Hadoop MapReduce很好地满足了用户的批处理需求,但由于渴望开发更灵活的大数据工具来进行实时处理,催生了大数据宝贝Apache Spark。Spark通过其强大的功能和快速的数据处理速度使大数据世界着火了。根据*afe的一项调查,有71%的人具有Spark的研究经验,而35%的人正在使用它。该调查显示高增长对Apache Spark的认识和在企业中的采用。在迭代机器学习算法和交互式数据挖掘算法的快速数据处理方面,它已经接管了大数据室中的Hadoop。
Apache Spark的吸引力中心在于快速的数据处理速度及其处理事件流的能力。这些功能使开源超级Apache Spark成为大数据世界的甜心。全部归功于主要的抽象-弹性分布式数据集,这些数据集使Apache Spark成为许多企业的大数据宠儿。Spark RDD是Apache Spark生态系统的基础,学习Spark-掌握Apache Spark RDD的概念非常重要。在这篇文章中,我们将学习如何使弹性分布式数据集成为Apache Spark框架的灵魂,使其成为批处理分析的高效编程模型。
什么是弹性分布式数据集(RDD)?
根据原始论文“弹性分布式数据集:内存群集计算的容错抽象”,Spark中的RDD可以定义如下:
弹性分布式数据集(RDD)是一种分布式内存抽象,可让程序员以容错的方式在大型群集上执行内存中计算。
根据org.apache.spark.rdd.RDD的scaladoc:
弹性分布式数据集(RDD)是Spark中的基本抽象,表示可以不变地进行操作的元素的不变分区集合。
弹性的
意思是它通过沿袭图提供了容错能力。沿袭图跟踪调用动作后要执行的转换。RDD沿袭图有助于重新计算由于节点故障而导致的任何丢失或损坏的分区。
分散式
RDD是分布式的-意味着数据存在于集群中的多个节点上。
数据集
具有原始值的分区数据的集合。
Apache Spark允许用户像其他任何变量一样考虑输入文件,这对于Hadoop MapReduce是不可能的。
Spark RDD的功能
一成不变的
他们只读抽象,一旦创建不能改变。但是,可以使用诸如map,filter,join,cogroup等转换将一个RDD转换为另一个RDD。RDDSpark的不可变性质有助于实现计算的一致性。
分区的
Spark中的RDD具有包含分区的记录的集合。Spark中的RDD分为小的逻辑数据块-称为分区,当执行操作时,将为每个分区启动任务。RDD中的分区是并行性的基本单位。Apache Spark架构旨在自动确定RDD可以划分为多少个分区。但是,在创建RDD时可以指定RDD可以划分的分区数。RDD的分区分布在网络中的所有节点上。
LAZY
RDD以惰性方式计算,因此可以对转换进行流水线处理。除非调用触发转换执行的操作,否则不会转换RDD中的数据。
坚持不懈
RDD的持久性使其适合快速计算。用户可以指定要重用的RDD,并为其选择所需的存储-是否要将其存储在磁盘或内存中。RDD是可缓存的,即它们可以将所有数据保存在所需的持久性存储中。
