今天和大家分享的标题是《新一代PB级分布式HTAP数据库》,我加了个副标题为:Greenplum 能做什么?过去,我们做的分享大多是从产品的角度分享 Greenplum 有哪些特性。后来接到一些反馈,很多听众都表示在听到这些特性后,更希望知道将这些特性综合起来可以对业务有哪些支撑。因此今天重点和大家分享 Greenplum 能做什么,并引出背后需要什么样的技术支撑。
Greenplum 是个关系型数据库,支持完善的 ACID,HTAP 是这几年比较流行的方向,是指 Transaction 和 Analytics 混合处理在一个系统里。分布式是指一个集群有很多节点,每个节点处理一部分的任务,从而实现速度更快更高可用的处理。PB 级是指 Greenplum 可支持的数据量,我们已经有大量的客户在生产集群里使用 Greenplum 支持 PB 级数据量。
在标题中,我使用了“新一代”的字样。有人也许会提出疑问,Greenplum 是 MPP 架构,这个架构从 80 年代就有人研究,为什么会用新一代来形容。其实 MPP 只是 Greenplum 的骨架特点之一,经过多年的发展,Greenplum 加入很多的新技术,可以处理 HTAP 场景,具有结构化数据、半结构化数据、Text、GIS 的支持能力,可以实现数据库内嵌的机器学习能力。
关于什么叫做新架构:可以和大家交流一个关于列存( Column Storage )的故事:大数据处理使得列存非常流行,但是大家知道不知道谁早做的列存?实际上世界上款关系型数据库 SystemR( 上世纪70年代初开发 )版本实现时,数据存储就是现在我们说的列存。版做完后,总结了设计的一些缺陷,其中包括使用列存。如今列存成为了用来解决大数据的主流技术。很多时候,创新都会用一个已经被发明的老技术来解决新时代的问题。
接下来和大家主要讲一讲 Greenplum 能做什么。首先是数仓、OLAP、即席分析。这三个词很多时候指的是一回事。细抠的话各自也有不同的侧重。
数仓是一种数据库类型,用来做 BI 和复杂查询处理,强调的是来自各种数据源的历史数据的分析,产生商业智能( BI );
OLAP 是一组操作,例如 pivot/slice/dice/drilling/cube 等。( https://stackoverflow.com/questions/18916682/data-warehouse-vs-olap-cube )强调的是处理;
即席分析:强调的是查询时 ad-hoc 的,不是预先设计好的 SQL 查询,强调需求和解决问题的动态性,不是静态需求;
数仓、OLAP、即席分析,这三个词有各自的侧重点,但总体上都是指数据分析。一半以上 Greenplum 客户在这种场景下使用 Greenplum,解决的是数仓问题、在线分析问题和即席查询问题。 这个场景也是 Greenplum 创始团队2004年前后创业时主攻的市场。经过15年的研发和打磨,Greenplum 在该领域具备了极大的优势,在全球范围内有良好的口碑。

