作者简介
一十,携程后端开发工程师;振青,携程后端开发专家。
一、前言
携程酒店查询服务是酒店BU后端的核心服务,主要负责提供所有酒店动态数据计算的统一接口。在处理请求的过程中,需要使用到酒店基础属性信息、价格信息等多维度的数据信息。为了保证服务的响应性能,酒店查询服务对所有在请求过程中需要使用到的相关数据进行了缓存。随着携程酒店业务的发展,查询服务目前在保证数据终一致性以及增量秒级更新延迟的情况下,在包括服务器本地内存以及Redis等多种介质上缓存了百亿级的数据。
本文将主要讨论酒店查询服务技术团队是如何在保证读取效率的前提下,针对存储在服务器本地的缓存数据进行存储结构选型以及优化的过程。
二、内存结构选型
为了寻找合适的内存结构以达到理想的效果,本节将详细探讨在通用数据查询场景下,不同类型的数据结构的可行性与优劣势。
2.1 缓存结构的基础需求
2.1.1 支持高性能读取
在大部分应用场景下,之所以需要在服务器内存中存储缓存数据,是因为请求处理过程中需要高频次读取各类数据。为了保证服务的响应性能,我们有的时候会选择将数据提前存储在本地内存,利用空间换取时间。酒店查询服务就有这样的需求:服务平均每次请求需要读取数据上千次,同时对响应时间也有着严格的要求。因此,在这种高频次访问缓存的场景下,对数据的查找性能便有着极高的要求。
在常见的数据结构中,数组和散列表都能提供O(1)的查询速度,是不考虑其他因素下高性能的选择。查找复杂度为O(log2N)的树则其次,其查找速度和数据规模有关,一般只能在数据规模很小的场景下选用。
2.1.2 支持高更新频率
在实际应用场景下,生产环境的缓存数据必然有新鲜度要求。面对海量数据,高频度的数据更新几乎无可避免。特别是像价格这类数据,一方面更改频次极高,另一方面又必须保证新的增量数据可以在秒级内快速同步至缓存中。这就要求所使用的缓存数据结构必须支持高性能并发读写的场景。如果随意的使用锁机制或是线程不安全的存储结构都会可能导致一些预期外的问题与风险:
1)并发更改风险
众所周知,Java提供实现的常用的散列表HashMap是非线程安全的数据结构。若直接使用该类作为缓存结构,则在并发读写时就可能会因为重新Hash而读到错误的数据,甚至在极端情况下产生死循环的问题。
2)滥用读写锁
在频繁并发更新与读取的场景下,错误的锁机制很有可能导致在高频次写入时直接卡死应用处理请求时的高频次读取,进而产生大量请求排队以及其他问题。
因此,高更新频率需求所带来的线程安全问题,导致大部分的基础数据结构都无法适用于存储生产缓存数据。在绝大部分情况下,都需要牺牲一部分性能选择线程安全的数据结构。当然,对于某些特殊场景,也可根据需要来设计定制化的结构与锁机制来达到更优的性能。
经过上面的简单分析后,我们可以暂时认为线程安全的数组和散列表是一个较优的用以承载缓存数据的结构。
2.2 低空间开销的结构选型