容错能力
Spark RDD将所有转换记录在一个沿袭图中,以便每当分区丢失时,可以使用沿袭图来应答该转换,而不必跨多个节点复制数据(例如在Hadoop MapReduce中)。
平行
Spark中的RDD并行处理数据。
已输入
Spark RDD具有各种类型-RDD [int],RDD [long],RDD [string]。
Spark RDD解决的Hadoop MapReduce局限性
Quora用户Stan Kladko – Galactic http://Exchange.io的联合创始人,解释了Spark RDD以非常简单的方式解决Hadoop MapReduce的局限性,读者一定会喜欢他的解释-
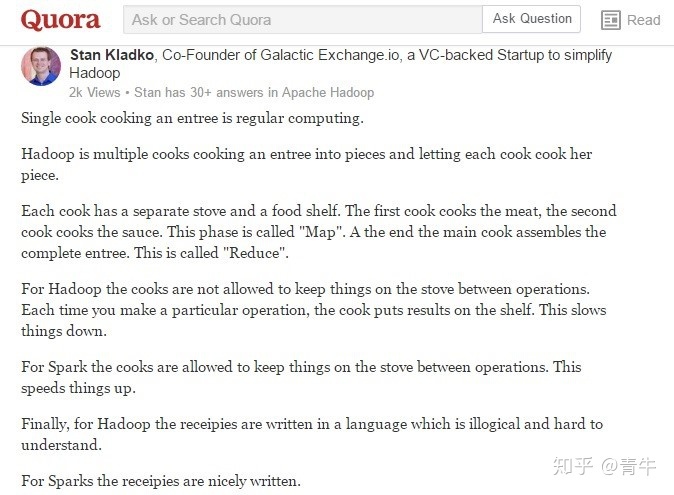
复杂的应用程序和交互式查询都需要Spark RDD提供的高效数据共享原语。
映射任务和约简任务之间存在同步障碍
在Hadoop MapReduce中,映射和reduce任务之间始终存在同步屏障,因此数据应持久保存到磁盘上。尽管这种设计有助于在出现故障时恢复工作,但它并不能以完整的形式利用Hadoop集群的内存。Spark RDD使用户可以透明地将数据存储在内存中,并仅在需要时才将其持久存储到磁盘上。因此,不存在任何同步障碍会降低数据处理速度,从而使Spark执行引擎非常快。
Hadoop MapReduce的数据共享速度很慢-Spark RDD解决了此问题。
Hadoop MapReduce无法处理迭代(机器学习和图形处理任务)和交互式(在同一数据子集上运行即席查询)应用程序。如果将这两个应用程序的数据都保存在内存中,则可以在很大程度上提高性能。在迭代分布式数据处理中,需要使用机器学习算法(例如K-Means聚类或Logistic回归或Page Rank)在多个作业上处理数据,在多个作业之间共享或重用数据是很常见的。
Hadoop MapReduce上的迭代操作
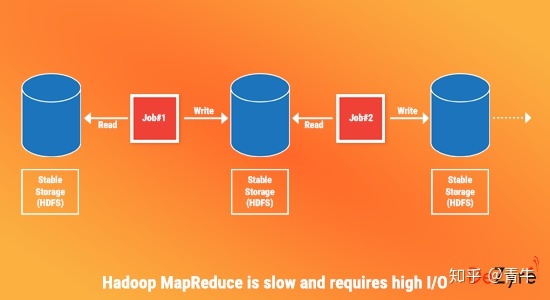
Hadoop MapReduce具有容错能力,但是很难在多个作业之间重用中间结果。Hadoop MapReduce中的数据重用或共享非常缓慢,因为数据需要存储到中间稳定的存储中,例如Amazon S3或HDFS。这需要多个IO操作,序列化和数据复制,从而减慢了作业的总体计算速度。
假设有一个Web服务器日志需要针对特定的错误代码进行分析。您使用正则表达式编写Hadoop MapReduce代码,以使用grep查找特定的错误代码。在服务器上执行Hadoop MapReduce代码时,将返回一组包含grepped error_code的文件,集群将关闭,所有检索到的文件将存储在Hadoop MapReduce代码中提到的Amazon S3位置。您查看检索到的文件,并注意到您需要编写另一段Hadoop MapReduce代码来检索更多文件。这将需要额外的时间来携带这些文件,对其进行处理并返回所需的结果。