口碑和优势并不是靠我们“王婆卖瓜自卖自夸”,而是来源于客户对产品的信赖和支持。这是 Gartner 2019年发布的报告。我们可以看到 Greenplum 在经典数仓领域排名第三,前两名是 Teradata 和 Oracle,他们都经过长达40多年的发展,相比之下,Greenplum 还处于青少年时期,发展更为快速。 此外在实时数仓领域,并列排名第4。取得这样的认可,需要很多方面的因素,除了技术,还有服务、支持、品牌等。但技术肯定是重要一环。接下来,我们来看看,从技术上,Greenplum 是如何来解决数仓和 OLAP 问题的。
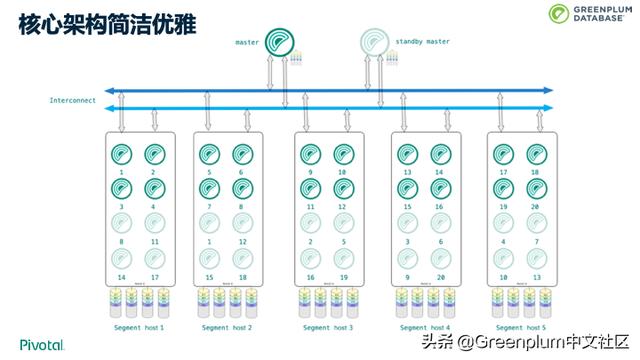
首先,我们来看一下 Greenplum 的核心架构。上图是一张典型的部署拓扑图。上面是 Master,下面都是 Segment,Master 和 Segment 之间通过网络进行高效通讯,我们称为 Interconnect。
Master:存储用户元数据,负责对整个集群的调度、监控和管理控制
Segment:存储用户数据,执行master分配的任务
Interconnect:实现数据在各个节点间的传输
整个架构可以做到线性拓展,这里我们看到 Greenplum 的核心架构特色:MPP shared nothing。 MPP 是大规模并行处理,shared nothing 是无共享。
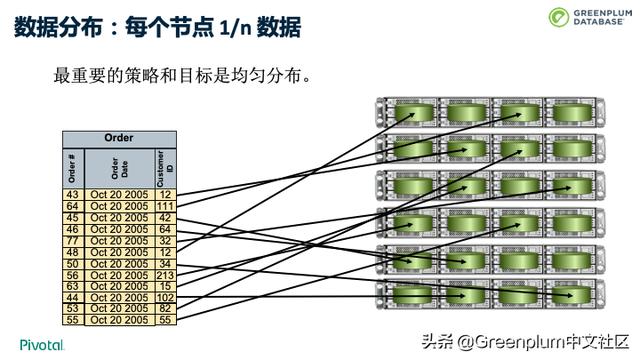
在这种架构下,数据要如何存储呢。在 Greenplum 这种分布式数据库中,数据根据各种策略分布到不同节点上。Greenplum 提供了多种分布策略,包括哈希、随机,6.0 还提供了复制表的技术。 不管是哪种技术,重要的策略和目标是做到数据的均匀分布。DBA 或者开发人员要选择合适的分布键,使得每个节点分布 1/n 数据,避免出现短板效应,如果找不到一个合适的分布键,也可以考虑使用随机分布。
这样可以做到两重加速:
每个节点只有 1/n 数据,速度快
N 个节点并行处理,速度快
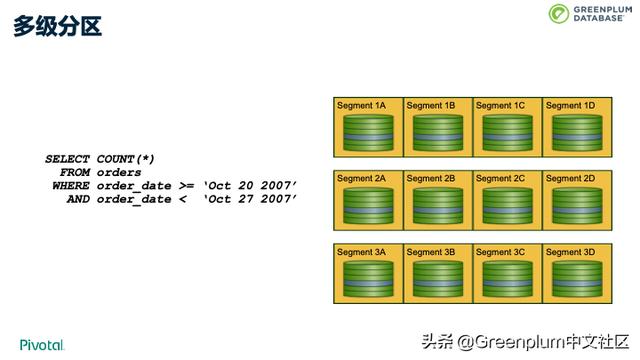
数据均匀分布考虑的是不同节点之间数据分布的问题。每个节点上,Greenplum 还支持分区技术,并支持多级分区。通过多级分区,可以将数据进一步在每个 segment 分开,底层会使用不同的文件保存不同的分区。 核心目的还是尽量降低每次 SQL 处理要扫描的数据量。 上图的例子中的查询,如果我们是按月做的分区,就可以只读2007年10月的数据,而不需要关心其他月份的数据。这样的话,磁盘 IO 会大幅降低,处理速度、性能也会有很大的提升。

Greenplum 支持多模存储/多态存储。Greenplum 可以对同一张表的不同分区采用不同的存储模式,常用的划分标准是根据时间划分分区。比如上图的例子中,老的数据,也就是不常访问的数据可以使用外部表的模式,中间的数据可以使用列存储,频繁更新或者访问的数据可以用行存储。多态存储对用户透明。