由于实际应用的内存都是有限的,因此在保障读写性能的同时,我们也需要思考如何降低缓存所消耗的内存资源。为了保证服务正常的响应请求,酒店查询服务需要在本地存储千万量级的数据,而缓存能够在虚拟机上使用的内存空间却非常有限。因此,除了对数据本身进行过滤等预处理之外,用以存储数据的通用结构的内存开销也要尽可能的小。
在对不同数据结构进行分析前,我们需要从基础的问题开始:Java中的一个对象是以何种结构存储在内存里的?
2.2.1 Java对象内存结构模型
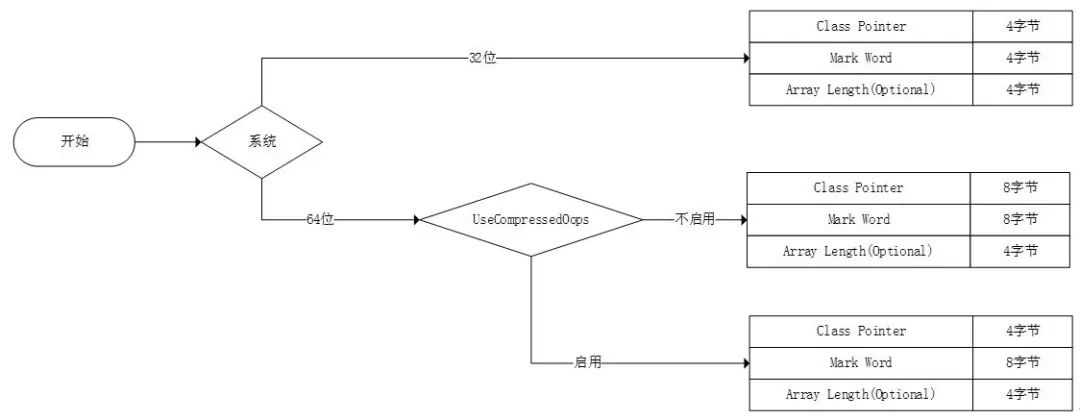
一个Java对象在内存中的存储结构通常包括对象头、实例数据与对齐填充。
对象头
对象头用于存储对象的标记位(Mark Word)与类型指针(Class Pointer)。
标记位里存储了包含锁状态与GC标记位等信息,其在32位系统上占存4字节而在64位系统上占存8字节。
类型指针是一个对象指向它元数据的指针,因此,其在32位系统上占存4字节,在64位系统上占存8字节。同时,若在64位机器上开启指针压缩参数-XX:UseCompressedOops,则此时类型指针在对象头中仅占存4字节。
另外,若实体为数组,则会额外有4个字节用以存储该数组的长度。
实例数据
实例数据内部存储了对象所定义的所有成员变量。这些成员变量会紧密排列,若对象是由子类创建的,则其父类的成员变量也会包含在其中。若成员变量为NULL值,则不会给该成员变量申请指针空间。
对齐填充
若对象所申请的内存空间不是8的倍数,则JVM会添加合适的对齐填充使得整个对象所申请的空间为8的倍数。
综上,若一个简单实例对象内部存储一个int字段以及一个byte字段,那么在开启指针压缩的64位机器上其占存应为24字节。其中包含对象头的8字节标识位与4字节类型指针、内部字段int的4字节与byte的1字节以及对齐填充7字节。

2.2.2 原生HashMap结构内存开销
基于上述的Java实例内存结构的基础理论,我们将以HashMap<Integer,Integer>为主要示例,详细探讨JDK原生HashMap内部结构以及其内存开销。
下表是一个简单的实验结果。我们统计了在开启指针压缩的64位机器上,不同数据条数的键值类型均为Integer的HashMap的内存占存。作为参考,我们将其所存储的所有Integer实例的占存视作数据占存,将剩余的占存视作结构占存。从下表的实验结果来看,无论在何种数据规模下,HashMap内部结构的内存开销占比都很高,占到了整体的55%以上。
需要知道此类现象的成因还是需要从HashMap内部存储结构为入手点进行分析。如下图所示,HashMap主要由一个哈希桶数组及多个存储在哈希桶中的节点Node<Key,Value>所构成。

下面我们来分别具体解析一下哈希桶数组table和数据节点Node的内存开销。
哈希桶数组table
哈希桶数组实际是用于存储数据节点Node的数组。程序将根据数据Key的HashCode运算得到数据节点Node实际应存储在哈希桶数组的哪一个下标位置。通过哈希桶打散数据后,程序可以通过Key快速的查找到实际数据节点。其在源码中实际定义如下:

那么,在内存结构上,哈希桶就是由一个附带数组长度的对象头和数组元素集合组成。因此,一个长度为N的哈希桶数组的占存大小就会是:
8(对象头标识位)+ 4(类型指针)+ 4(数组长度 + 4 (实体引用)*N (实体数量)字节 + 对齐字节。即,长度为32的哈希桶数组则实际占存即为16 + 4 *32 = 144字节。

为了提升读写性能,HashMap中哈希桶数组的实际长度并不会总是等于实际存储的数据量。哈希桶数组的实际长度在两个时候会产生变化:
1)初始化
在HashMap进行实例创建的时候,程序会按照所指定的容量(默认为16)向上取接近的2的整数幂作为实际初始化容量。该容量也是哈希桶数组的长度。比如外部创建一个指定容量为100的HashMap,则其内部哈希桶数组的实际初始长度为128。
2)扩容
HashMap为了确保其读写效率,当内部数据量到达一定规模时,会进行扩容操作。而其负载因子和当前哈希桶数组的长度二者相乘所得出的扩容阈值决定了扩容前在哈希表内部大元素数量。例如,一个容量为32、负载因子为默认的0.75的HashMap的扩容阈值即为32*0.75=24。那么,当此HashMap被插入24条数据后,其内部的原先32长的哈希桶数组就会被扩容至原长度的2倍64。
综合上述的哈希桶长度策略,其实可以很明显的看到HashMap所存储的哈希桶实体数组在绝大部分情况下总是会将冗余出比实际数据量多一些的空间,以减少哈希碰撞、提升读取效率。
下表是在不同数据规模下哈希桶数组相对于普通实体数组,冗余的数组长度及其额外的开销。
数据量 |
实体数组长度 |
哈希桶数组长度 |
哈希桶数组冗余长度 |
冗余内存开销(字节) |
50 |
50 |
128 |
78 |
312 |
200 |
200 |
512 |
312 |
1248 |
1000 |
1000 |
2048 |
1048 |
4192 |
10000 |
10000 |
16384 |
6384 |
25536 |
100000 |
100000 |
262144 |
162144 |
648576 |
那么依据上面的理论,我们就可以推算出不同数据量的HashMap中哈希桶数组的内存开销及其占比。
数据量 |
数据占存 |
哈希桶数组占存 |
总大小 |
哈希桶耗存占比 |
32 |
1024 |
272 |
2352 |
11.56% |
512 |
16384 |
4112 |
36912 |
11.14% |
4096 |
131072 |
32784 |
294960 |
11.11% |
65536 |
2097152 |
262160 |
4718640 |
5.56% |
1048576 |
33554432 |
4194320 |
75497520 |
5.56% |
数据节点Node
Node类继承于 Map.Entry,是HashMap中存储数据的基本单元。其内部除了存储了键值对数据外,同时存储了节点的哈希值以及是当其在链表或红黑树中时,其下个Node节点的引用。

