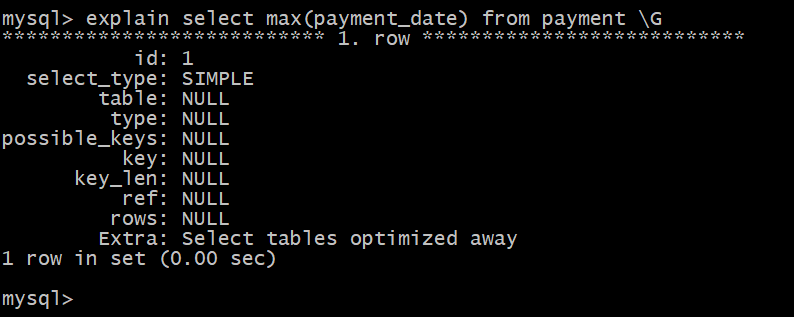
索引是顺序操作的,不需要扫描表,执行效率就会比较恒定!
6.2) 函数 count(*) 的优化
需求:在一条SQL中同时查询2006年和2007年电影的数量
错误写法 :
select count(*) from film where release_year='2006' or release_year='2007';
这种查询只能查询出2006年和2007年的总数量, 但是2006年和2007年分别是多少无法判断出来
正确的编写方式:
SELECT release_year, COUNT(*) FROM film GROUP BY release_year HAVING release_year='2006' OR release_year='2007';
区别:count(*)和count(id)
create table t(id int);
insert into t values(1),(2),(null);

count(*):select count(*)from t;

count(id):select count(id)from t;

说明:
count(id)是不包含null的值
count(*)是包含null的值
在创建表的时候, 尽可能的使用not null 的约束, 保证每一个字段默认值不是null值, 这样在执行count操作的时候, 就可以直接统计某一个字段的内容, 而不是统计所有的字段个数。
6.3 子查询的优化
子查询是我们在开发过程中经常使用的一种方式,在通常情况下,需要把子查询优化为join查询但在优化是需要注意关联键是否有一对多的关系,要注意重复数据。
在编写代码的时候, 如果使用子查询可能会比多表连接查询更加的简单, 所以在开发阶段, 可以使用子查询, 只要能够满足需要就可以,但是在正式上线的商业化使用的时候, 尽可能将子查询更改jon查询会更好的一点,join查询的效率要比子查询效率更高
查看我们所创建的t表:
create table t1(tid int);

接下来我们创建一个t1表
create table t1(tid int);
insert into t1 values(1);

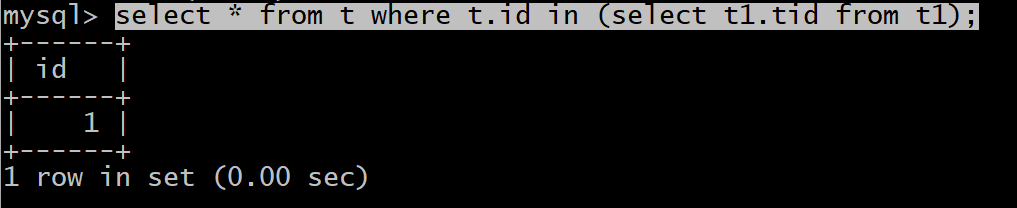
我们要进行一个子查询,需求:查询t表中id在t1表中tid的所有数据;
select * from t where t.id in (select t1.tid from t1);
接下来我们用join的操作来进行操作
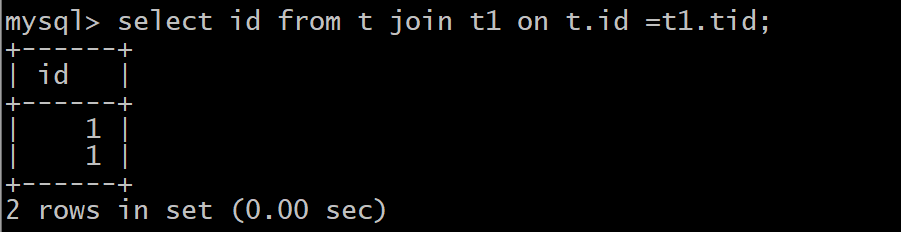
select id from t join t1 on t.id =t1.tid;

通过上面结果来看,查询的结果是一致的,我们就将子查询的方式优化为join操作。
接下来,我们在t1表中再插入一条数据
insert into t1 values (1);
select * from t1;

在这种情况下,如果我们使用子查询方式进行查询,返回的结果就是如下图所示:

