一、数据类型
1.1 支持的数据类型
下图展示的是SinoDB支持的各种数据类型:

1.2 内置数据类型
1.2.2 字符型
1.2.3 时间
示例如下:
DATE:

DATETIME:

INTERVAL:

1.2.4 大对象
1.2.4.1 简单大对象
1.2.5 布尔型
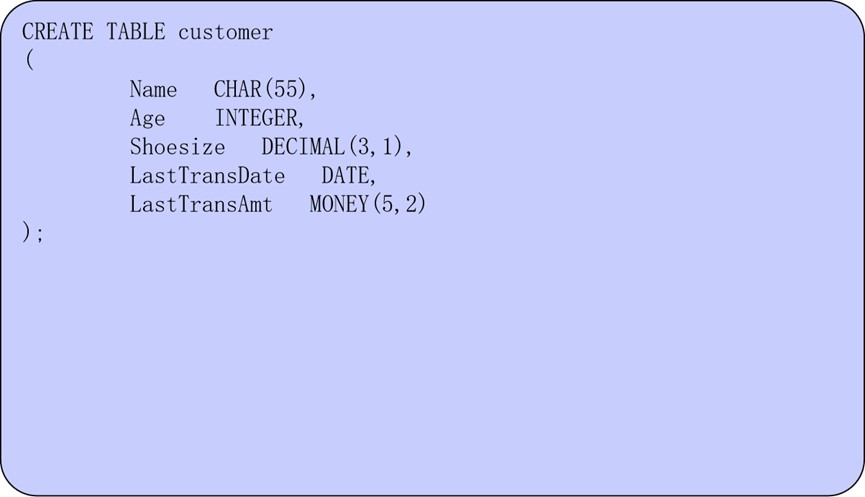
1.2.6 内置数据类型的示例
下面是一个使用内置数据类型创建表的示例:
1.2.7 扩展数据类型
1.2.7.1 复合数据类型
复合数据类型由一个或多个数据类型组合而成。复合数据类型有ROW类型、COLLECTION类型。对ROW、COLLECTION等类型的描述如下表所示:
下面是一个使用复合数据类型创建表的示例:
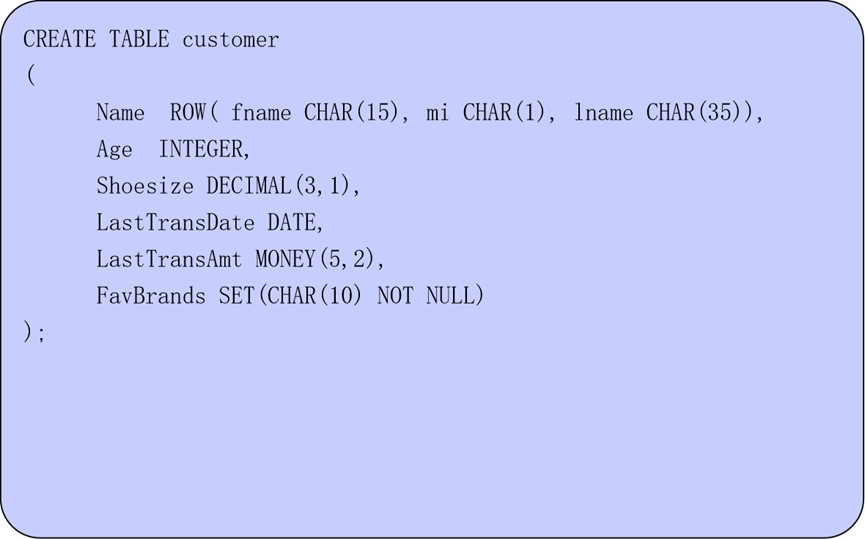
1.2.7.2 用户定义数据类型
二、创建数据库、数据表、视图
2.1 数据库创建
我们可以创建四种类型的数据库(database):
Ø 不记录日志

Ø 缓冲式的记录日志

Ø 无缓冲式的记录日志

Ø ANSI (记录日志时无缓冲, )

2.2 数据表
2.2.1 普通数据表
普通数据表在system catalog里注册。一个普通数据表可对多个session或connection可见,创建时可以指定dbspace。

2.2.2临时数据表
临时数据表不在system catalog里注册。一个临时数据表只对对应的某个session或connection可见,在对应的session或connection结束时被自动清除。如果临时dbspace存在的话,临时数据表将被建于临时dbspace中。缺省情况下,临时数据表是没有日志(log)的,支持索引。
使用“create temp table”来创建临时数据表:

使用“select … into temp”来创建临时数据表:

2.2.3 约束
2.2.3.1 主键约束
主键约束定义在一个或一组数据列上。主键的值是不重复的、不能是NULL。

2.2.3.2 引用约束
引用约束是数据表之间或数据表内的关系,一个数据表的主键可以被同一个数据表或其它数据表引用。主键被引用的数据表被称为父表(parent table),引用了父表的主键的数据表被称为子表(child table)。
如果在定义引用约束时使用了ON DELETE CASCADE,当把父表的数据行删除时,子表的相关数据行也会被自动删除。

2.2.2.3 检查约束
检查约束是定义了check constraint后,数据库在把数据赋给一个数据列之前将根据check constraint检查数据是否满足条件。

上面例子里的检查约束(check constraint)要求discount值必须在0.0和0.5之间。
2.2.4 视图
虚拟表,创建视图时使用SELECT语句,在system catalog里注册。视图没有自己的行,对于同一些数据表,可为不同的用户建立不同的视图,可配置存取权限。

三、简单查询
3.1 简单查询语句简介
我们使用select语句从数据库中查询数据。在大多数情况下,select语句是我们常用的SQL语句。Select语句的语法如下所示:

下面是几个SinoDB的sql简单示例:




 3.2 关系运算符
3.2 关系运算符
在SinoDB中,关系运算符有:
=
!= 或 <>
>
>=
<
<=
在where子句中使用关系运算符的示例:

 3.3 Where子句里可使用的关键字
3.3 Where子句里可使用的关键字
Where子句里可使用的关键字有:
(1) AND:逻辑与
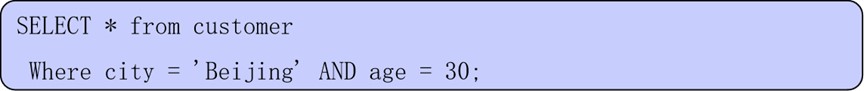
(2) OR:逻辑或
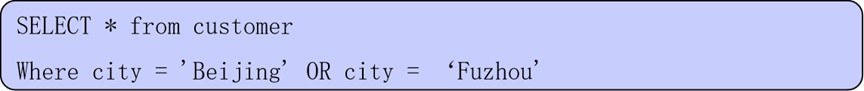
(3) [NOT] BETWEEN: [不]在。。。之间

(4) [NOT] IN: [不]在。。。里

(5) IS [NOT] NULL:[不]是NULL

(6) [NOT] MATCHES: [不]匹配

注:?表示单个字符

注:*表示0个或正整数个字符

注:[K-T]表示从K到T的任意字符
(7) [NOT] LIKE: [不]匹配

注:_表示单个字符

注:%表示0个或正整数个字符
3.4 对查询结果进行分组
我们可以使用group by对查询结果进行分组。分组后我们可以得到各个分组的统计信息,如平均值、总和、数据行数等。
使用group by order_num子句后,查询结果将按order_num分组。

使用group by对查询结果进行分组后,我们还可使用having字句来选出符合某些条件的分组。

使用group by order_num子句后,查询结果将按order_num分组。使用having sum(price) > 500子句后,查询结果中将只保留“价格总和”大于500的分组。
3.5 CASE子句
我们可以使用CASE表达式对返回值进行转换。
CASE表达式的语法如下:

上面的CASE表达式的意思是:
当expr为expr1时,返回result1;
当expr为expr2时,返回result2;
…
当expr为其它情况时,返回result_else。
CASE表达式的示例如下:
 3.6 DECODE
3.6 DECODE
我们可以使用DECODE函数对返回值进行转换。
DECODE函数的语法如下:

上面的DECODE函数的意思是:
当expr为expr1时,返回result1;
当expr为expr2时,返回result2;
…
当expr为其它情况时,返回result_else。
DECODE函数的示例如下:
 3.7 Union和Union All
3.7 Union和Union All
我们使用如果两个或多个select语句的结果相似,我们可以用“Union”或“Union All”把这些select语句合并起来。“Union”和“Union All”的区别是:“Union”将去掉结果中的非次出现的值,而“Union All”将保留结果中的非次出现的值。
 四、复杂查询
四、复杂查询
4.1 表连接的语法
Ø 我们可以使用两种方式进行数据表连接:
ü 数据表之间使用逗号,在WHERE子句指定连接条件
ü 数据表之间使用JOIN,连接条件前使用ON
Ø 内连接:仅生成满足结合条件的行
 4.1.1 外连接
4.1.1 外连接
如果我们有两个数据表employee和project,如图所示。
蓝色的员工表示负责有项目的员工,紫色的员工表示不负责项目的员工,
蓝色的项目表示有员工负责的项目,棕色的项目表示没有员工负责的项目。
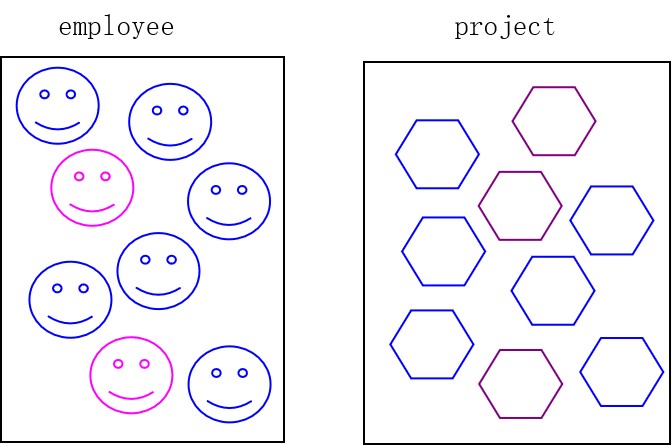
Ø 左外连接:以左表为基表,生成左表的所有行,右表中的某些行
哪个员工负责哪个项目,哪些员工不负责项目?