那么,我们可以依据其内部结构如计算出一个Node实例的字节数为32个字节。若要使用Node存储32个Integer键值对,那么所有32个节点实体一共要占用1024个字节。
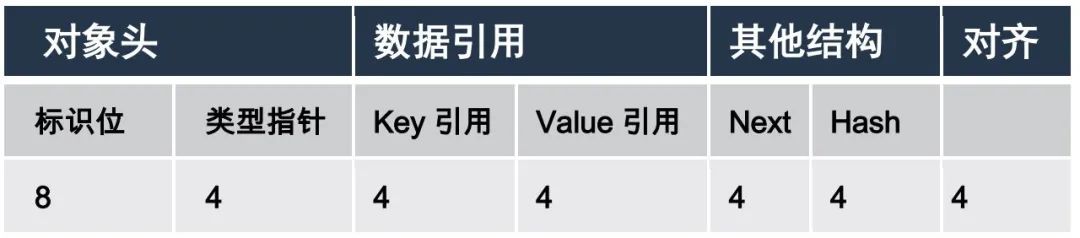
那么我们可以在前面的实验数据中再添加上Node的数据,得到完整的HashMap内存开销各部分的占比:
数据量 |
数据占存 |
哈希桶数组占存 |
Node占存 |
总大小 |
32 |
1024 |
272 |
1024 |
2352 |
512 |
16384 |
4112 |
16384 |
36912 |
4096 |
131072 |
32784 |
131072 |
294960 |
65536 |
2097152 |
262160 |
2097152 |
4718640 |
1048576 |
33554432 |
4194320 |
33554432 |
75497520 |
所以,在原生HashMap消耗了大量的额外空间结构换取其读写性能。这使得原生HashMap在大数据量且内存有限的应用上,并不是一个优的缓存结构选型。
2.2.3 包装类型损耗
由于Java的泛型机制,绝大部分的数据结构的存储的类型只能声明为包装类。因此,即使需要存储是整型等基础类型,也将其不得不转换为对应的包装类型来存储在内存中。这不仅会有存取时产生额外的装拆箱的性能损耗,存储包装类相较基础类型也会产生更大的内存开销。以实际应用场景中为常见的整型为例,我们将简单比较一下Integer[] 和int[] 这两种数组的内存大小差异。
Integer[]
由于Integer是包装类,因此数组中存储的实际是4字节长的Integer的引用。而对于一个Integer实例本身来说,参考前文所述,除了4字节的实际数据外,其还需要12字节来保存其对象头。所以在集合中要保存一个Integer的实际开销就会是4 + 12 + 4 = 20字节。

int[]
基础类型的int[]则简单的多:在创建数组时,仅需为每个元素开辟4字节来保存整型即可。

所以,理论上每个Integer都会比int额外产生16字节的内存开销 。从实验结果可以看出,若我们可以直接使用基础类型来代替包装类存储时,可以大幅减少内存占存。此结论对其他如HashMap等数据结构也同样有效。
数据量 |
int[]占存 |
Integer[]占存 |
额外开销占比 |
32 |
144 |
656 |
78.05% |
512 |
2064 |
10256 |
79.88% |
4096 |
16400 |
81936 |
79.98% |
65536 |
262160 |
1310736 |
80.00% |
1048576 |
4194320 |
20971536 |
80.00% |
2.2.4 其他结构选型
为了在保证读写性能的情况下尽可能压缩内存开销,我们调研了一些第三方的开源集合框架来尝试在内存和性能上尽可能取得平衡。
ConcurrentHashMap