数据有了分发和存储,也得支持查询。Greenplum 研发团队于2011年自研的优化器——ORCA,是Greenplum 开源的子项目,也是 Apache 的顶-级项目。 ORCA 是基于 Cascade 架构,基于 Cost 模型的优化器。 ORCA 的主要用途是解决一些 OLAP 中存在的复杂的查询。ORCA 可以很好的应对包括10+表 join、关联子查询、CTE、分区动态裁剪等复杂查询。在这些场景下,ORCA 查询速度比传统的优化器有几十倍到几百倍的性能提升。

有了优化器,接下来就要谈谈查询的执行。上图中有两张表:t1 和 t2,它们各有6条数据,分布键都是c1,如图所示均匀分布在三个节点上。查询 SELECT * FROM t1 JOIN t2 ON t1.c1 = t2.c1 的执行计划如上图右半部分所示,每个节点上单独执行 JOIN 并将 JOIN 结果发送给 master。这种场景是 Greenplum 擅长的场景之一。
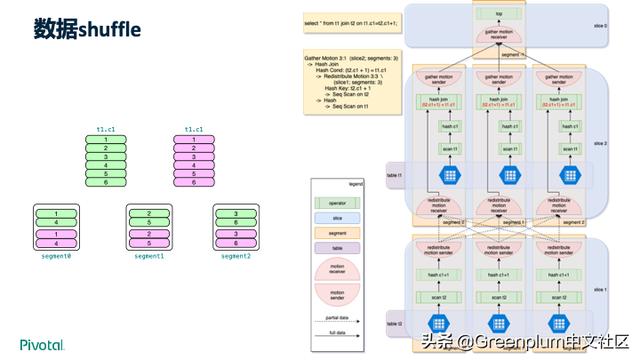
但并不是所有的查询都容易处理,比如上图的例子中,需要通过数据 shuffle 来实现数据在不同节点间的动态传输。Greenplum 实际用户有更多、更复杂的使用场景,Greenplum 作为企业级数据库都能很好的支持。

除了上面介绍的核心技术,Greenplum 还有很多其他的技术,对数据库的性能,稳定性、和高可用有很大的支撑,上图列出了其中的一部分。
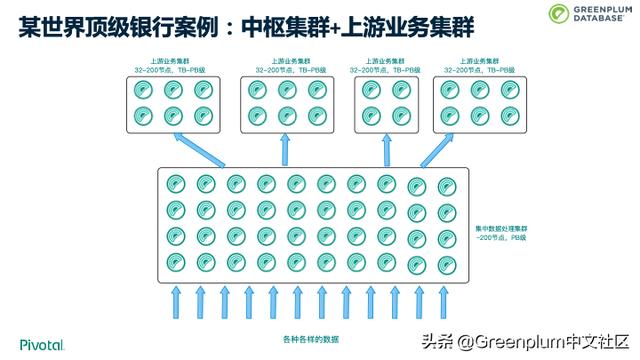
接下来,我们来介绍一个 AP 密集型的案例。 某大型银行,采用 Greenplum 作为数据处理的中枢,所有业务数据都经过 Greenplum 中枢集群的处理,处理后的结果分发给不同的上游集群。 中枢集群数据量 PB 级,节点数达 200 个;上游业务 Greenplum 集群有二三十套。支撑了该银行的大量核心业务。之前该银行主流技术是 Teradata,现在使用了几十套 Greenplum 集群替换了之前的 Teradata 集群。