如果使用join方式进行查找,如下图所示:
在这种情况下出现了一对多的关系,会出现数据的重复,我们为了方式数据重复,不得不使用distinct关键词进行去重操作
注意:这个一对多的关系是我们开发过程中遇到的一个坑,出现数据重复,需要大家注意一下。
总结: 需要将子查询更为 join 查询,效率比较高的
6.4 group by的优化
需求:每个演员所参演影片的数量-(影片表和演员表)
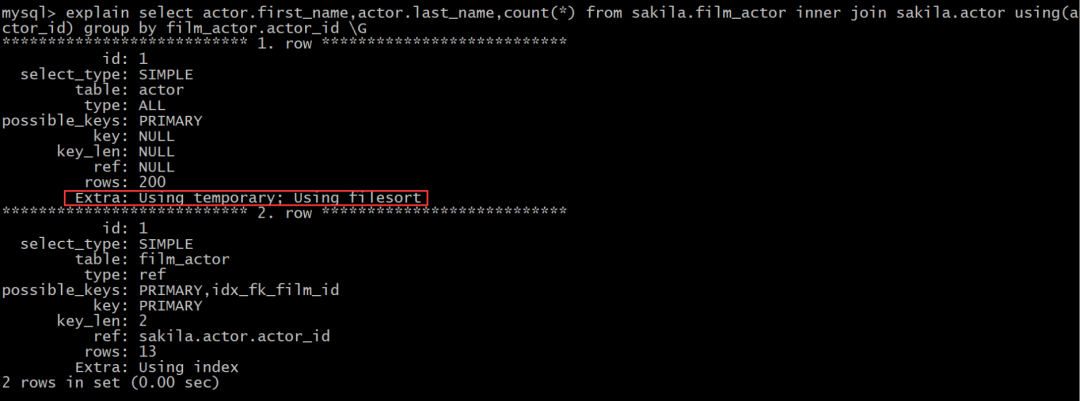
explain select actor.first_name,actor.last_name,count(*) from sakila.film_actor inner join sakila.actor using(actor_id) group by film_actor.actor_id;
优化后的SQL:
explain select actor.first_name,actor.last_name,c.cnt from sakila.actor inner join ( select actor_id,count(*) as cnt from sakila.film_actor group by actor_id) as c using(actor_id);
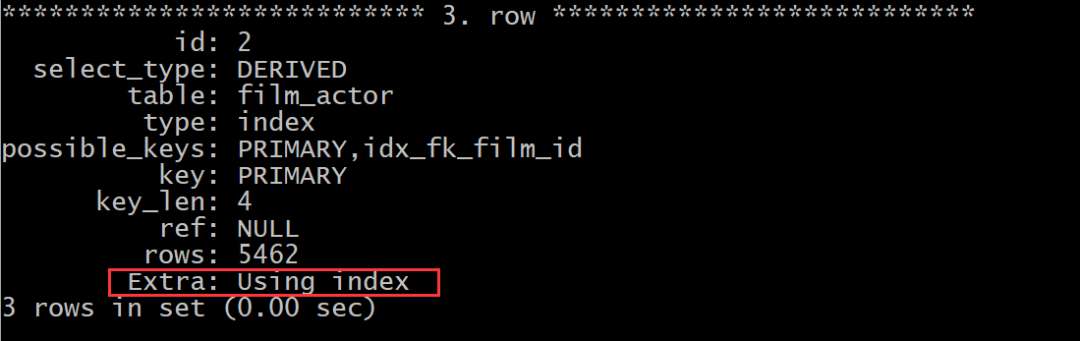
说明:从上面的执行计划来看,这种优化后的方式没有使用临时文件和文件排序的方式了,取而代之的是使用了索引。查询效率老高了。
这个时候我们表中的数据比较大,会大量的占用IO操作,优化了sql执行的效率,节省了服务器的资源,因此我们就需要优化。
注意:
mysql 中using关键词的作用:也就是说要使用using,那么表a和表b必须要有相同的列。
using(id) 类似于: on a.id = b.id
在用Join进行多表联合查询时,我们通常使用On来建立两个表的关系。其实还有一个更方便的关键字,那就是using。
如果两个表的关联字段名是一样的,就可以使用Using来建立关系,简洁明了。
6.5 Limit查询的优化
Limit常用于分页处理,时长会伴随order by从句使用,因此大多时候使用Filesorts这样会造成大量的IO问题。
需求:查询影片id和描述信息,并根据主题进行排序,取出从序号50条开始的5条数据。
select film_id,description from sakila.film order by title limit 50,5;
在查看一下它的执行计划:
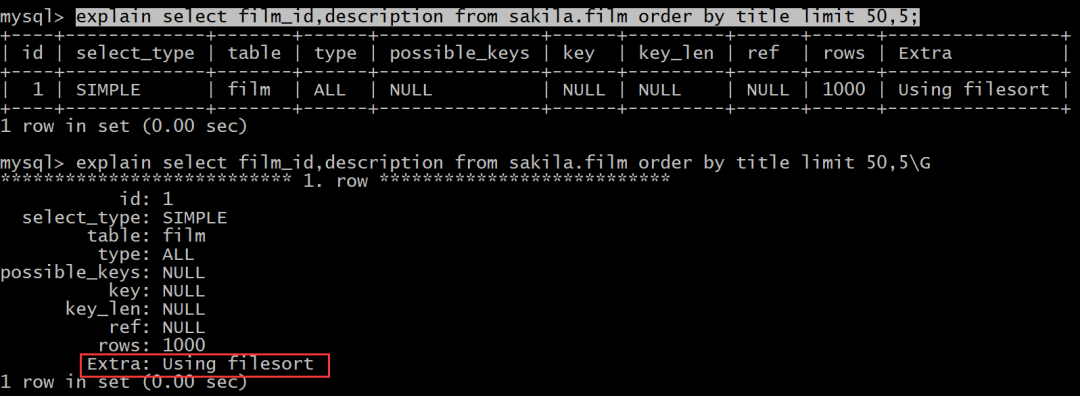
对于这种操作,我们该用什么样的优化方式了?
优化步骤1:
使用有索引的列或主键进行order by操作,因为大家知道,innodb是按照主键的逻辑顺序进行排序的。可以避免很多的IO操作。
优化1:
select film_id,description from sakila.film order by film_id limit 50,5;
查看一下执行计划
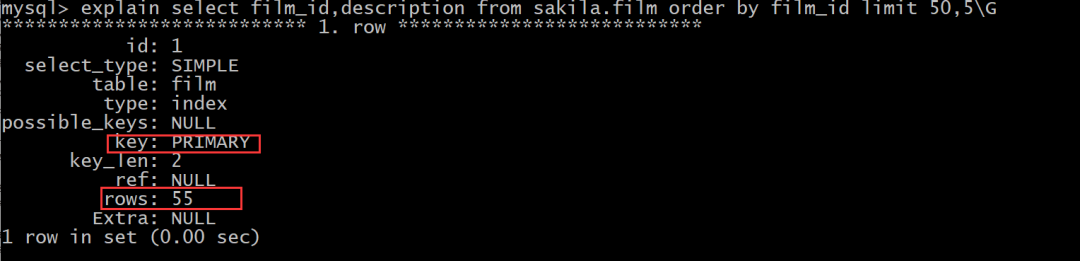
那如果我们获取从500行开始的5条记录,执行计划又是什么样的了?
explain select film_id,description from sakila.film order by film_id limit 500,5