ConcurrentHashMap是HashMap的线程安全版本,内部也是使用数组、链表与红黑树的结构来存储元素。相较于同样JDK中线程安全的HashTable来说,其锁竞争更少、读写效率更高。
SparseArray
SparseArray即稀疏数组,是Android提供的建议替换HashMap<Integer, E>的用来存储整型类型对象键值对的类。其内部主要使用了数组作为存储方式,比HashMap<Integer, E>要高效轻量。
Guava Cache
Guava Cache是google开源的一款本地缓存工具库。其使用多个segments方式的细粒度锁,提供了支持高并发场景的线程安全的存储结构。
fastutil
FastUtil是一个高性能的集合框架,提供了以基础类型为元素的集合来代替JDK原生的集合类型。基础类型为元素的集合避免了大量的基础类型的装箱拆箱。因此,在程序进行集合的遍历、根据索引获取元素的值和设置元素的值的时候,fastutil可以提供更快的存取速度以及更低的内存消耗。
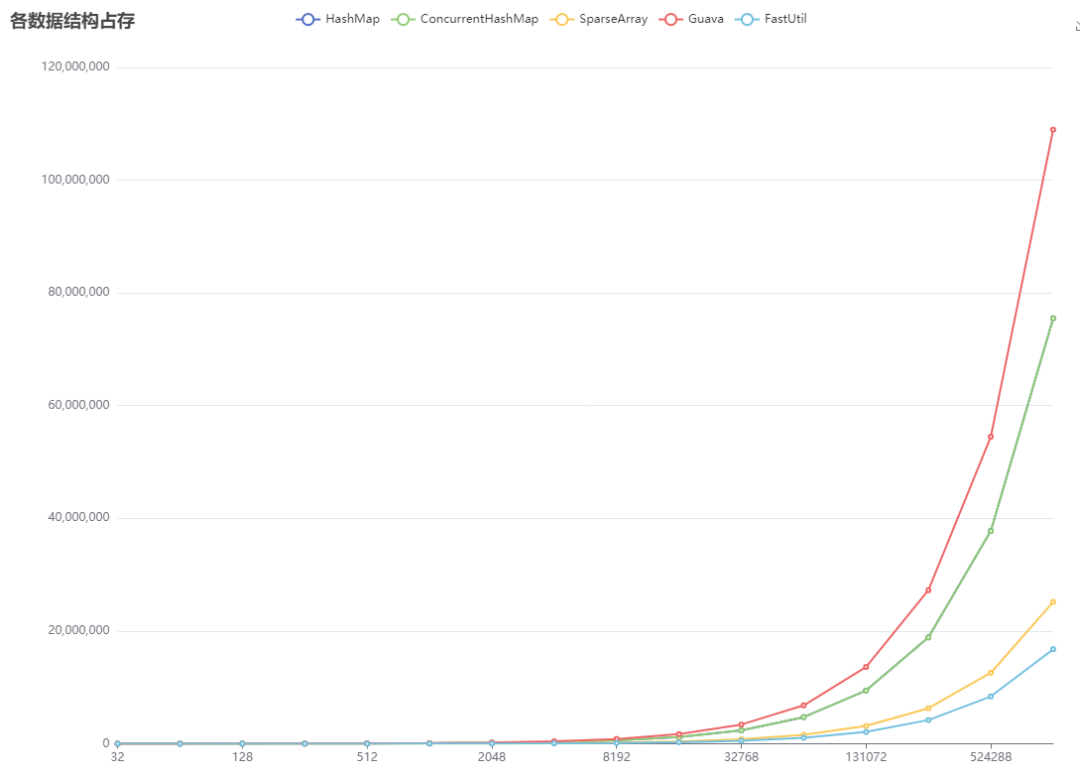
我们实验了整型键值对不同数据规模下各个集合的内存占比,并且用HashMap的数据作为基准进行横向比较。实验结果具体数据如下所示。
数据量 |
HashMap |
ConcurrentHashMap |
SparseArray |
Guava |
fastutil |
32 |
2352 |
2368 |
832 |
4344 |
624 |
256 |
18480 |
18496 |
6208 |
27568 |
4208 |
1024 |
73776 |
73792 |
24640 |
106672 |
16496 |
32768 |
2359344 |
2359360 |
786496 |
3397104 |
524400 |
1048576 |
75497520 |
75497536 |
25165888 |
108970384 |
16777328 |

三、数据编码压缩
在实际应用场景下,几乎所有需要缓存的数据都有着比较高的重复率或是其他分布规律。在内存结构选型的基础上,针对于不同的数据特征,我们可以采用不同的数据编码压缩方式对数据进行压缩处理,进一步降低缓存的内存开销。
下面,我们将介绍几种常用有效的数据编码压缩方式。
3.1 常用编码技术
3.1.1 位图编码
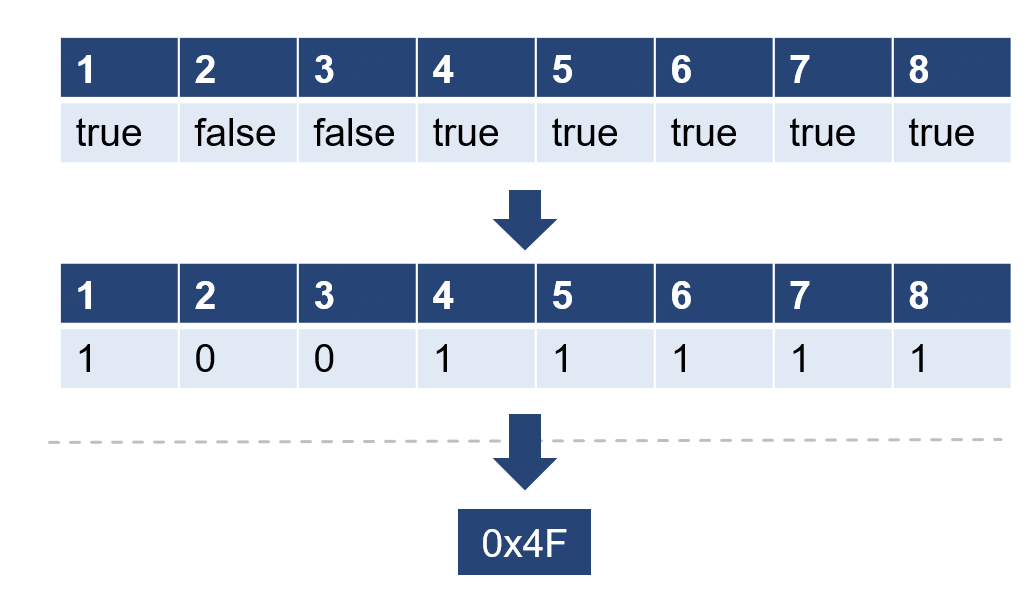
位图(BitMap)是一种常见的编码格式,JDK中提供的默认实现为BitSet类。它是用Bit位来存储数据的某种状态,通常指示是非有无。在常见的情况下,当需要存储大量连续ID是否为True时,用到此类结构就可以大量减少内存的开销。
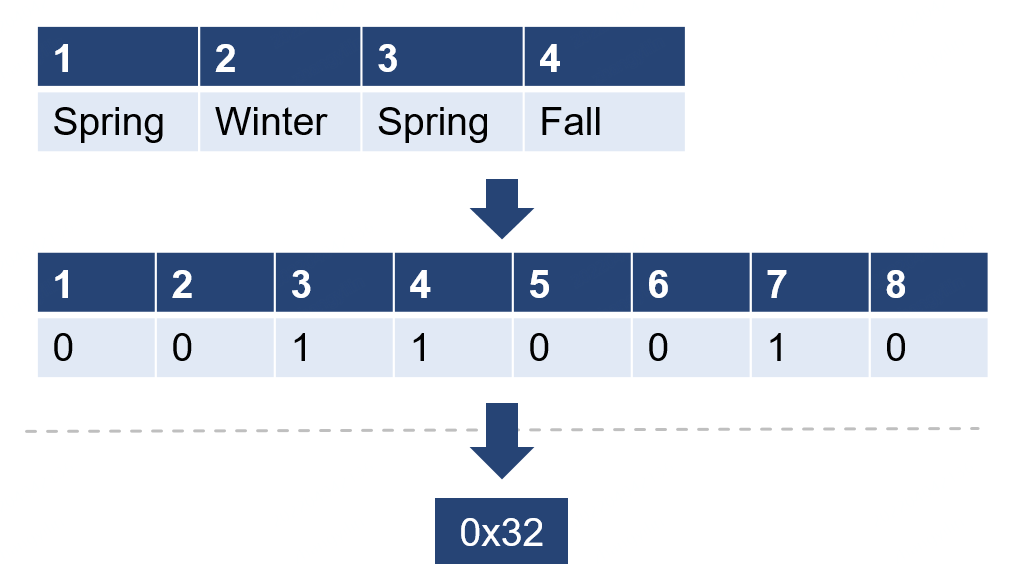
