作者介绍: 那海蓝蓝,腾讯技术工程事业群计费平台部金融云TDSQL数据库T4级专家,熟悉PostgreSQL、MySQL、Informix等数据库内核技术,著有《数据库查询优化器的艺术》一书。《数据库事务处理的艺术》为新出版力作,经机械工业出版社授权,“腾讯技术工程官方号”将免费开放阅读,我们将分期为读者奉上那海蓝蓝的技术盛宴。
本篇介绍数据库管理系统的事务处理技术,从数据库的事务理论出发界定事务处理技术的范围,讨论了事务机制应对的问题、事务处理的理论基础和并发控制技术。
全篇立足于数据库事务处理的基本理论,第 1 章界定了本书讨论的事务处理技术所解决的问题,帮助读者理解事务处理技术的背景和需求。在笔者看来,理解问题比掌握解决问题的方式更为重要。
第 2 章讲述事务处理技术的基本概念和理论,但不是对经典教科书的翻录,而是结合笔者多年数据库内核开发的心得和经验,融入自己的理解,帮助读者从众多的头绪中理出线索。当然,要想彻底理解掌握事务处理的基础理论,还需要系统、全面地阅读经典的事务处理教材。
如果能够把阅读经典教材和本书相结合,并对比印证,则如步入百花丛中:百花丛中识花香,迷雾梦里寻捷径,这是一本好书所能做到的事情。
但愿书长久,十年共婵娟。
第 1 章 数据库管理系统的事务原理
数据库管理系统(DataBase Management System,DBMS,以下简称“数据库”),是位于用户与操作系统之间的一层数据管理软件,功能主要包括:数据定义、数据操纵、数据库的运行管理、数据库的建立和维护 等 。
数据库的事务处理机制,是数据库技术的基石。掌握数据库技术,必须要掌握事务处理的技术,这样才能把握数据库的核心技术。同时,也必须了解数据库为什么会需要事务处理技术,即事务处理技术要解决的问题,这一点,就是我们在章节开门见山地提出的问题。
1.1 事务模型要解决的问题
事务模型,是电子交易操作的保障。没有事务模型,并发操作以及操作中途的系统异常将可能使数据发生混乱,本节就各种潜在的问题进行讨论。
1.1.1 为什么需要事务处理机制
数据库为什么需要事务处理机制?
面对这个问题,一些数据库相关从业者掩卷思考,给出以下几个答案:
答案一:数据库的事务处理机制,主要是解决脏读、不可重复读、幻读等问题的。答案二:数据库的事务处理机制,主要是实现了ACID 特性的。
答案三:数据库的事务处理机制,主要是以多版本两阶段封锁协议实现可串行化快照隔离。引自《数据库系统概论》王珊,萨师暄著。
以上答案,哪个正确呢?其实,没有一个是正确的。
对于个回答,提出了事务处理技术中可能出现的三种经典问题,这三种问题,是数据库事务处理技术中并发控制模块为实现不同隔离级别而要解决的三个问题,不是事务处理机制面临的问题。所以个回答,以局部问题来覆盖整体,以偏概全了。
第二个回答,提出了 ACID四大特性 ,这四个特性在关系型数据库中一个也不可少, 但这仅仅是“四个特性”,并不是我们需要数据库事务处理机制的根本原因。
第三个回答,提出了多项事务处理机制中需要的技术,如多版本(Multiversion concurrency control,MVCC)、两阶段封锁(2 Phase Lock)、快照隔离(Snapshot Isolation)等,但是这些技术仅仅是事务处理机制中的一些重要技术,用于并发控制管理和隔离级别的实现,并不是需要事务处理机制的原因。
那么,什么是数据库事务模型被提出的原因呢?
我们先回避问题,绕道看如下的一个实际用户操作,从 A 账户转账 50 元到 B 账户,其过程如表1-1 所示。
表 1-1 事务处理机制的作用
种情况,没有事务处理机制
第二种情况 ,有事务处理机制
1. read(A)
2. A := A – 50
3. write(A)
4. read(B)
5. B := B + 50
6. write(B)
begin
1. read(A)
2. A := A – 50
3. write(A)
4. read(B)
5. B := B + 50
6. write(B)
commit
假设第 3 行“3. write(A) ”操作完成,A 账户已经少
了 50 元
假设第 3 行“3. write(A) ”操作完成,A 账户已经少
了 50 元
从第四行开始,数据库宕机;重启后,A 账户少了 50
元但是 B 账户却没有增加 50 元
从第四行开始,数据库宕机;重启后,事务没有提交,
A 账户尽管少了 50 元,但是事务因没有成功提交,导致 A 减少 50 元的操作“失效”
那么,A 少了的 50 元,哪里去了?
那么,A 少了 50 元的操作,被回滚掉了,A 不会有
经济损失
如果发生这样的事情,谁还敢用数据库来记录交易信息?
如果发生这样的事情,A 是不是不用担心划账失败了?