下图演示了MapReduce中的迭代处理,该过程显示了Hadoop MapReduce中处理所需的中间稳定存储,这会产生额外的开销-
Spark RDD上的迭代操作
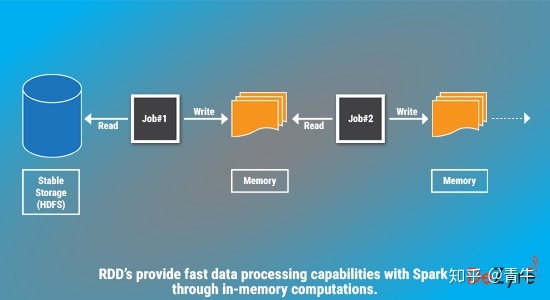
弹性分布式数据集通过在内存中存储数据来实现容错分布式内存处理,从而解决了这个问题,以便用户可以重新查询数据子集。下图描述了RDD如何将中间输出存储在分布式内存中而不是稳定存储中,从而使执行速度比Hadoop MapReduce更快-
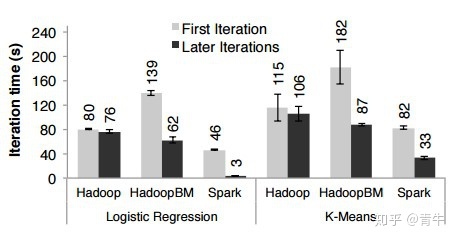
在需要查询大量数据的迭代应用程序中,Spark中的RRD的性能比Hadoop MapReduce高出20倍。下图显示了使用Hadoop和Spark-的迭代式机器学习算法的性能评估
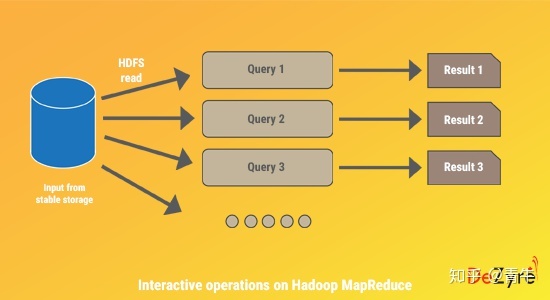
MapReduce上的交互式操作
在交互式数据挖掘应用程序中,用户需要在同一数据子集上运行多个临时查询。在Hadoop MapReduce中,运行交互式即席查询效率不高,因为每个查询都会在稳定的存储上执行磁盘I / O,这很可能会超过交互式应用程序的整体执行时间。
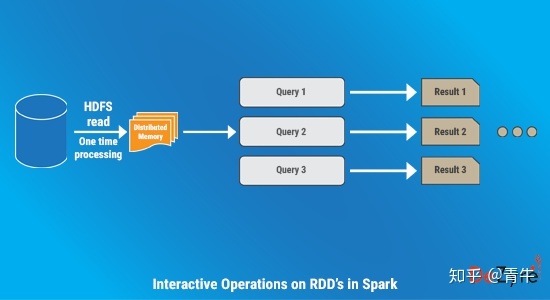
Spark RDD上的交互式操作
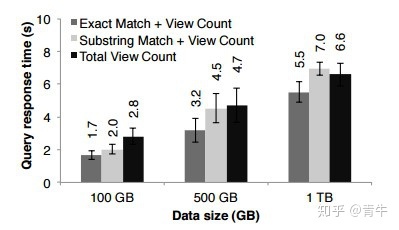
通过查询1 TB的数据集(延迟时间为5到7秒),对Apache Spark进行了交互式使用评估。通过将数据保留在内存中以缩短执行时间,用户可以连续对同一数据子集运行不同的查询。下图描述了如何在Spark内存中执行交互操作。
下图显示了使用Hadoop和Spark-的交互式应用程序的性能评估
Hadoop MapReduce在Spark RDD上的局限性摘要
- Hadoop MapReduce使用粗粒度操作进行处理,这些操作对于处理迭代算法而言过于繁重。
- Hadoop MapReduce无法在内存中缓存中间数据,而是在每个步骤之后将中间数据刷新到磁盘。
Spark中的RDD类型
- 通过调用诸如map(),flatMap()之类的操作获得的结果RDD被称为MapPartitions RDD。
- 提供读取HDFS中存储的数据功能的RDD被称为HadoopRDD。
- 通过调用诸如合并和重新分区之类的操作获得的结果RDD被称为合并RDD。
Spark中还有许多其他有趣的RDD类型,例如SequenceFileRDD,PipedRDD,CoGroupedRDD和ShuffledRDD。
RDD为Spark生态系统带来许多好处,并且适合批处理分析应用程序,因为它们在沿袭图中具有所有必需的信息,以便在故障后在不同节点上并行重建。RDD确实具有许多优点,但不能用于所有类型的应用程序。RDD可能不适用于诸如Web应用程序的存储系统或增量Web爬网程序之类的应用程序,它们会对共享状态进行异步细粒度更新。