在下例中,需要存储的数据的Key为整型, Value为该Key是否有效的状态数据。若是直接存储,则一条数据至少需要4个字节用于存储整型Key以及4个字节用于存储布尔型的状态值。那么,当需要存储Key从1至8的8条数据,则至少需要64字节。若使用位图编码技术对数据进行处理,那么我们仅需要1个bit即可存储一个True or False的状态信息。因此,就可以使用1个字节存储下所有8条数据的状态信息。此时,该字节的第1位的bit用以表示Key = 1的状态信息,第2位的bit用以Key = 2的状态信息,以此类推。
下表是在64位机器上开启指针压缩后, Java原生HashMap与BitSet的耗存对照表。可以明显地看出,整体压缩效率是非常高的。在实际业务场景下,只要整型Key分布相对密集,就可以利用位图编码达到不错的压缩效果。
大ID |
HashMap占存 |
BitSet占存 |
1w |
532.84KB |
2.04KB |
10w |
5.57MB |
16.04KB |
100w |
53.77MB |
128.04KB |
1000w |
521.76MB |
2.00MB |
另外,位图编码还可以额外扩展至一些类型较少的枚举类型上。例如,枚举类Season只有4种元素,则可以使用2个bit来代表一个属性,那么则只需8bit即可存储id从1-4的 4个Season枚举。
enumSeason{Spring,Summer,Fall,Winter;}
3.1.2 游程编码
游程编码(Run-length encoding,RLE)是一种无损压缩数据的编码方式,主要方法是使用当前数据元素以及该元素连续出现的次数来取代数据中连续出现的部分。若数据存在大量的数据连续且重复的情况,就可以考虑使用RLE以降低内存。
比如,一个内部存储了4个连续的a与6个连续的b的字符串经过游程编码后为a4b6。那么,该字符串长度就从10字节减少至4字节。

3.1.3 字典编码
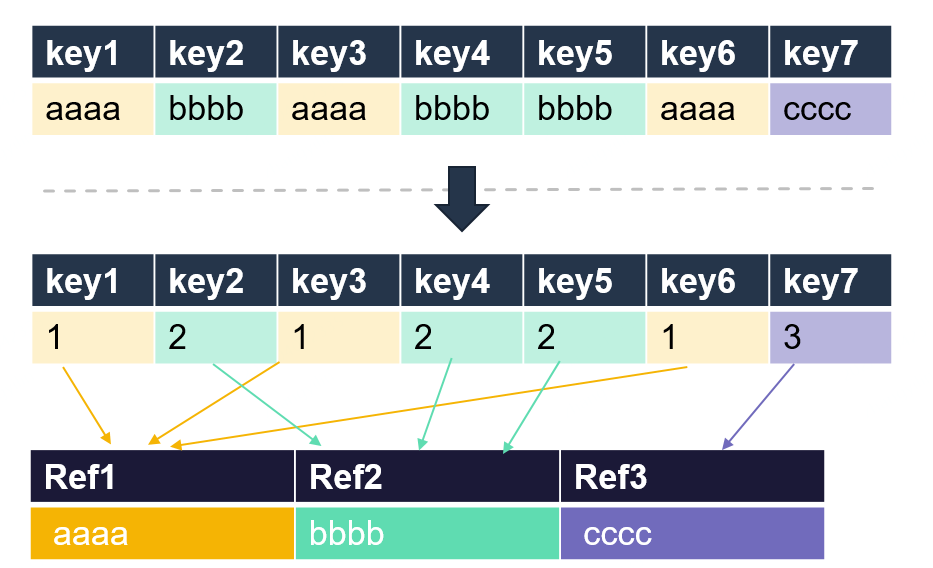
字典编码是把整体重复性高的数据进行去重后建立字典,把原来存放数据的地方变为指向实体字典引用的编码方式。因为引用指针依然占存,因此适合单个的实例数据字段较多的数据缓存。
下例为原始数据为整型Key查询长字符串Value的场景。首先,将重复的字符串实体数据提取出来,将其单独作为一个实体字典进行存储。该字典Key为一个指针,Value则为提取出的不重复的字符串数据。然后,原始字典的Value就可以变为一个指针,指向新实体字典的Key。当需要查询Key1内实际数据的时候,先在原始字典中查询到引用Ref1,再在实体字典查询Ref1即可获得其Value值aaaa。
3.1.4 差值编码
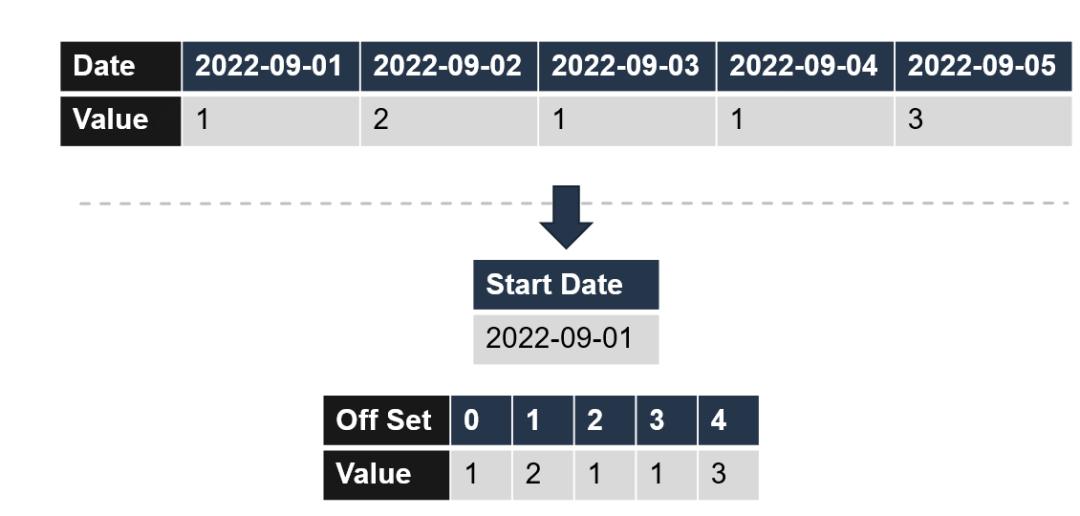
差值编码是对于非连续的数据Key通过差值计算的方式转化为连续的Key,让字典可以转化为数组的编码方式。
下例中的数据Key为日期,Value为一个整型。在日期相对连续的情况下,取所有日期的小值为开始日期,以数据生效日期到开始日期的差值为新字典的Key。那么编码前旧数据字典的Key为Date类型,而编码后的新数据字典的类型则可以转化为更小更泛用的int型。
