一、Hive 小文件概述
在Hive中,所谓的小文件是指文件大小远小于HDFS块大小的文件,通常小于128 MB,甚至更少。这些小文件可能是Hive表的一部分,每个小文件都包含一个或几个表的记录,它们以文本格式存储。
Hive通常用于分析大量数据,但它在处理小文件方面表现不佳,Hive中存在大量小文件会引起以下问题:
存储空间占用过多:在Hadoop生态系统中,每个小文件都将占用一定的存储空间,而且每个小文件也需要一个块来存储。如果存在大量的小文件,将浪费大量的存储空间。
处理延迟:小文件数量过多,会引起大量IO操作,导致处理延迟。
查询性能下降:小文件用于分区和表划分,可能导致查询延迟并降低查询性能。此外,小文件还会增加元数据的数量,使得Hive在查询元数据时变得更加缓慢。
数据倾斜:如果数据分布不均匀,会导致一些Reduce任务处理了完全不同的分区,这会使某些Reduce任务的运行速度与其他Reduce任务相比非常慢。
因此,为了避免这些问题,我们需要对Hive中小文件的处理进行优化,减少小文件数量和大小,以提高数据处理效率和准确性。

二、Hive 小文件产生的背景
Hive中小文件产生的背景主要是因为以下两个原因:
数据写入频率较高:如果表的写入频率较高,也就意味着会频繁地添加、更新或删除记录,这可能会导致小文件的产生。由于Hive表被映射到HDFS文件,因此如果频繁地写入数据,它们可能以小文件的形式存在。
映射表的切分限制:Hive表映射为HDFS文件时会按照数据块大小进行切分和管理。如果表中存在小于单个数据块大小的数据,生成的文件就会比数据块小。这可能会导致大量小文件的产生,
综上所述,Hive中小文件的存在与数据写入频率高和表映射为HDFS文件的切分方式有关。为了处理小文件问题,我们需要了解这些背景并针对其原因来优化处理。
三、环境准备
如果已经有了环境了,可以忽略,如果想快速部署环境进行测试可以参考我这篇文章:通过 docker-compose 快速部署 Hive 详细教程
# 登录容器
docker exec -it hive-hiveserver2 bash
# 连接hive
beeline -u jdbc:hive2://hive-hiveserver2:10000 -n hadoop
四、Hive 小文件治理
为了处理Hive中的小文件问题,可以采取以下一些有效措施:
文件合并:将多个小文件合并成一个大文件,采用 Hadoop 文件合并API可以将多个小文件合并成一个大文件。合并文件后,可以减少小文件数量,减少Hadoop文件管理负担,减少HDFS元数据和NameNode内存消耗。
压缩文件:可以使用压缩算法(如gzip、bzip2等)对小文件进行压缩,这样可以减少磁盘空间和网络带宽的使用,并减少小文件损坏的可能性。
存储格式优化:Hive支持多种存储格式,如ORC、Parquet、Avro等。这些格式允许将多个小文件压缩并序列化成一个大文件,存储时占用更少的磁盘和网络带宽。存储格式优化对于处理小文件问题非常有效。
分区表:对于一些常变动的数据,推荐使用分区表。分区表将数据按照不同的分区值存储在不同的目录中。这减少了小文件数量并提高了查询效率。
垃圾回收:如果一个表旧数据经常更新或删除,就会产生大量无用的小文件,因此建议进行垃圾回收。可以定期执行HDFS文件删除命令或者设置TTL等机制,定期删除冗余数据以减少HDFS文件、元数据和NameNode内存的消耗。
通过采取上述措施中的一种或多种,可以极大地减少Hive中小文件数量,优化Hive表的表现并提高查询效率。
1)小文件合并(常用)
可以使用以下命令将 Hive 表中的小文件合并为一个大文件:
set hive.merge.size.per.task=256000000;