随着数据量增大,一个痛点出现:传统的 OLTP + OLAP + ETL 方式过于复杂,效率低,费用高。客户对混合负载的需求越来越大。这里混合负载和 HTAP 大体指一回事,但是也有些微差别:混合负载通常强调是大查询+小查询,通常只读为主;HTAP 则强调小查询不只是读,而且有大量的 Insert、Update 和 Delete。Greenplum 早期版本主要为 OLAP 场景而优化,随着客户需求越来越大,慢慢很多人开始使用 Greenplum 做混合负载。从客户反馈来看,大约有 30% 以上 Greenplum 用户使用 Greenplum 处理混合负载,而且呈现逐年增长趋势。从今年9月份发布的 Greenplum 6 开始,Greenplum 对 OLTP 业务处理能力大幅提升。
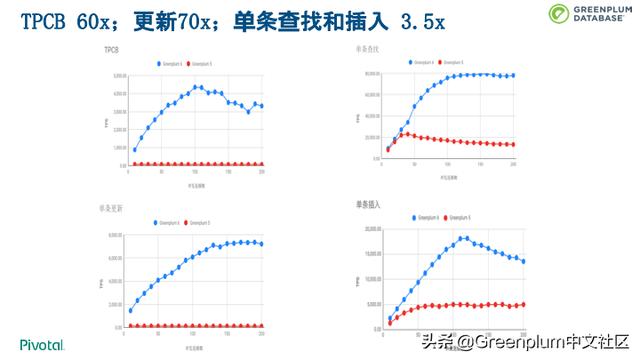
上图是我们在 Greenplum 6 发布时做的性能评测,Greenplum OLTP 性能大幅提升。具体评测内容请查看链接( 「实战系列」Greenplum 6 OLTP (TPC-B) 性能提升60倍 )。下面列出了常见 TP 查询的 tps,从这个数据看来很多 TP 业务完全可以使用 Greenplum 6 支撑。这个测试是 Greenplum 6.0 刚发布时做的,用新的 Greenplum 6.3 跑测试,结果比这个数据还要好。
TPCB:4500 tps
SELECT:8万
INSERT:1.8万
Update:7000 tps
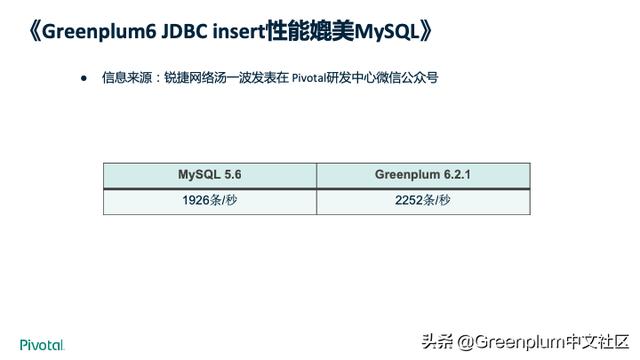
上图是社区的一位小伙伴在社区的帮助下作的一个 Greenplum 6 和 MySQL 的 JDBC insert 测评,在优化后得到的上图的结果。Greenplum 6 可以承担越来越多的 TP 业务。

Greenplum 性能提升归功于一系列 OLTP 优化技术,包括全局死锁检测、锁优化、事务优化、复制表、多模存储、灵活索引、OLTP 友好的优化器、多个版本内核升级等。
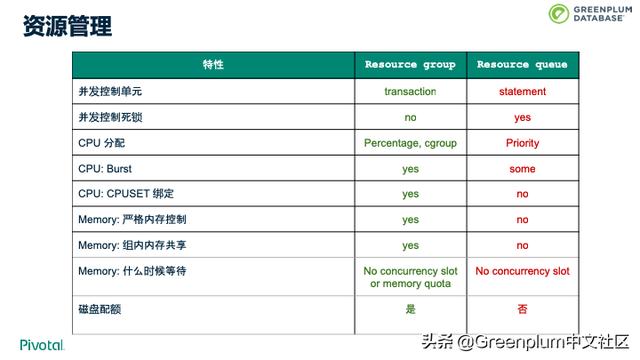
由于有各种查询的存在,就可能存在资源竞争的情况。为了解决这个问题,我们引入了资源组,并在 Greenplum 6 中持续增强。资源组可以很好的进行资源管理,并具有上图的各大功能特性。

接下来我们来讲一个案例。很多企业会像上图中采用很复杂、并且成本很高的架构:用 TP 系统来支持事务型业务,用 AP 系统支持 AP 业务,再用 ETL 将数据从 TP 系统中导入进 AP 系统中。而通过 Greenplum 6 这样的 HTAP 数据库,一套数据库便可以同时支持 AP 和 TP 业务。Greenplum 从2019年9月份发布至今,全球已有20多家客户开始测试,并有数个客户开始应用于生产系统。