下表是在N天连续的日期查整型的场景下,原生HashMap与编码后整型数组的耗存对照表。即使连续的日期数量较小,也可以看出整体存在的巨大差距。在实际的应用场景下,此类编码方式一般用于连续日期的缓存,也可以扩展到其他有着类似数据特征的缓存上。
日期数量 |
HashMap占存 |
编码后整型数组占存 |
100 |
8.09KB |
440B |
1w |
767.19KB |
39.10KB |
1000w |
750.65MB |
38.15MB |
以上的编码技术可以在不同的数据场景下进行组合使用,接下来我们将简要的展示两个实际酒店查询服务缓存内存压缩优化的案例。
3.2 应用案例
3.2.1 房型基础信息
查询服务缓存了上亿条房型信息数据。在请求处理过程中,服务可以在缓存中通过房型ID查询到该房型的信息。因为数据条数上亿且实体内部字段很多,因此未优化的缓存在内存中占存高达上百GB,是一个较大的内存性能瓶颈。
因此,针对该缓存,我们使用了位图编码以及字典编码,大幅降低了其内存开销。
1)使用位图编码对可枚举字段进行数据压缩
我们将房型数据实体上包括布尔型、枚举以及部分字符串等所有可以枚举的字段进行了位图编码,大幅降低了单个实体的占存大小。比如在下方作为例子的字段中,RoomType虽然存储为一个String,但是在实际业务场景中它一共只有5种取值可能性,因此也可以作为枚举类进行处理为3个bit。
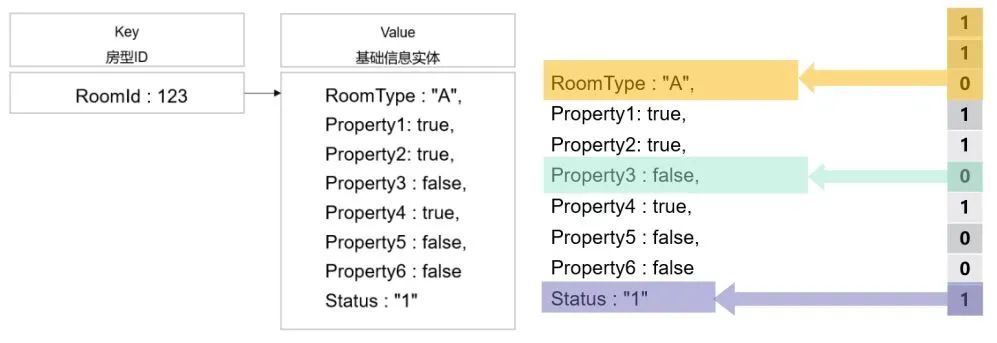
在原先存储方式的情况下,示例的一个房型实体字段就至少需要16字节,通过位图编码后一个房型实体字段实际仅需要10个bit即可无损的存储下所有有效信息。

2)使用字典编码对重复实体进行压缩
经过线上数据统计与分析,我们发现部分房型属性数据的重复率达到99%。也就是说,虽然存在上亿个房型,但是实际去重后的房型的部分基础信息实体只有百万级。因此,在对房型基础信息实体本身进行位图编码的同时,我们采用了字典编码的方式对房型ID不同但内部字段信息完全重复的数据实体进行字典编码,以压缩这部分的消耗。
在实际处理过程中,我们会先将房型数据实体进行序列化后转换为MD5,在房型字典中只存储MD5编码,而实体字典中存储MD5到实际房型信息实体的关系。在进行数据查询时,则是先通过房型ID在房型字典中查找到对应的MD5值,然后在实体字典中通过MD5值查找到对应的房型基础信息实体。
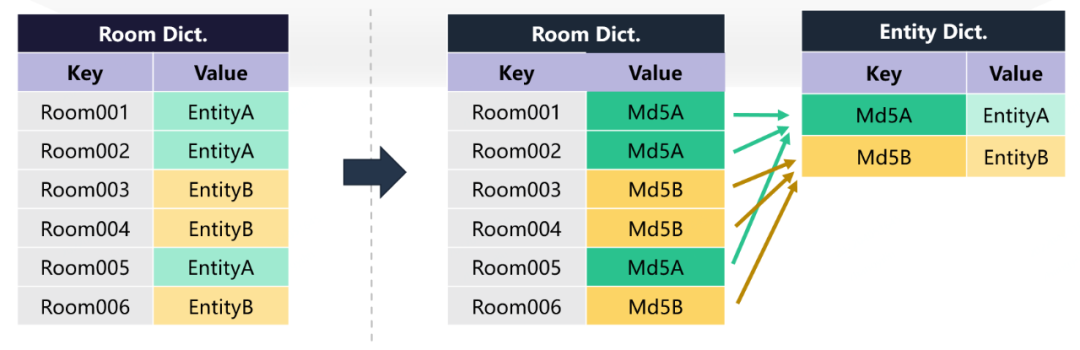
经过上述两个编码压缩优化后,房型实体缓存占存整体压缩率达到2%以下,节省了数十GB的内存空间。
3.2.2 单天房价信息
单天房价信息缓存是存储每个房型每日价格的缓存,是查询服务数据量大同时也是核心的数据缓存。在应用请求处理过程中,会使用房型ID以及日期从该缓存中获取房型某一天的价格数据。
下面将以单房型下存储的日期信息为例,逐步展示数据压缩优化的全部过程。
1)使用字典编码对每日重复的价格信息进行编码