Ø 右外连接:以右表为基表,生成右表的所有行,左表中的某些行
哪个员工负责哪个项目,哪些项目没有人负责?

全外连接:生成两个表中所有的行,不管有没有表与它满足连接条件
哪个员工负责哪个项目,哪些员工不负责项目,哪些项目没有人负责?
 4.2 子查询
4.2 子查询
子查询包含相关子查询(correlated subquery)和不相关子查询(non-correlated subquery)两种类型。
在相关子查询中,子查询中涉及到父查询的数据列;
在不相关子查询中,子查询中不涉及到父查询的数据列。
相关子查询示例:

不相关子查询示例:
 4.2.1 将相关子查询转化成表连接
4.2.1 将相关子查询转化成表连接
在很多情况下,我们可以将相关子查询转化成表连接,这样数据库引擎有可能更方便的得到更优的查询计划,从而使SQL语句的执行时间减少。
例如:

可被转化成:
 五、插入、删除、更新数据行
五、插入、删除、更新数据行
5.1 插入数据行
我们可以使用insert语句往数据表里插入数据行。
如果是将各值按序赋给数据表的所有数据列,则不用指明数据列。例如:
 如果是将值赋给指定数据列,则需指明数据列。例如:
如果是将值赋给指定数据列,则需指明数据列。例如:
 我们可以在insert语句中嵌套select子句,从而将从一个或多个数据表查询来的数据插入到目标数据表。
我们可以在insert语句中嵌套select子句,从而将从一个或多个数据表查询来的数据插入到目标数据表。
 5.2 更新数据行
5.2 更新数据行
我们可以使用update语句为数据表更新数据行
update语句示例:
 5.3 删除数据行
5.3 删除数据行
我们可以使用delete语句从数据表里删除数据行。
delete语句示例:
 六、附属特性
六、附属特性
6.1 MERGE语句
将数据从源表传输到目的表:
Ø 将来自表、视图、“select子句的结果”里的信息汇聚在一起
Ø 可以将UPDATE、INSERT、DELETE包含在一条MERGE语句中
在 ETL/ELT 操作中非常有用。
与 ANSI/ISO 兼容。
从SinoDB11.50.xC5开始,MERGE语句支持UPDATE、INSERT。从SinoDB11.50.xC6开始,MERGE语句支持DELETE。
 6.2 数据的层次结构图
6.2 数据的层次结构图

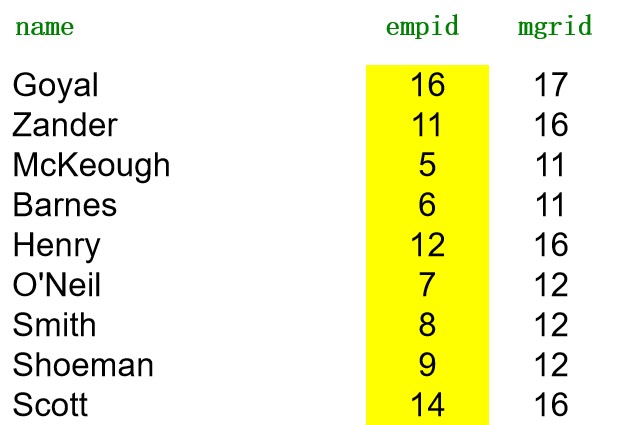
SELECT name, empid, mgrid
FROM emp
START WITH name = 'Goyal'
CONNECT BY PRIOR empid = mgrid
SinoDB从版本11.50.xC5开始支持 CONNECT BY 语句。
6.3 自动产生数据的数据类型
SERIAL、SERIAL8、BIGSERIAL都会自动产生数据。
用户可选择是否提供初始值。
SERIAL类型的数据占用4个字节的存储空间。
SERIAL8类型的数据一般情况下占用10个字节的存储空间。
(在Extended Parallel Server中占用8个字节的存储空间)。
BIGSERIAL类型的数据占用8个字节的存储空间。