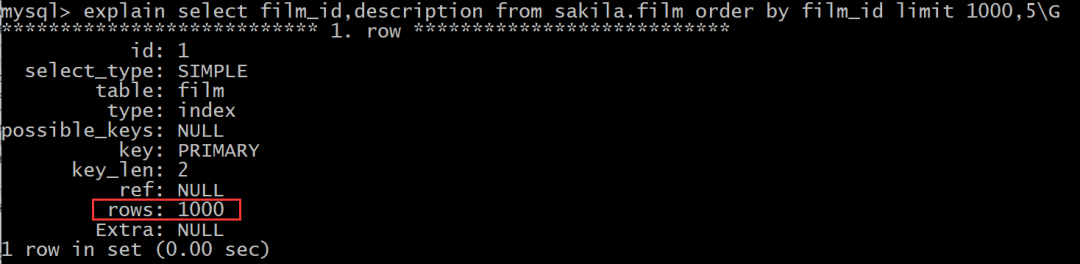
随着我们翻页越往后,IO操作会越来越大的,如果一个表有几千万行数据,翻页越后面,会越来越慢,因此我们要进一步的来优化。
优化步骤2
记录上次返回的主键, 在下次查询时使用主键过滤。(说明:避免了数据量大时扫描过多的记录)
上次limit是50,5的操作,因此我们在这次优化过程需要使用上次的索引记录值
优化2:
select film_id,description from sakila.film where film_id >55 and film_id<=60 order by film_id limit ,5;


结论:扫描行数不变,执行计划是很固定,效率也是很固定的
注意事项:
主键要顺序排序并连续的,如果主键中间空缺了某一列,或者某几列,会出现列出数据不足5行的数据;如果不连续的情况,建立一个附加的列index_id列,保证这一列数据要自增的,并添加索引即可。
总结:
尽可能避免 filesorts(文件排序) 和 row的扫描(越少越好)
因为这两种操作都会增加io操作
--END--