首先,将所有该房型上出现的价格提取并存储到一个价格数组上,在数据字典里则存储实际价格数据在价格字典的索引。同时,因为存在可能没有数据的日期,因此Null值被存储在所有价格数组上的个偏移index上,作为默认值。

2)使用差值编码处理日期
因为在绝大部分情况下,数据字典中的日期均为连续的,且从业务场景上来说大的日期也不会过大,因此我们采用差值编码处理日期,将数据字典中的日期替换为与服务器启动日期之间相差天数的偏移量。此时,数据字典的Key则会变为一个从0开始的int,那么就可以使用占存更小的数组来表示这个数据字典。该数据索引数组为一个int[],其下标表示日期偏移,值表示到价格字典的索引。
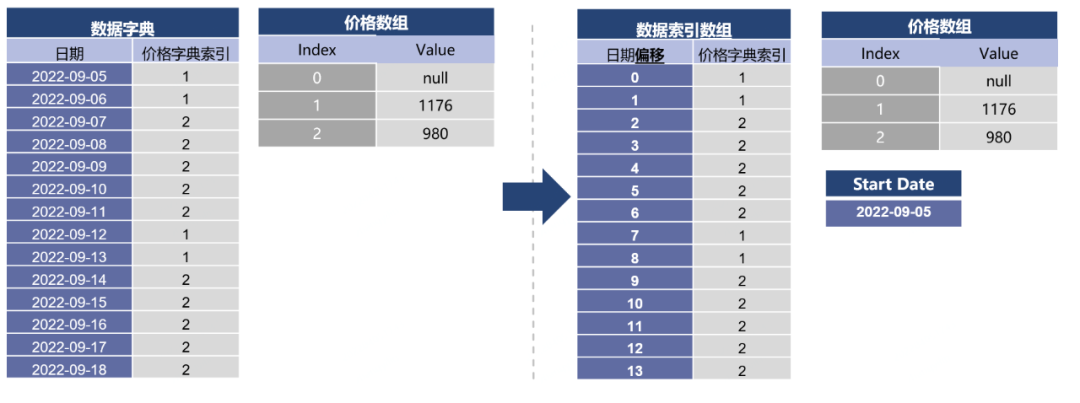
3)使用位图编码处理可枚举的价格索引
因为单个房型下的价格数量是有限的,因此同样可以视作是枚举值的一种。对枚举值,就可以使用位图编码对数据索引数组进行压缩。在下图的数据样例中,因为价格数组长度为3,即存在3种可能的价格,因此将int转换为2个bit进行存储,则位图的一天的偏移步长为2。
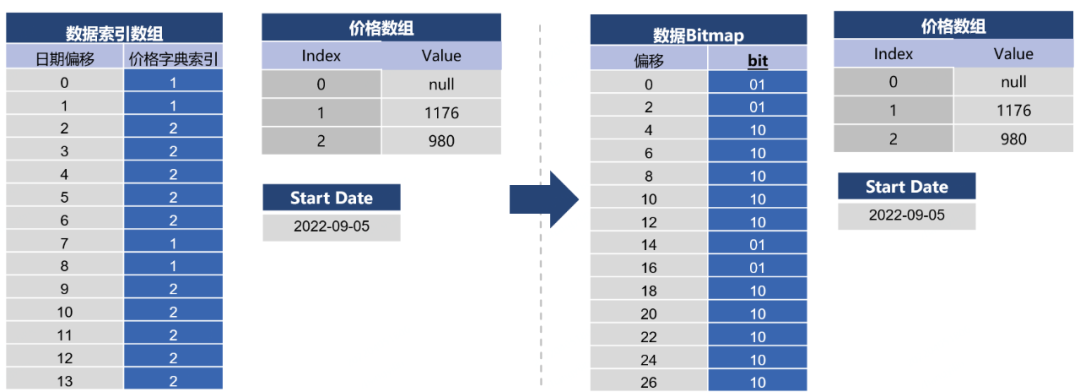
4)使用RLE编码处理末尾
在很多房型下的到天价格数据,在距离现在远的日期带的价格通常都是重复的,因此,我们可以使用RLE的方式对末尾重复的数据进行截尾,来进一步压缩数据位图大小。
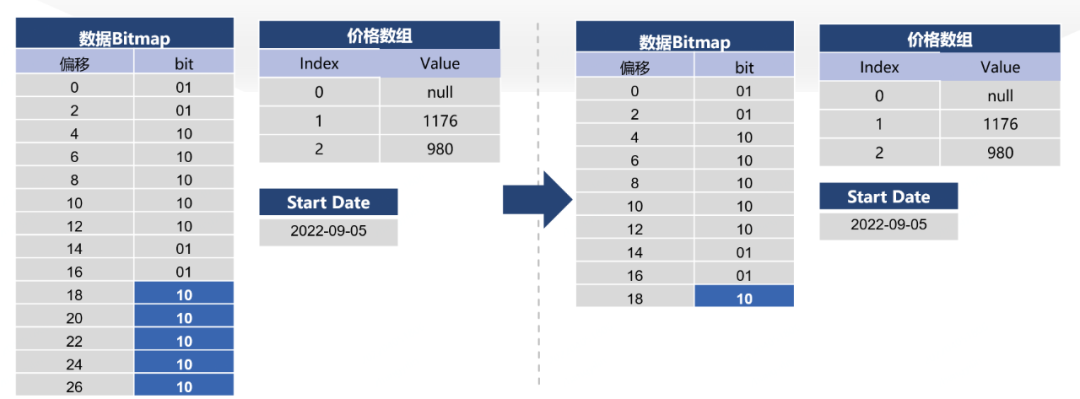
在所举的例子中,其在内存中单对象实例数据部分的内存可以从初的数百字节降低至终的31字节。而在实际业务场景中,该单天房价数据经过压缩处理后实际压缩率为60%左右。
四、总结
本文主要介绍了携程酒店查询服务在本地缓存数据结构选型以及优化方面的探索与实际应用案例。
在常规缓存数据的存储结构选型上,我们先根据缓存场景的需求,分析比较了不同数据结构后,选择线程安全的Map结构作为基础研究方向。然后基于Java对象占存的原理,以原生HashMap为实际案例,详细分析了其内存实际占用的分布,并比对了多种常见的用于缓存的内存结构的优劣势。

在进一步优化的时候,针对不同类型的数据可以进行选择不同的编码方式,并以两个实际的缓存压缩方案为例,介绍了如何组合的使用此类编码来有效压缩本地缓存的内存大小。

综上所述,虽然存储在服务器内存中的缓存成本较高,但是若合理的进行数据选型并采用合适的优化方法,则可以达到使用少量的内存缓存大规模的数据,以较低的成本大幅提高应用的响应性能的目的。
参考资料
Java对象布局:
https://www.jianshu.com/p/91e398d5d17c
fastutil官网:
Guava github:
https://github.com/google/guava
SparseArray文档:
https://developer.android.com/reference/android/util/SparseArray