事务处理机制,就是要保证用户的数据操作动作对数据是“安全的”。
那么,什么样的操作是安全的呢?数据只有在带有“ ACID ”四个特性的事务处理机制的保障下,才可以认为是“安全的”。
这里提到的大家耳熟能详的“ ACID”四个特性,正是事务模型的核心内容。事务概念及其相关技术(为实现“ACID”四个特性的技术)的提出,给应用开发人员抽象出一个非常好用的数据处理模型,这个模型可以保证:操作间串行执行,执行中不必担心出错。这
ACID,A是原子性,C是一致性,I是隔离性,D是持久性。详见1.2.1节。
就是事务模型被提出的原因。A 保证了操作(一些有完整逻辑意义的数据读写动作)要么成功要么失败,A 和 C 保证了数据不会因写操作发生不一致,I 保证了在多会话并发读写同一份数据的情况下数据的完全一致(或数据可能不一致但尚可接受),D 保证了被修改的数据能长久地存储。
事务模型自被提出后,逐渐成为商业世界稳定有序运作的基石,数据和数据承载的交易事件的结果不会因系统故障被损伤。关系型数据库管理系统实现了事务模型,使得数据库在电子交易中发挥了非常重要的作用。这也是数据库为什么需要事务处理机制,即事务模型的原因。
1.1.2 事务机制要处理的问题—事务故障、系统故障、介质故障
事务模型是商业世界运作的基石,主要体现在交易处理电子化。作为一个软件系统, 数据库系统会遭遇一些故障,如我们常说的事务故障、系统故障、介质故障等。
对于数据库系统,因为数据实在太为重要,数据库系统应该能够保证在出现故障时, 数据依然满足 ACID 特性。
对于事务内部的故障,一般可分为预期的和非预期的。预期的事务内部故障是指可以通过数据库的事务处理机制发现的事务内部故障,这时数据库的事务处理机制提供了回滚操作保证了数据免受损害;非预期的事务内部故障如运算溢出故障、并发事务死锁故障、违反了某些完整性约束而导致的故障等,数据库系统依然可以通过回滚操作保证数据免受损害,所以回滚操作在事务处理机制中占有重要地位,不同的数据系统对回滚的实现方式也不尽相同。
对于系统故障,如数据库在运行过程中,由于硬件故障、数据库软件及操作系统的漏洞、突然停电等,数据库系统停止运行,所有正在运行的事务以非正常方式终止,需要数据库系统重新启动,这时,数据库系统为保障ACID 特性,提供了基于 REDO/UNDO 的恢复机制,可以正确恢复到系统崩溃前的状态。
介质故障也称为硬故障,主要指数据库在运行过程中,由于磁头碰撞、磁盘损坏、强磁干扰、天灾人祸等情况,使得数据库中的数据部分或全部丢失。解决这一类故障,要依赖于备份系统和归档日志,归档的日志、系统运行期间记载的REDO/UNDO 日志等日志相关内容,也是事务处理机制的一部分,日志管理部分的内容较多,一般的书籍会将日志管理独立为若干章节进行讨论。
总的来说,事务处理机制为应对这三类故障,提供了很多技术,如日志与恢复子系统、并发控制子系统、存储子系统等,和事务处理机制密切相关,我们将在1.2 节继续进行讨论。
1.1.3 并发带来的问题—三种常见的读数据异常现象
数据不在 ACID 特性的保护下会发生不一致的现象,那么:在 ACID 的保护下,是不是数据就一定不会产生不一致的现象呢?
在关系数据库系统中,多个会话(session)可以访问同一个数据库的同一个表的同一行数据。这样,对于数据而言,就意味着在同一个时间段内,有多个会话可以对其施加操作(或读操作或写操作),读写操作施加的顺序不同以及事务中 A 特性对事务结果的影响(或成功或失败,即要么提交要么中止),这三种因素叠加在一起,会存在几种对数据有不同影响的情况:
- 读– 读操作:如果同时只存在多个读操作,对于数据自身则没有影响;既读和读操作互不影响数据的一致性,读读操作可以并发执行。
- 读 – 写操作:如果读写操作都存在,因写在前读在后(如脏读现象)、读在前写在后
(如不可重复读现象),或者读在前写在后然后又读(如幻象现象),就可能因数据被写而导致另外一个读操作的会话读到错误的数据。这个操作可以根据动作发生的先后顺序被细分为读 – 写操作、写 – 读操作。
- 写 – 写操作:如果同时存在多个写操作,写 – 写操作直接改变了数据在同一时刻的语义,这就更不被允许,所以写 – 写操作通常不允许被并发执行。但是,如果不做并发控制,写– 写并发操作也会带来数据异常现象(1.1.4节探讨写 – 写操作引发的异常)。
这三种情况的第二种,对应了 SQL 标准中定义的三种数据异常的现象,注意这三种异常都是针对某个事务(第 2.2.1 节称这样的事务为“主事务”)的读操作而言的。SQL2003标准对于数据异常现象的定义如下:
The isolation level specifies the kind of phenomena that can occur during the execution of concurrent SQL-transactions. The following phenomena are possible:
1) P1 (“Dirty read”): SQL-transaction T1 modifiesa row. SQL-transaction T2 then read sthat row before T1 performs a COMMIT. If T1 then performs a ROLLBACK, T2 will have read a row that was never committed and that may thus be considered to have never existed.