5版本时,我们发布了Greenplum Kafka Connector,在6版本中,也进行了大幅提升。GPKafka 可以将用户导入 Kafka 的数据高效并行的导入 Greenplum 中。
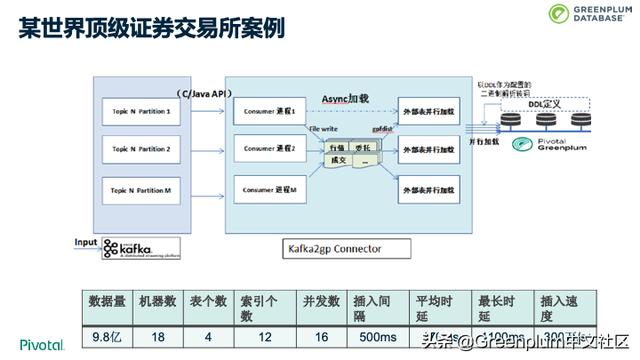
这是一个世界顶-级证券交易所的案例。在做 POC 时,客户要求每秒从 Kafka 导入 100万数据到Greenplum,每秒提交一次。终结果是 Greenplum 可以做到每秒300万条数据,数据量是9.8亿,平均时延是170毫秒。
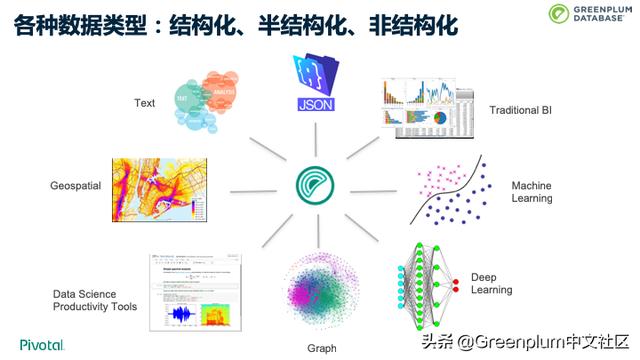
Greenplum 可以处理各种数据类型,包括结构化,及JSON、XML 这种半结构化数据和 Text 这种非结构化数据,还有地理信息数据等。除此之外,还可以做到 in-databse 机器学习,图计算等。

数据融合也称数据虚拟化、数据联邦,指不用移动数据,可以分析远程数据源的数据。Greenplum 的数据融合技术支持 ORACLE、MySQL、PostgreSQL、Hadoop、HIVE、HBASE 等。

Hackday 是 Greenplum 团队的传统活动:这一天可以“不干活”,选择你感兴趣的一个问题组织一个小团队搞一搞。上图列出了一次 Hackday 的题目。在 Greenplum 中可以用下图中的一条 UDF 来解决。
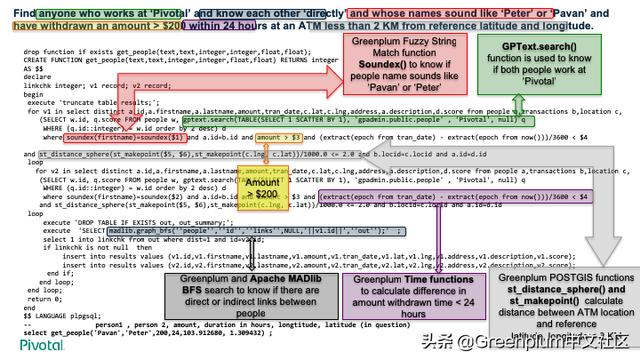
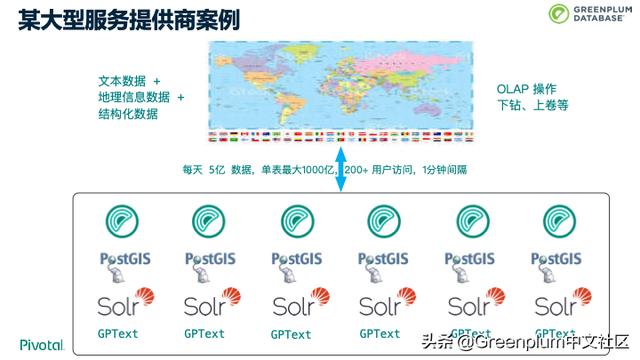
下图是一个做国家安全的大型服务提供商的案例。用户的地图界面中可以做一些 OLAP 操作,包括下钻、上卷等。在此案例中有文本数据、地理信息数据、和结构化数据。每天5亿数据,单表大1000亿,用了一个满配的 DCA 一体机,单纯文本索引达 11TB。同时有200+用户访问,数据要求在1分钟之内进入系统。
大数据分析近几年有一个新的发展趋势,高-级分析下沉。之前的技术是拉数据到分析应用节点,需要抽样和数据移动。为了解决这两个问题,避免数据移动,提高模型精度,机器学习开始下沉到数据库内实现。早的工业实现之一是 Apache MADLib。MADLib 是 Greenplum 2011年联合加州大学伯克利分校、威斯康星大学、布朗大学等一起合作的项目,目前已经成为 Apache 的顶-级开源项目。下图是MADLib的架构。
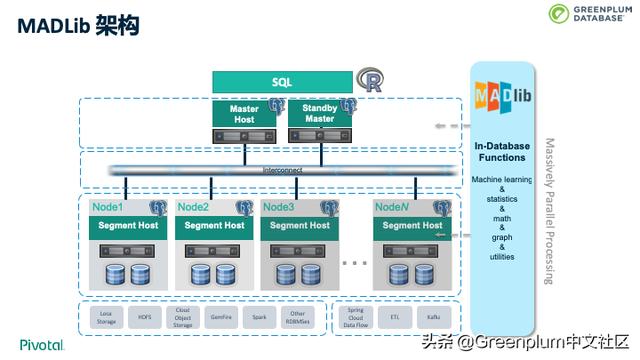
下图是MADLib支持的一些函数。