set hive.merge.smallfiles.avgsize=16000000;
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
set hive.merge.mapfiles=true;
# 未分区
INSERT OVERWRITE TABLE table_new SELECT * FROM table_old;
# 分区
INSERT OVERWRITE TABLE table_new SELECT column1,column2 FROM table_old where partitions;
上述代码中的参数含义如下:
hive.merge.size.per.task:设置MapReduce任务处理的大数据大小,单位是字节,默认为256MB。hive.merge.smallfiles.avgsize:设置如果小于该平均大小的文件需要合并在一起,以减小小文件的数量和规模,单位是字节,默认为16MB。hive.input.format:使用 CombinHiveInputFormat 作为输入格式合并小文件。hive.merge.mapfiles:合并Map文件(.mapred或.mapreduce)以减少小文件的数量。
1、示例演示一(非分区表)
# 非分区表
CREATE TABLE student (
id INT,
name STRING,
age INT,
address STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';
-- 添加数据,这里多执行几次,会生成多个文件,方便下面文件合并实验
INSERT INTO TABLE student VALUES (1, 'stu1', 15, 'add1'),(2, 'stu2', 16, 'add2'),(3, 'stu3', 17, 'add3');
-- 也可使用LOAD DATA LOCAL
LOAD DATA LOCAL INPATH './stu.txt' INTO TABLE student;
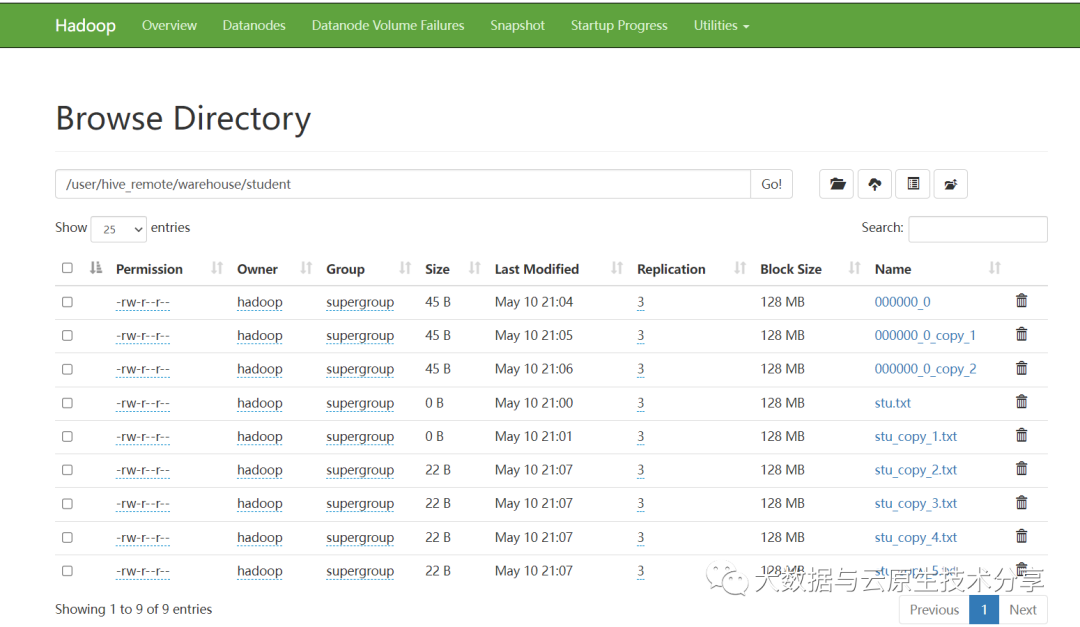
从上图可看到已经有很多小文件了,接下来就是进行合并了。执行以下命令即可:
INSERT OVERWRITE TABLE student SELECT * FROM student;
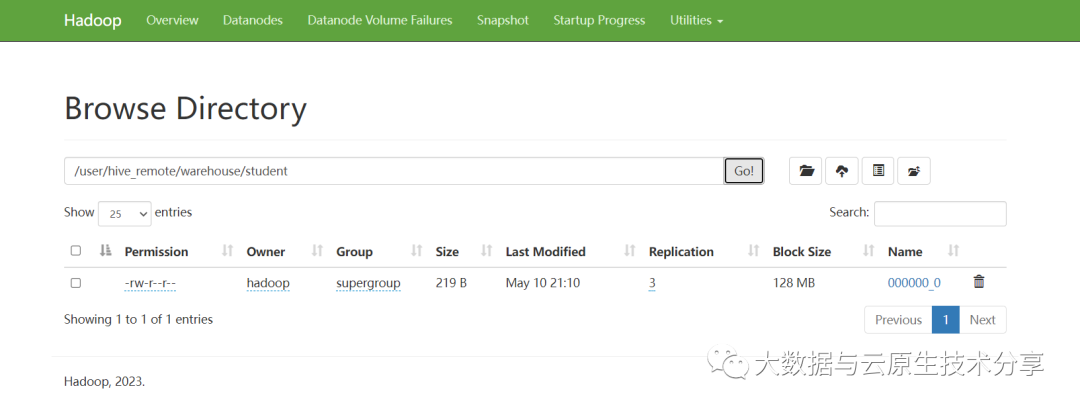
已经将多个文件合并成一个文件了,达到了小文件合并的效果了。
2、示例演示二(分区表)
其实用的多的还是按分区进行合并,一般表都是有分区的,按分区合并的好处就是减少读写压力,数据量大的情况下分批合并是非常友好的。
# 分区表
CREATE TABLE student_patitions (
id INT,
name STRING,
age INT,
address STRING
)
PARTITIONED BY (year string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';
-- 开启动态分区,默认是false
set hive.exec.dynamic.partition=true;
-- 开启允许所有分区都是动态的,否则必须要有静态分区才能使用。
set hive.exec.dynamic.partition.mode=nostrick;
-- Hive默认情况下设置的大动态分区创建数是100。
set hive.exec.max.dynamic.partitions=10000;
-- 添加数据,这里多执行几次,会生成多个文件,方便下面文件合并实验