2) P2 (“Non-repeatable read”): SQL-transaction T1 readsa row. SQL-transaction T2 then modifies or deletes that row and performs a COMMIT. If T1 then attempts to reread the row, it may receive the modified valueor discover that the row has been deleted.
3) P3 (“Phantom”): SQL-transaction T1 reads the set of rows N that satisfy some <search condition>. SQL-transaction T2 then executes SQL-statements that generate one or more rows that satisfy the <search con-dition> used by SQL-transaction T1. If SQL-transaction T1 then repeats the initial read with the same <search condition>, it obtains a different collection of rows.
怎么理解上面的内容呢?从 SQL 标准的定义可以看出:
首先,涉及了并发事务(concurrentSQL-transactions):至少有两个事务同时发生,如上面所举的三种异常现象中,分别使用了事务T1和 T2。但是,更为复杂的情况,如下一节所谈到的“写偏序(writeskew)”现象的发生可以是两个或三个事务同时发生。
其次,涉及了隔离级别(isolation level):如果多个事务是“可串行化”的,则意味着事务之间不应该互相影响(不是“一定互不影响”而是“不应该互相影响”),即逻辑上不应当存在“读写”冲突,所以数据库引擎实现时应该避免“读写”冲突造成的数据不一致的现象。避免的含义就是在数据库引擎编码实现的时候,采取并发控制技术,消除“脏读”、“不可重复读”、“幻象”这三种现象。采取的手段是分级控制(不同的隔离级别),分别使用“已提交 (READCOMMITTED)”、“可重复读(REPEATABLE READ)”和“可串行化(SERIALIZABLE)”这几种隔离级别,来应对这三种数据不一致的现象。
数据操作的对象,脏读和不可重复读是以“row”(一行)为单位,而幻象现象操作的是一个数据集(零行到多行)。
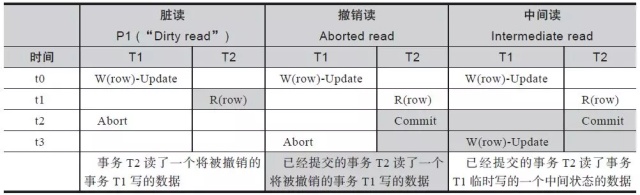
下面,我们把 SQL 标准的话语转为一个表格(如表 1-2 所示),以更好地理解一下三种异常现象。
表 1-2 SQL 标准定义的三种读数据异常现象

说明:
- 表格头两行,表明 SQL 标准定义的三种异常现象,分别是脏读、不可重复读、幻象。
- 表格列,时间值列,表明时间值在逐渐增长,即 t0<t1<t2<t3。
- 对于每一种异常现象,都分为2个列,分别是两个并发的事务,各自命名为 T1事务和 T2事务。
- 表格中的 R(row),表示读 row数据对象;W(row) 表示写 row对象,读写操作的是同一个数据对象 row;W(row)-Update/Delete后面的 Update/Delete表示的写操作是DML语句中的 UPDATE或 DELETE语句产生的写数据库对象 row的操作。
- 带有“ R(rows)-WHERE<condition> ”的表示SQL语句读数据(通常是 SELECT语句)带有 WHERE子句,此子句的条件表达式是“<condition> ”。
- 带有“ W(rows)-Update/Insert-<condition>”的表示写操作生成的数据满足与其他事务读操作带有的相同的条件表达式“<condition> ”,且此写操作要么是UPDATE,要么是 INSERT语句。
- 带有底色的,表示其对应时刻,如果发生对应的操作,将引发异常现象。
- 脏读现象:按照时间顺序,T1事务在 t0时刻对 row进行了修改(更新),T2事务在 t1时刻先读取了被 T1修改了的 row的值,但是 T1在 t2时刻中止使得对row的修改失效。如果数据库引擎不支持因并发操作避免数据异常,则 T2在 t1 时刻读到的就是 T1修改后的数据,但是这个数据在现实世界中不存在,对于事务 T2而言,读取了被回滚掉的数据,即事务 T2发生了脏读异常现象。另外 , 对于脏读现象 , 还存在如表 1-3的两种变形情况。
- 不可重复读现象:事务 T1在 t0时刻先读取 row的旧值,事务 T2在 t1时刻对 row进行了修改(更新或删除)然后提交事务使得修改生效,此时row因更新变为了新值或因删除而不再存在。接下来,事务 T1在 t3时刻再次读取 row对象的值但是 row的值已经是新值或者不存在了。对于事务 T1 而言,物是(同样是读 row这个对象)人非(值已经和 t0时刻读到的值不同),事务 T1发生了不可重复读异常现象。
- 幻象现象:事务 T1在 t0时刻带有特定条件地读取了row对象的数据,事务 T2在 t1 时刻插入新的数据或更新其他旧数据但满足事务T1的特定 WHERE 条件,新的数据满足与事务 T1同样的条件,当事务 T1在t3时刻再次以同样的条件读取数据的时候,rows 对象的值已经有新加入的行(因插入而比次读多出了数据)。对于事务 T1而言,物是(同样是读满足“<condition> ”条件的多个 row对象)人非(值已经和 t0时刻读到的值不同),事务 T1发生了幻象异常现象。幻象又称为幻读,即第二次读操作读取了次读操作没有读到的rows(一行或多行)。
脏读异常的变形如表 1-3 所示。
表 1-3 脏读异常的变形
在了解了 SQL 标准定义的三种异常现象后,回到我们在本节开始提出的问题:
在 ACID 的保护下,是不是数据就一定不会产生不一致的现象呢?
