随着业务数据量级的上升,理想汽车的物联网场景业务对数据存储性能的要求不断提高。我们内部团队也在积极探索不同的数据库与不同场景的佳实践匹配,本文将分享TDengine在我们的物联网场景的落地经验。
首先我们来了解一下业务场景。
一、业务场景介绍
我们有信号上报业务,需要将标记时间戳和采集点的信息,通过云端写入到后端数据库中,有一定的聚合查询需求。这是典型的高并发插入场景,写多读少。目前的压力为7万的写入QPS,预计未来3年将达到20万以上。
我们之前的系统用的是MongoDB。业务存储放在MongoDB,后来因为MongoDB的局限性,我们将业务迁移到了TiDB,方便进行扩缩容。
迁移到TiDB之后,在目前使用百度云SSD虚拟机的情况下,TiDB集群纯写入性能并不能达到我们的业务期望预期(HTAP场景数据库对纯高并发写入支持不好,与该业务场景的适配性不高),需要不断的资源扩容。整体来看,TiDB适合TP或者轻AP场景,而且TiDB对硬件配置要求很高。对于时序数据,写入用TiDB的话性价比很低。另外对业务有入侵性,底层库表要按照月份来建表,还要针对每个采集点打上标签。一次性大批量写入场景也不太适配。
总的来说,当前架构主要存在如下痛点和新需求:
持续高并发写入,带有tag,时间戳有时会乱序;
业务数量级膨胀极快,需求无感知scale-out;
对基于时间戳范围的聚合查询有一定的需求;
因为数据量非常大,所以需要支持数据压缩,降本增效;
希望可以不用针对月份数据进行分库分表,需求TTL机制;
希望可以针对采集点单独建表;
希望支持批量数据写入,且业务期望写入延时较低。
两级存储结构,数据插入性能高,资源利用率高;
对时序数据压缩率极高;
针对采集点单独建表,匹配业务场景;
支持大批量数据写入;