INSERT INTO TABLE student_patitions PARTITION (year=2019) VALUES (1, 'stu1', 15, 'add1'),(2, 'stu2', 16, 'add2'),(3, 'stu3', 17, 'add3');
INSERT INTO TABLE student_patitions PARTITION (year=2023) VALUES (1, 'stu1', 15, 'add1'),(2, 'stu2', 16, 'add2'),(3, 'stu3', 17, 'add3');
-- 也可使用LOAD DATA LOCAL
LOAD DATA LOCAL INPATH './stu_pt.txt' INTO TABLE student_patitions PARTITION (year=2020);
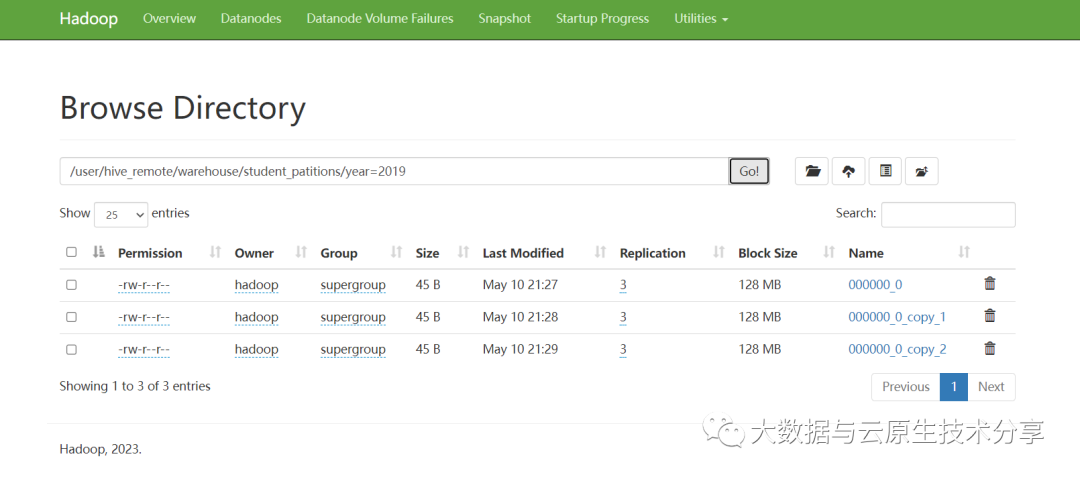
从上图可看到已经有很多小文件了,接下来就是进行合并了。执行以下命令即可:
-- 按分区合并
insert overwrite table student_patitions partition(year=2019)
select id, name, age, address from student_patitions where year=2019;
-- 动态分区合并,有些版本不支持*,
-- *
insert overwrite table student_patitions partition(year) select * from student_patitions;
-- insert overwrite table student_patitions partition(year) select id, name, age, address from student_patitions;
-- 也可以通过load data方式
load data local inpath './stu_pt.txt' overwrite into table student_patitions partition(year=2019);
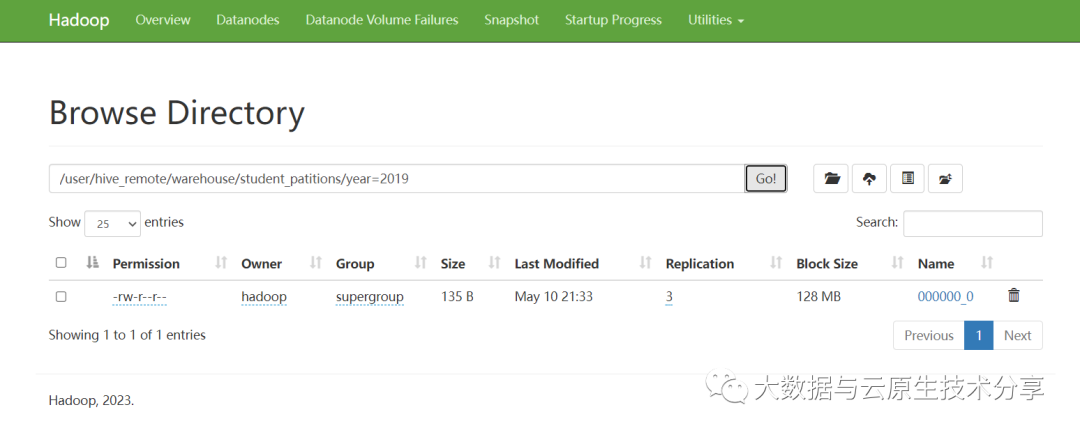
3、示例演示三(临时表)
还有一个更靠谱的方案就是通过将现有的表数据合并写到另外一张临时新表,然后确认合并无误后,将原始表和表数据删除,再将新表名改成旧表名。
示例如下:
-- 分区表
CREATE TABLE student_patitions2 (
id INT,
name STRING,
age INT,
address STRING
)
PARTITIONED BY (year string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';
-- 开启动态分区,默认是false
set hive.exec.dynamic.partition=true;
-- 开启允许所有分区都是动态的,否则必须要有静态分区才能使用。
set hive.exec.dynamic.partition.mode=nostrick;
-- Hive默认情况下设置的大动态分区创建数是100。
set hive.exec.max.dynamic.partitions=10000;
-- 添加数据,这里多执行几次,会生成多个文件,方便下面文件合并实验
INSERT INTO TABLE student_patitions2 PARTITION (year=2019) VALUES (1, 'stu1', 15, 'add1'),(2, 'stu2', 16, 'add2'),(3, 'stu3', 17, 'add3');