答 案 已 经 很 明确: 即 使 数 据 库 系 统 提 供 ACID, 除 非 我 们 使 用“可 串 行 化
(SERIALIZABLE)”隔离级别,否则数据在其他不同的隔离级别下还会产生数据不一致的现象。
有关这三种数据异常现象的更多探讨,请参见 1.1.7 节。
1.1.4 并发带来的问题—写 – 写并发操作引发的数据异常现象
上一节,我们探讨了三种读数据异常现象,请注意,异常现象发生在一个事务中后面的READ 读操作上。这三种读数据异常现象被 SQL 标准定义。那么:是不是对数据的并发操作只会产生上述的三种读数据异常现象?
事务概念的奠基人,Jim Grey 先生,在其著作《事务处理:概念与技术》中提到了一个“Lost Update ”异常的概念,字面含义是“更新丢失”,这是一个写操作的异常,与上一节提到的三种读操作异常不同。
除了“ Lost Update ”异常外,这一节我们还将探讨另外一种异常,如表 1-4所示。
表 1-4 写数据异常现象
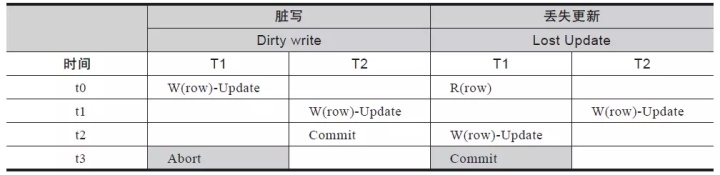
说明:
- 表格头两行,表明写写并发操作引发的两种异常现象,分别是脏写、丢失更新。
- 表格列,时间值列,表明时间值在逐渐增长,即 t0<t1<t2<t3。
- 对于每一种异常现象,都分为2个列,分别是两个并发的事务,各自命名为 T1事务和 T2事务。
- 表格中的 R(row),表示读 row数据对象;W(row) 表示写 row对象,读写操作的是同一个数据对象 row;W(row)-Update后面的 Update表示的写操作是 DML语句中的UPDATE语句产生的写数据库对象 row的操作。
- 带有阴影背景的,表示其对应时刻,如果发生对应的操作,将引发异常现象。
- 脏写现象:按照时间顺序,事务 T1在 t0时刻对 row进行了修改(更新),事务 T2在 t1时刻对 row进行了修改(更新),如果没有并发控制,T2对 row的修改会生成新值,但是 T1在 t3时刻回滚使得 T2对 row的修改失效,而 T1的语义是:T1 自身对 row的修改失效,这就把 T2修改的值回滚掉。对于事务 T1而言,回滚掉了不是自己修改的数据,即事务 T1上发生了脏写现象。
- 丢失更新现象:按照时间顺序,事务 T2在 t1时刻对 row进行了修改(更新),事务
T1在 t2时刻对 row进行了修改(更新),如果没有并发控制,T1对 row的修改会生成新值,但是 T1在 t3时刻提交使得 T2对 row的修改失效。对于事务 T1而言,覆盖掉了不是自己修改的数据,即事务 T1上引发了丢失更新现象(t3时刻如果是事务
T2提交而不是事务T1提交,也是丢失更新,只是事务T2上引发了丢失更新现象)。不管是读异常还是写异常,并发控制技术都要规避这些异常,保证数据在不同隔离级别下一致性不被破坏。
1.1.5 语义约束引发的数据异常现象
如果说数据在 ACID 特性(带有了并发控制技术)的保护下会发生不一致的现象,那么:在 ACID 和快照隔离级别技术(多版本)的保护下,是不是数据就一定不再会产生不一致的现象呢?
