这是一套完整详细且持续更新的Flink系列教程、文档,旨在帮助开发者快速融入Flink开发,或作为工具文档参阅。
Flink笔记01--初识Flink
1、前言
这将是一套持续更新的、完整的原创Flink系列学习文档,主要参考Flink官方文档,包含各种实例详解、运行原理的讲解,旨在帮助开发者快速学习Flink,或作为工具文档参阅。学习者需要有基础的大数据知识,熟悉Hadoop、Spark。
2、Flink简介
Apache Flink® — Stateful Computations over Data Streams
这段话是官网对Flink做的概况性描述:Flink是在流式数据上进行有状态的计算。
Apache Flink是一个分布式大数据处理引擎,可以对有限数据流和无限数据流进行有状态计算。可部署在各种集群环境,对各种规模的数据进行快速计算。
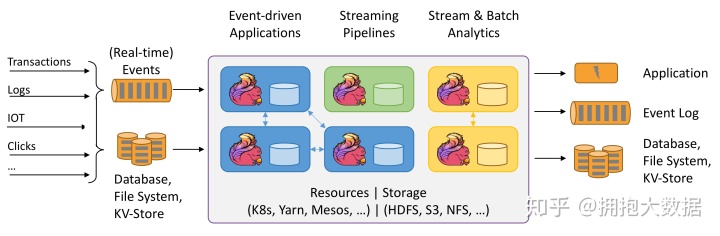
3、Flink历史
Apache Flink的前身是柏林理工大学一个研究性项目,在2014被Apache孵化器所接受,然后迅速地成为了Apache Software Foundation的项目之一。
在国外一些社区,有很多人将大数据的计算引擎分成了 4 代。也有很多人不会认同,这里先姑且这么认为和讨论。
代的计算引擎,毫无疑问就是MapReduce。它将计算分为两个阶段,分别为 Map 和 Reduce。对于应用来说,需要想方设法将应用拆分成多个map、reduce的作业,以完成一个完整的算法。由于这样的弊端,催生了支持 DAG 框架的产生。
支持 DAG 的框架被划分为第二代计算引擎,以 Tez为代表。
接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。
Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性上面。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
Flink在2008年就是柏林理工大学的一个研究项目,比Spark还要早一年。但是开源运作和商业上要比spark慢很多,14年才成为Apache孵化项目,可谓起了个大早,赶了个晚集。Flink主要面向流处理,如果说Spark是批处理界的,那么Flink就是流处理领域的冉冉升起的新星。在Flink之前,不乏流式处理引擎,比较的有Storm、Spark Streaming,但某些特性远不如Flink。
2019年初阿里巴巴集团以9000万欧元的价格收购了总部位于柏林的初创公司Data Artisans。
4、Flink特点
- 支持高吞吐、低延迟、高性能的流式数据处理,而不是用批处理模拟流式处理
- 支持多种时间窗口,如事件时间窗口、处理时间窗口
- 支持exactly-once语义
- 具有轻量级容错机制
- 同时支持批处理和流处理
- 在JVM层实现内存优化与管理
- 支持迭代计算
- 支持程序自动优化
- 不仅提供流式处理API,批处理API,还提供了基于这两层API的高层的数据处理库
5、Flink与其他流式处理框架的对比
目前主流的流数据处理框架有:Storm、Spark Streaming、Flink。
- Storm:支持低延迟,但很难实现高吞吐,不能保证 exactly-once;
- Sparking Streaming :利用微批处理实现的流处理(将连续事件的流数据分割成一系列微小的批量作业)。能够实现 exactly-once 语义,但不可能做到完全实时(毕竟还是批处理,不过还是能达到几秒甚至几亚秒的延迟);
- Flink:实时流处理,支持低延迟、高吞吐、exactly-once 语义、有状态的计算、基于事件时间的处理。相对来说,Flink实现了真正的流处理,并且做到了低延迟、高吞吐 和 exactly-once 语义;同时还支持有状态的计算(即使在发生故障时也能准确的处理计算状态) 和 基于事件时间的处理。

实时框架的选择:
- 流数据是否需要进行状态管理
- At-least-once 或者 Exectly-once消息投递模式是否有特殊要求
- 需要低延迟的应用场景,建议使用storm
- 如果批处理中使用了Spark,秒级的处理延迟满足业务需求,建议使用Spark Streaming
- 要求消息投递语义为 Exactly Once 的场景;数据量大;高吞吐、低延迟的业务场景;需要进行状态管理或窗口统计的场景,建议使用Flink