INSERT INTO TABLE student_patitions2 PARTITION (year=2023) VALUES (1, 'stu1', 15, 'add1'),(2, 'stu2', 16, 'add2'),(3, 'stu3', 17, 'add3');
-- 也可使用LOAD DATA LOCAL
LOAD DATA LOCAL INPATH './stu_pt.txt' INTO TABLE student_patitions2 PARTITION (year=2020);
创建临时表并将添加合并数据
CREATE TABLE student_patitions2_temp (
id INT,
name STRING,
age INT,
address STRING
)
PARTITIONED BY (year string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';
-- 按分区合并,有些版本不支持*
insert overwrite table student_patitions2_temp partition(year)
select * from student_patitions2;
-- insert overwrite table student_patitions2_temp partition(year) select id, name, age, address from student_patitions2;
-- 也可以通过load data方式
load data local inpath './stu_pt.txt' overwrite into table student_patitions2_temp partition(year=2019);
删除旧表,修改表表名称
# 删表,如果是外部表还是删除数据文件
DROP TABLE student_patitions2;
ALTER TABLE student_patitions2_temp RENAME TO student_patitions2;
2)文件压缩
可以使用以下命令将表中的小文件进行压缩:
SET hive.exec.compress.output=true;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
INSERT OVERWRITE TABLE table_new SELECT * FROM table_old;
3)存储格式优化
使用存储格式进行优化,可以将多个小文件压缩和序列化成一个大文件。以下是使用ORC格式的实现示例:
SET hive.exec.compress.output=true;
SET orc.compress=SNAPPY;
SET hive.exec.orc.default.compress=SNAPPY;
CREATE TABLE table_new STORED AS ORC AS SELECT * FROM table_old;
上述代码中的参数含义如下:
hive.exec.compress.output:指定是否开启压缩,如果启用则会对输出进行压缩,以节省存储空间和网络带宽。orc.compress:设置压缩算法,这里使用SNAPPY。hive.exec.orc.default.compress:设置ORC文件默认压缩算法,这里使用SNAPPY。
4)分区表
可以使用以下SQL语句创建分区表:
CREATE TABLE table_new(
column1 INT,
column2 STRING
)