答案是否定的。数据库系统中数据的异常,在多种并发控制技术中已经被解决,但这不表明所有的异常都已经被解决,更不表明不再有新的异常被发现。
我们知道,数据库并发控制技术中有一个大名鼎鼎的技术,称为快照隔离(Snapshot Isolation) ,这项技术解决了读和写之间的冲突,在保证数据不会产生前面两节提到的读异常和写异常的情况下,使得读写互不阻塞(两阶段封锁技术中读写操作互相阻塞),提高了并发度。
注意我们这里谈到的多版本是“multi-version,简称 MV ”,其相对于“single-valued,简称 SV”,这个多版本是指并发控制技术中的数据项有多个版本,其含义仅此而已。快照隔离并发技术是多版本并发控制(Multiversion concurrency control,MVCC)技术的一部分, 其发生作用,需基于“数据项存在多个版本”。
快照隔离并发控制技术的缺点,是并不能真正保证事务为“可串行化的”,即事务间的并发操作依旧会引发数据异常现象,但是这里的数据异常现象有别于前面提到的各种异常现象,其异常现象是“业务的逻辑语义”引发的,即除了抽象的读写操作,数据间还应该满足一定语义,即约束(constraint)。
在快照隔离并发控制技术中并发的事务因不满足约束而发生的异常,称为“写偏序(Write Skew)”,这样的异常有两种,参见表 1-5。
说明:
- 表格头两行,表明写偏序异常现象的两种情况,分别是由两个事务引发异常、三个事务引发异常。
- 表格列,时间值列,表明时间值在逐渐增长,即 t0<t1<t2<t3<t4<t5<t6<t7。
- 对于每一种异常现象,都分为2个列,分别是两个并发的事务,各自命名为 T1事务和 T2事务。
详情参见2.1.2节。
表 1-5 写偏序异常的两种情况
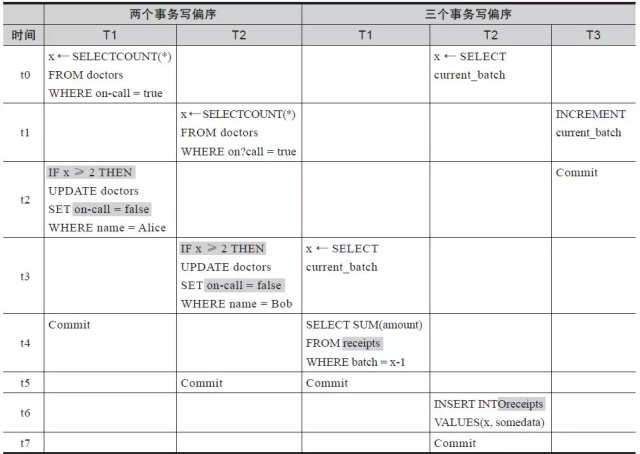
二个事务引发的异常现象(简单写偏序,Simple Write Skew):按照时间顺序,T1 事务在t0时刻读取了在打电话的值班医生个数,T2事务在 t1时刻也读取了在打电话的值班医生个数。事务 T1在 t2时刻进行判断:如果在打电话的值班医生个数大于等于2 人则请Alice停止打电话。事务 T2在 t3时刻进行判断:如果在打电话的值班医生个数大于等于 2人则请 Bob停止打电话。然后事务 T1和 T2分别提交。如果在这种并发的情况下,允许事务T1和 T2都提交成功,则 t6时刻,Alice和 Bob都停止了打电话。如果串行执行事务,先执行事务 T1后执行事务 T2,Alice会停止打电话但 Bob不会停止,这与前一种情况的结果不同;如果先执行事务 T2后执行事务 T1,Bob会停止打电话但 Alice不会停止,这与前一种情况的结果也不同;这表明前一种并发执行是非序列化的,而此时,事务 T1、T2并发时违反了约束(约束为:如果同时打电话的人数大于等于2人则请 Alice或 Bob其中一个人停止打电话直到同时打电话的人数少于 2人) 发生了写偏序异常现象。对于简单写偏序,可以用一个形象化的图表示,如图 1-1 所示。
图 1-1 两个事务引发的异常现象优先图
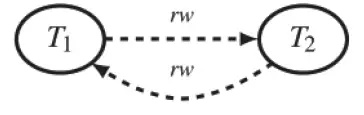
示例源自论文:DanR.K. Ports,KevinGrittner,SerializableSnapshotIsolationinPostgreSQL
三个事务引发的异常现象(Batch Processing):对于这种情况,后两个并发更新事务T3 和 T2 是可串行化的且不存在任何异常,但是一个只读事务 T1 出现在某个时刻却可能正好造成问题。所出现的问题是这样的,当事务 T3 提交时,T2 处于活跃状态, 这时,事务 T1 启动要读取事务 T2 和 T3 涉及的数据(current_batch 和 receipts),这时,事务 T1 的快照包括了事务T3 的插入后的结果(因为 T3 已经提交);但是,事务 T2 没有提交,它的插入操作数据不包含在事务 T1 的快照中。在优先图(如图 1-2 所示)中会造成一个环(有关如何形成这样的环,参见 2.2.5 节),说明这样的调度是非可串行化的。
图 1-2 三个事务引发的异常现象优先图