无感知的scale-out和scale-in;
支持TTL。
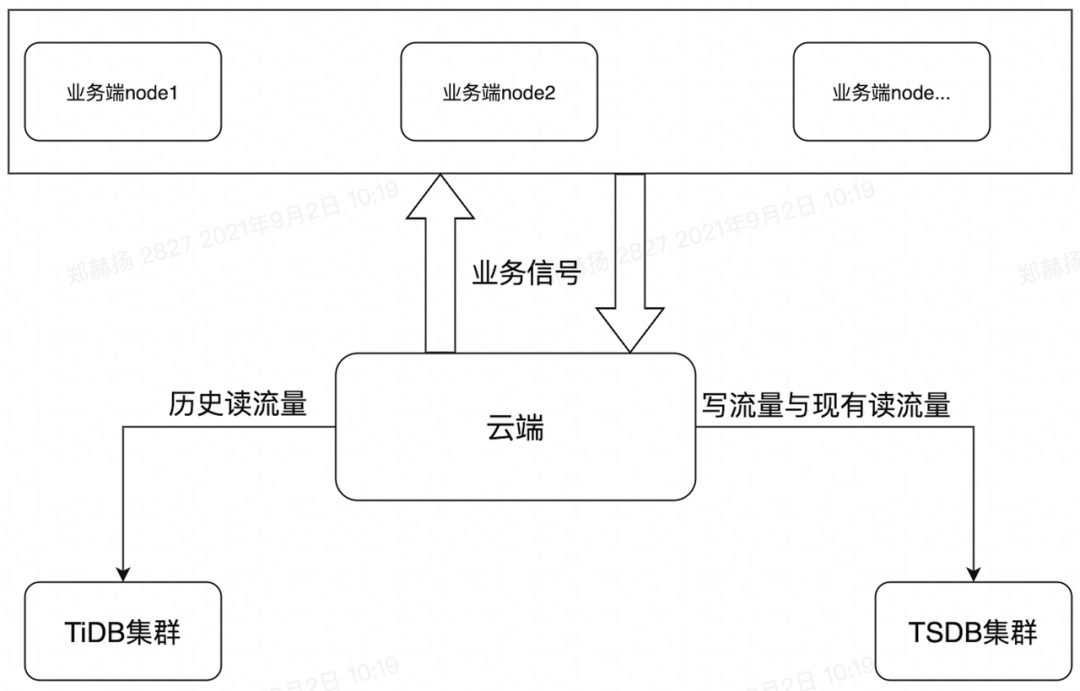
2.1 迁移过程
先切写流量到TDengine,历史读流量在TiDB的方案
逐步将历史数据格式化导入到TDengine
部署方案: 采用域名—>LB—>firstEP+SecondEP的方式,具体可以参
考《TDengine容器化部署的佳实践》这篇博客。
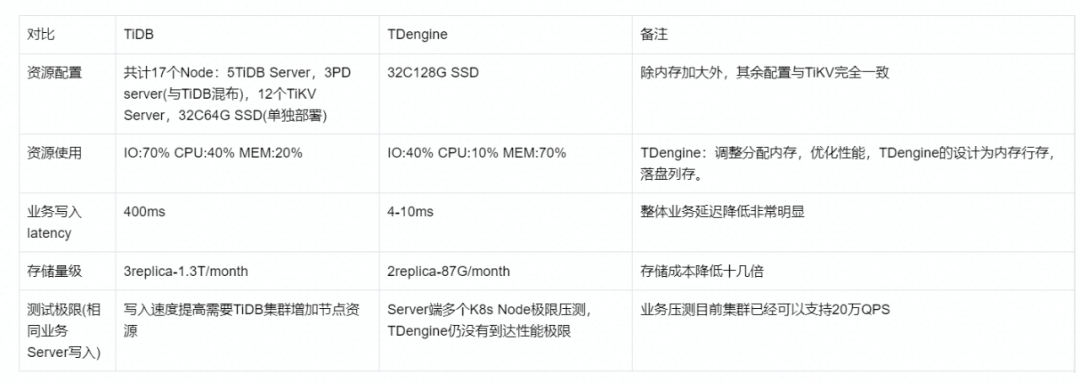
非常的时序数据库,性能比InfluxDB要强出许多,两级存储架构
设计(行存与列存)很棒;
适配物联网的大数据存储场景(TDengine从超级表概念的引入到架构
设计,决定了其适配的场景);
非常低廉的机器使用成本;
方便的弹性扩缩容,引入了firstEP机制;
对聚合类查询的速度支持也很快;
有TTL和标签机制,对业务透明。
监控指标的完整性有待提高,只有基础的监控指标,性能排查还要看
日志,写入延时要通过业务监控去看;
周边生态工具支持待完善,对于运维管理人员不是很方便;
应用端和客户端要求强一致,如果升级版本,则客户端也要一起升级,重新打包进K8s node,滚动批次更新多个客户端,这点不是很友好;
各类报错信息还需要进一步完善,对用户更友好一些,方便排查问题;
Go的SDK不支持prepare statement(新版本已经支持——编者注);
账号隔离支持有待完善,为了避免互相影响,只能从业务上约束,或者一套业务一个集群。
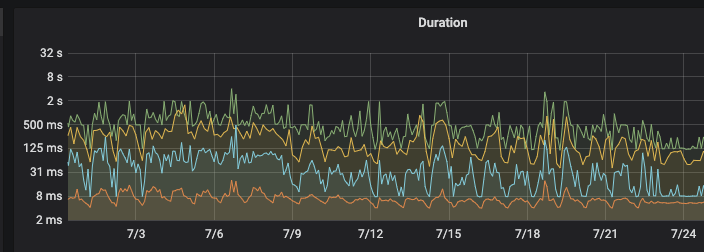
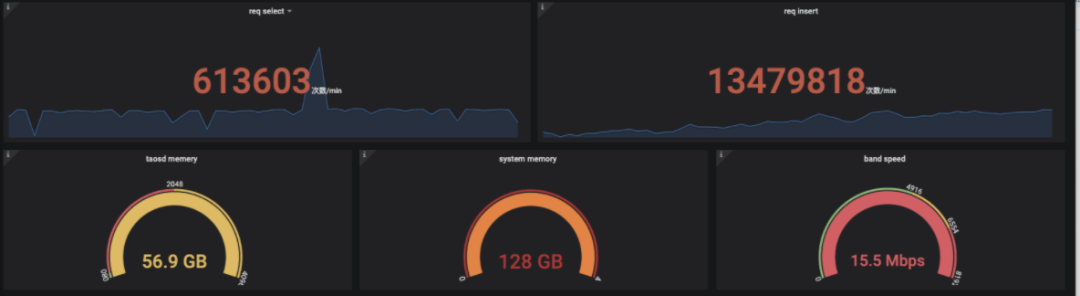
来源 https://www.modb.pro/db/168852