PARTITIONED BY (
day STRING
)
ROW FORMAT DELIMITED
STORED AS TEXTFILE;
这里将表按照分区值进行存储,可以提高查询效率,减少小文件数量。
5)垃圾回收
删除HDFS中过期的小文件可以减少 HDFS 的存储开销。
可以使用如下命令进行删除操作:
hdfs dfs -rm /path/to/file-*
也可以使用 HiveQL 参数 EXPIRE 进行垃圾回收,以将无用的文件从HDFS中删除:
ALTER TABLE table_old DROP PARTITION (day '2016-01-01') PURGE;
上述代码中将删除旧的分区并从HDFS中删除不再需要的数据。
综上所述,可以通过上述方式来处理Hive中小文件问题,以提高*Hive的查询效率和性能。
五、HDFS 数据平衡
1)HDFS 数据倾斜
HDFS数据倾斜是指存在一些数据块的大小明显大于其他数据块,导致作业在运行时的处理时间和性能严重不平衡。这通常是由于数据分布不均匀,或者任务负载不均匀导致的。Hive的MapReduce作业经常面临HDFS数据倾斜的问题,这会导致一部分Mapper处理的数据量很大,而其他Mapper却没有得到充分利用。
以下是一些缓解HDFS数据倾斜的方法:
增大文件块大小:如果您的作业经常面临数据倾斜问题,可以尝试增大数据块的大小。这样可以降低Mapper需要处理的数据块数量,从而减少数据块分配不均衡的可能性。
数据合并:如果您的作业中存在大量较小的文件,可以尝试将它们合并为几个较大的文件。这样可以减少地图任务的数目,并有助于均衡任务的负载。
数据重分区:如果在您的作业中数据分布极不均匀,可以尝试使用数据重分区(例如Hive中的 CLUSTER BY 或 DISTRIBUTE BY 语句)来重新组织数据。这可以帮助将相似的数据放在同一个分区中,从而减少数据倾斜的可能性。
动态分区:在Hive中,动态分区可用于根据数据中实际的分区键动态创建分区。它可以使用较小的数据块大小来提高作业的并行性。动态分区还可以通过确保数据分配均衡来缓解数据倾斜的问题。
压缩:使用压缩技术可以减小数据块大小,并减少倾斜问题的可能性。常用的压缩格式包括Gzip、Snappy、LZO等。
HDFS数据倾斜不仅可能出现在数据块的大小上,还可能出现在数据节点(Datanode)的负载上。如果一个Datanode存储的数据块远远多于其他Datanode,那么它处理作业时的负载将远高于其他节点,从而导致整个集群性能下降。下面是一些缓解HDFS数据节点倾斜问题的方法:
增加节点:可以向集群中添加更多的节点,以增加存储能力。这样可以分散节点的负载,避免单个节点负载过高。尽管这样做可能会增加集群的维护成本,但它可以提高集群的性能和可靠性。一般增加完新节点需要做数据平衡,要不然新节点磁盘使用率远低于其它节点的磁盘。
均衡数据分布:您可以使用HDFS中的均衡命令(hdfs balancer)来均衡数据分布。该命令将根据需要将块移动到不同的节点,以保持所有节点的负载相对均衡。
更改块大小:当块大小不均衡时,您可以尝试根据每个节点的存储容量增加或减少块大小,以确保每个节点的负载相对均衡。例如,如果一个节点存储大量的小文件,则可以将块大小增加到更适合这种情况的大小(例如512MB或1GB),以减少每个节点的块数。
数据迁移:如果一个节点负载过高,您可以从该节点中移动一些块到其他节点中,以减轻该节点的负载。这可以通过将块从一个节点复制到另一个节点来实现。需要注意的是,这样做可能会影响作业的性能,因此建议在维护合适的性能的同时进行数据迁移。
需要注意的是,缓解HDFS数据节点倾斜问题需要综合考虑多种因素,包括数据分布、集群规模、硬件配置等。根据具体情况,您可以采取不同的措施来缓解数据节点倾斜的问题。