本节所述的这两种情况,如果使用优先图表示,都可以在参与操作的事务之间,画出一个环,存在环说明:调度是非可串行化的。为解决这样的问题,要求数据库引擎必须在事务提交时(甚至是环一形成即立刻回滚其中的一个事务)而不是在快照上检查完整性约束,以避免本节所述的不一致现象。
1.1.6其他的异常
在《A Critique of ANSI SQL Isolation Levels》这篇论文中,除了上面提到的几种异常现象外,还提到了另外两种异常,如表 1-6 和表 1-7 所示。
表 1-6 读 偏 序
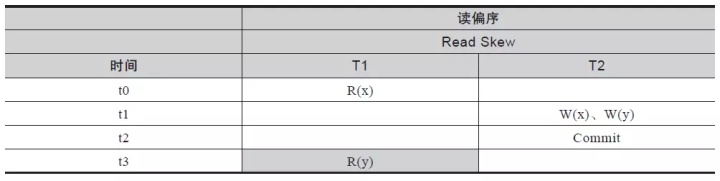
图1-1、图1-2的具体含义,请参见2.2.5节。
说明:
- 表格头两行,表明读偏序异常现象,是由两个事务引发异常。
- 表格列,时间值列,表明时间值在逐渐增长,即 t0<t1<t2<t3。
- 对于读偏序异常现象,都分为2个列,分别是两个并发的事务,各自命名为 T1事务和 T2事务。
- 事务 T1在 t0时刻读出数据 x,事务 T2在 t1时刻对数据 x和 y进行了修改在 t2时刻提交,事务 T1在 t3时刻读取 y,y是被事务 T2修改后的数据,此时已经不是 t0 时刻事务 T1读取 x时对应的 y值,数据形成了不一致状态(注意此时不是数据x处于不一致,而是 y处于不一致)。
游标(Cursor),是数据库引擎提供的一种读取数据的方式。在数据库中,为了防止使用游标时其他事务并发修改游标所包括的数据,定义了游标稳定性(Cursor Stability)隔离级别,这样的隔离级别,是在读取当前数据项的时刻,在数据项上加锁,当游标从当前数据项移走则解锁,此后曾经被读取过的数据项不再被并发保护(尽管使用游标的事务没有提交或中止,还处于活动状态)。但是,在使用游标的时候,也会发生写 – 写异常,如表 1-7所示。
表 1-7 游标丢失更新

说明:
- 表格头两行,表明写 – 写并发操作引发的异常现象,游标丢失更新。
- 表格列,时间值列,表明时间值在逐渐增长,即 t0<t1<t2<t3。
- 对于每一种异常现象,都分为2个列,分别是两个并发的事务,各自命名为 T1事务和 T2事务。
- 游标丢失更新现象:按照时间顺序,事务 T1在 t0时刻读取 row的值后,即释放了
row 上的锁使得 row 没有被并发保护,事务 T2 在 t1 时刻对 row 进行了修改(更新),事务 T1 在 t2 时刻对 row 进行了修改(更新),如果没有并发控制,T1 对 row 的修改会生成新值,但是T1 在 t4 时刻提交使得 T2 对 row 的修改失效。对于事务 T1 而言, 覆盖掉了不是自己修改的数据,即事务 T1 上引发了丢失更新现象。这样的现象,本质上就是丢失更新,只是发生在了游标上,所以称为游标丢失更新。
我们在 1.1.3 至 1.1.6 节,介绍了各种因并发引发的异常现象,有多种技术(2.2 节介绍多种并发控制技术)可以解决这些异常现象,如下我们借用《A Critique of ANSI SQL Isolation Levels》这篇论文中的一张表,来简单总结一下前面几节所谈到的各种异常,如表1-8 所示。与隔离级别相关的内容,参见 2.1节。
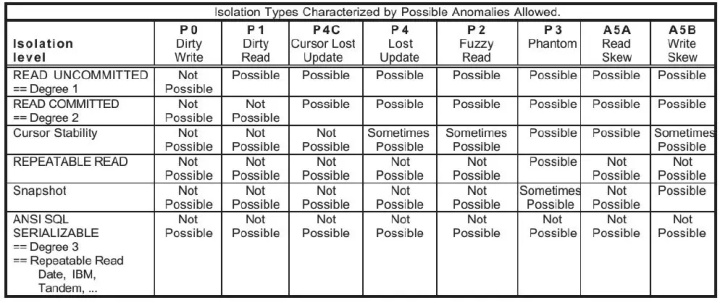
表1-8 所有的异常和隔离级别的关系
说明:
- P0 DirtyWrite:脏写,1.1.4节表 1-3。
- P1 DirtyRead:脏读,1.1.3节表 1-2。
- P4 CCursorLostUpdate:游标丢失更新,1.1.6节表 1-6。
- P4 LostUpdate:丢失更新,1.1.3节表 1-2。
- P2 FuzzyRead:模糊读,即不一致读,1.1.3节表 1-2。
- P3 Phantom:幻象,即幻读,1.1.3节表 1-2。
- A5A ReadSkew:读偏序,1.1.6节表 1-5。
- A5B WriteSkew:写偏序,1.1.5节表 1-4。
- 与隔离级别相关的内容,参见 2.1节。
- 深入探讨三种读数据异常现象
在 1.1.3 节,我们提出了并发带来的三种异常现象,分别是脏读、不可重复读、幻象, 其中幻象又被称为“幻读”。
这一节,我们将以问答的形式,深入探讨与这三种异常现象相关的六个问题。
Q1:异常现象是发生在表 1-2 中的事务 T1 还是事务 T2 ?