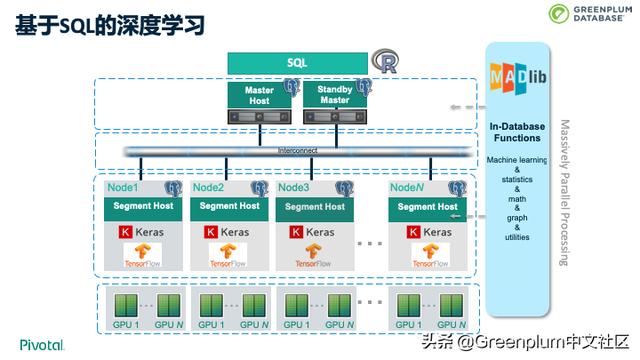
2019年年初,我们开始进行一个新的尝试,用 MADLib 来支持 AI 深度学习,在每个 Segment 上,通过 MADLib 架构支持 Keras 和 TensorFlow,这样就可以使用挂在节点上的 GPU 的资源实现深度学习。
下面是一个跨国传媒和娱乐公司关于机器学习的案例。
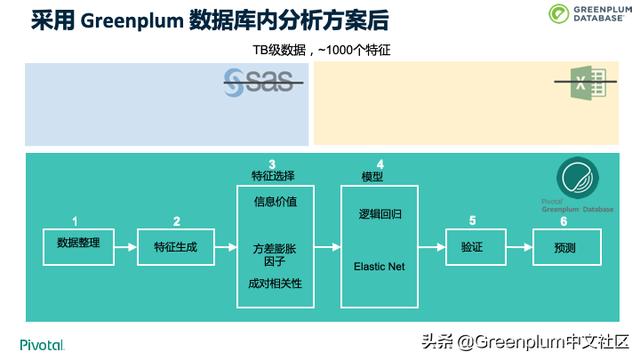