2)HDFS 数据平衡
HDFS提供了 hdfs balancer 命令来进行数据平衡呢。hdfs balancer命令可以让HDFS集群重新均衡分布数据块,保证HDFS集群中数据块在各个节点上均衡分布。
hdfs balancer 命令的语法如下:
hdfs balancer -help
Usage: java Balancer
[-policy <policy>] the balancing policy: datanode or blockpool
[-threshold <threshold>] Percentage of disk capacity
[-exclude [-f <hosts-file> | comma-sperated list of hosts]] Excludes the specified datanodes.
[-include [-f <hosts-file> | comma-sperated list of hosts]] Includes only the specified datanodes.
参数详解:
-threshold:某datanode的使用率和整个集群使用率的百分比差值阈值,达到这个阈值就启动hdfs balancer,取值从1到100,不宜太小,因为在平衡过程中也有数据写入,太小无法达到平衡,默认值:10-policy:分为blockpool和datanode,前者是block pool级别的平衡后者是datanode级别的平衡,BlockPool 策略平衡了块池级别和 DataNode 级别的存储。BlockPool 策略仅适用于 Federated HDFS 服务-exclude:不为空,则不在这些机器上进行平衡-include:不为空,则仅在这些机器上进行平衡-idleiterations:大迭代次数
另外还有两个常用的参数:
dfs.datanode.balance.bandwidthPerSec:HDFS做均衡时使用的大带宽,默认为1048576,即1MB/s,对大多数千兆甚至万兆带宽的集群来说过小。不过该值可以在启动balancer脚本时再设置,可以不修改集群层面默认值。目前目前我们产线环境设置的是50M/s~100M/s。dfs.balancer.block-move.timeout:是一个Hadoop数据平衡命令hdfs balancer的选项之一,用于设置数据块移动的长时间。该选项指定了块移动操作在多长时间内必须完成。该选项默认值为120000毫秒(即2分钟),可以通过以下命令进行修改:
简单使用:
# 启动数据平衡,默认阈值为 10%
hdfs balancer
# 默认相差值为10% 带宽速率为10M/s,超时时间10分钟,过程信息会直接打印在客户端 ctrl+c即可中止
hdfs balancer -Ddfs.balancer.block-move.timeout=600000
#可以手动设置相差值 一般相差值越小 需要平衡的时间就越长,//设置为20% 这个参数本身就是百分比 不用带%
hdfs balancer -threshold 20
#如果怕影响业务可以动态设置一下带宽再执行上述命令,1M/s
hdfs dfsadmin -setBalancerBandwidth 1048576
#或者直接带参运行,带宽为1M/s
hdfs balancer -Ddfs.datanode.balance.bandwidthPerSec=1048576 -Ddfs.balancer.block-move.timeout=600000
关于 Hive 小文件治理和 HDFS 数据平衡讲解就先到这里了,有任何疑问欢迎给我留言或私信