换一个提问方式,我们都知道数据库提供了四种隔离级别,那么当三种异常发生的时候,是应该在事务T1 中还是事务 T2 中设置隔离级别以避免数据异常现象的产生?
答:首先,需要区分操作发生的主体。数据库启动多个会话,要想会话之间互不影响,则需要标识哪个是当前会话、哪个是其他会话,然后设置隔离级别。有人认为,这个很简单,每个会话对于其自身就是当前会话。但是,对于数据库引擎而言,他是不知道哪个会话是当前的会话。
其次,需要考虑并发度。对于数据库引擎而言,如果因为数据库引擎不知道哪个会话是当前的会话,所以给每个会话的事务都设置不同的隔离级别,减少各个会话的事务互相影响,则会降低并发度。
所以,在数据库保留一个默认的隔离级别(通常是较低的隔离级别以提高并发度)给每个会话的事务后,如果需要高的隔离级别,就需要在自己的事务中设置想要的隔离级别,以使得本事务不受其他事务的影响。因此,在数据库系统中,我们要想使得事务 T1不受其他事务的影响,则需要在事务 T1内部设置隔离级别,使得本事务 T1不受其他并发事务对事务 T1要读写的数据造成影响。换句话说,就是使得本事务不发生异常现象。回看表1-2 以及对表 1-2的说明,我们可以看到如下内容:
- 脏读现象:……事务 T2发生了脏读异常现象。
- 不可重复读现象:……事务 T1发生了不可重复读异常现象。
- 幻象现象:……事务 T1发生了幻象异常现象。
这个结论看起来有点儿不“美”,即有点不协调,脏读是发生在了事务 T2,不可重复读和幻象是发生在了事务T1。
如果数据异常都发生在事务 T1,则我们可以把事务T1 想象成为“本事务”,事务 T2是其他并发的事务,而我们当前可以操作的(即有权限可以设置隔离级别)只能是“本事务”,其他并发发生的事务也许是其他权限用户建立的会话,我们根本没有权限操作即没有权限去设置他人的隔离级别。
所以,数据异常现象,一定是发生在本事务当中的。我们统一以事务 T1 为本事务(也称为“主事务”),观察本事务和其他并发事务之间因读写操作的先后次序不同而造成的不同的数据异常。因此,我们修正表 1-2 的内容如表1-9 所示。
表 1-9 修正后的SQL 标准定义的三种读数据异常现象
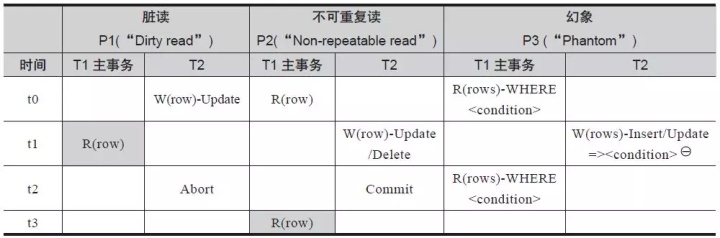
“W(rows)-Update/Insert =><condition>”表示更新和插入操作的行满足“<condition>”。
对于 Q1 问题的回答,依据表 1-9,数据异常现象发生在表 1-9 中的主事务 T1 中。其实,如上修改是为了明确并发事务的数据异常现象发生在哪里。即研究别的事务对于本事务的影响,而不是讨论本事务对别的事务的影响。
对于数据库引擎的编码实现,就是在一个会话中考虑本会话(主事务对应的会话)因不同的隔离级别(在主事务中设置的隔离级别)在发生冲突后而产生什么样的动作(可继续执行本事务内的后续 SQL 还是直接回滚掉本事务)。所以,请注意,动作发生的主体,一定是主事务。而且,异常是发生在主事务的读操作这样的动作上(指三种读异常)。
Q2 :从表 1-9 中看,对于脏读现象,写操作是事务T2 执行 UPDATE 引发的,那么, 事务 T2 的写操作可以是删除(DELETE)或插入(INSERT)吗?