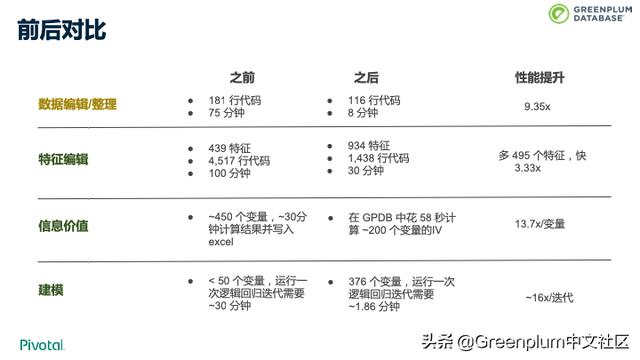
采用 Greenplum 数据库内分析方案后,性能上达到了十倍的提升。
后我们简单聊一下现代 SQL vs 92年的 SQL。下图详细说明了 SQL 特性、SQL 标准和 Greenplum 对应的支持的版本。 当把上面这些特性有效结合在一起的时候,可以实现的功能非常强大。
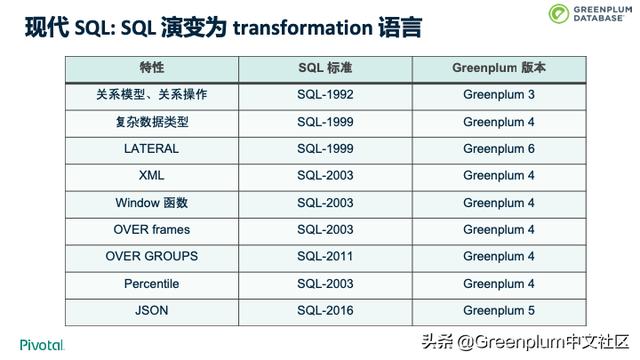
我们来看一个例子。
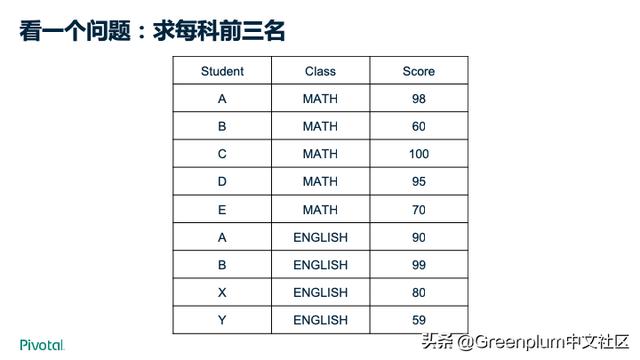
写出上图的解决方案,有很多方式。

接着我们考虑一下以下多种因素。然后再考虑下你的方案是否可以很好的支持这些情况。

但是如果用成熟的数据库,几行 SQL 便可以实现。并且不需要考虑上面提到的各种问题带来的挑战。

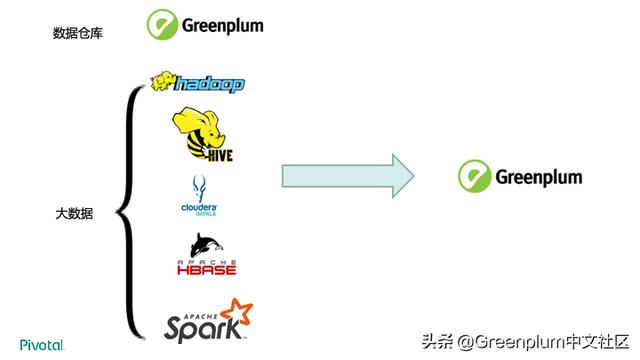
综上所述,Greenplum 是一个成熟的、开源的企业级的 HTAP 数据库,且支持 Apache 协议,为全球来自各行各业的大量大型客户的生产系统支撑关键数据分析业务。数仓要求对大量数据进行处理,对应“Volume”;流数据要求对新产生的数据快速处理,对应“Velocity”;集成数据分析要求支持各种各样的数据类型,对应“Variety”。这也是大数据的3V,Greenplum 是新一代大数据处理技术。和传统的 Hadoop 技术栈相比具有诸多优势,譬如性能更好、更简单易用、标准支持更好等。

目前很多数据中心将数据分析分为两类:数据仓库和大数据。数仓采用 Greenplum 已经非常流行,大数据部门也开始越来越多的采用 Greenplum。这种新型的架构可以大大简化数据分析的复杂度,提高数据分析速度和时效性,避免在各种数据产品间频繁的搬动数据,降低运维人员的工作负载,提高知识共享度。节省成本且效率提升。
End~
本文来源:https://blog.csdn.net/weixin_39621794/article/details/111644503