答:脏读,强调的是主事务读取了一个不存在(因回滚而不存在)的数据。
如果事务 T2的写操作是删除操作,在 row这行数据被删除后,事务 T1不可能在后面的时间点 t1上读到同一个 row(SQL标准中特意强调了“thatrow”,参见 1.1.3节);因此脏读现象中“事务 T1一定可以读到同一个 row”是不能满足的,因此,脏读中的事务T2 的写操作不可能是删除。
如果事务 T2 的写操作是插入操作,在row 这行数据被插入后,事务 T1 能在后面的时间点上读到同一个 row(SQL 标准中特意强调了“ that row ”);因此脏读现象中事务 T1 一定可以读到同一个 row 的条件是被满足的,因此,脏读中的事务T2 的写操作可以是插入。
Q3:对于不可重复读现象,事务 T2 的写操作是否可以是插入操作?
答:对于事务 T2 的 W(row) 操作,row 是一个已经存在的行,这表明是在一个存在的特定对象上进行的操作,所以不可能是插入操作。
Q4:不可重复读和幻象有什么区别?
答:首先,这两种异常,对于主事务 T1 而言,都是先读取了数据,之后因事务 T2“写” 了数据而事务 T1 再次读取数据的时候,发生了异常。但是,如表1-9 所示,不可重复读对于事务 T1 读取的是一个存在的确定的一行数据(意味着这行数据是存在的数据),这个行数据本身被事务 T2 使用更新或删除操作而改变;而幻象对于事务 T1 读取的是满足条件“ <condition> ”的多行数据(意味着“<condition> ”是一个范围查找,结果集不确定),所以从次读取数据的操作的角度看,前者是读取特定的多行,后者读取的是多行但可能 不确定。不过,对于所读的数据而言,由此可以产生一个新的问题,参见Q5。其次,这两种异常,对于事务 T2 而言,都是“写”数据,但是写操作的具体动作不同。如表 1-9 所示,不可重复读对于事务 T2 的写操作是更新或删除操作,而幻象对于事务 T2 的写操作是插入(插入的新数据满足条件)或更新(使不满足条件的数据在更新后满足条件)操作。
第三,不可重复读和幻象大的区别就是前者只需要“锁住”(考虑)已经读过的数据,而幻象需要对“还不存在的数据”做出预防。
Q5:对于幻象现象,事务 T2 的写操作是否可以是更新操作或者删除操作?
答:对于幻象现象中事务 T2 的 W(rows) 操作,如果操作是一个更新或删除操作,则表明这样的操作等同于(相似但不完全一样,区别参见 Q6)不可重复读(即是在多个行数据上进行更新或删除,即在多个行数据上批量化重演了不可重复读现象)。
如表 1-10 所示,比较不可重复读和幻象现象。如果我们认为幻象现象中的事务T2 可以是更新或删除操作,则幻象就等同于不可重复读。实际上,幻象是不可重复读的一个特例,对于不可重复读现象,可以扩展其“ R(row)/W(row) ”的概念为“ R(rows)/W(rows) ” 即读写多行(实则是扩展 1.1.3 节 SQL 标准提出的不可重复读的定义),即对多行的不可重复读。只是 ANSI SQL 标准着眼于在单行上定义不可重复读,本节扩展的定义着眼于在多行上重复单行上定义的不可重复读(而编码实现的实践中,数据库引擎是对多行数据使用相同的方式进行处理的)。
表 1-10 幻象的写操作改为更新则等同于不可重复读

另外,幻象异常现象中的操作都带有“<condition> ”,而不可重复读现象中则没有“<condition> ”, 这 可 以 把 不 可 重 复 读 变 形 为 类 似“R(rows)-WHERE<true> ”, 即 “ <condition> ”相当于“ <true> ”。但是, 幻象的定义, 强调的是在特定的行(元组) 被操作后,又有新的行被其他事务操作而产生,所以,我们可以重新校正表 1-9得到新的表1-11,发生变化的内容使用深色背景表示,幻象现象中事务T2的操作是插入或更新。
从表 1-11 可以看出,不可重复读现象中事务 T2 着眼于对现有数据进行操作;而幻象现象中事务T2 着眼于对新增(或不在锁定范围内已经存在的数据上做更新 / 插入后而得的数据满足了谓词条件)数据。这其实正是Q4 的答案。
Q6:表 1-11中,不可重复读现象中的事务 T2在 t2时刻执行“ Commit”或不执行“Commit”会有什么差别吗?或者对于幻象现象,事务T2在 t2时刻没有执行“Commit”,这一点与不可重复读有差别吗?
答:对于这个问题,我们暂时不做回答,请读者先行思考。在我们讨论了并发控制相关的多种技术后,我们在 2.2.6 节再深入探讨这个问题。
表 1-11 第二次修正后的 SQL 标准定义的三种读数据异常现象

