存储过程
语法:
创建存储过程
drop procedure if exists [存储过程名] ;
delimiter [结束标记]
create procedure [存储过程名]([参数1], [参数2] ...)
begin
[存储过程体(一组合法的sql语句)]
end [结束标记]
delimiter ;
参数,其格式为 [in|out|inout] parameter_name type
in #表示输入参数;
out #表示输出参数;
inout #表示此参数既可以输入也可以输出;
param_name #表示参数名称;
type #表示参数的类型。
delimiter [结束标记] 本身与存储过程的语法无关,用于表示SQL语句的结束。
后一个命令 delimiter ; 将 分隔符 改回 分号 ,用于告诉SQL引擎,遇到 分号 就可以提交了。
为什么要用 delimiter 定义 结束标记?
因为 SQL引擎 执行时,遇到分号(;)表示一个SQL语句的结束,会把这个SQL进行提交。
但是 存储过程和自定义函数,功能比较复杂,里面有好多条的SQL语句, 我们希望SQL引擎把 这一个存储过程或函数当成一个整体提交 (即原子性),而不是每段SQL语句遇到分号(;)就提交,这就无法保证完整性。
为了解决SQL执行引擎遇到分号提交的问题,就要使用 delimiter 定义一个新的结束标记 ,只不要是分号, SQL引擎就不会提交,这样保证 存储过程和自定义函数 的整体性。
所以,SQL 的 delimiter 的结束标记 不能定义为分号(;),一般使用特殊字符,如$ 、//、/ 等。
begin...end 语句块。 在 sql 语句,如果包含多条语句, 我们需要把多条语句放到 begin...end 语句块中。begin...end 块可以嵌套,同一组的SQL 代码放到 一个 begin...end 块,层层分开, 大的好处是便于阅读 。 如果仅仅一条sql语句,则可以省略 begin end 。
begin...end 相当于 java 语言中的 { } 。如果 if 内只有一条SQL时,{ } 可以省略,同样,begin...end 也可以省略。
public int method(int param){
int result=;
if(param==1){
result=......
}else if{param==2}{
result=......
}else{
result=......
}
return result;
}
public int method(int param){
int result=;
// 当 if 内只有一条SQL时,{ } 可以省略
if(param==1)
result=......
else if{param==2}
result=......
else
result=......
return result;
}
调用存储过程
call [存储过程名]([ proc_parameter [,proc_parameter ...]])
call [存储过程名]
说明:
当无参数时,可以省略括号,不写; 当有参数时,不可省略括号。
存储过程修改 : 修改存储过程,就是删除重建。
删除存储过程: drop procedure [if exists] sp_name
示例
drop table if exists `t_user`;
create table `t_user` (
`id` int not null auto_increment,
`name` varchar(20) not null,
primary key (`id`)
) engine=innodb auto_increment=1 default charset=utf8;
无参数的存储过程
drop procedure if exists myproc1;
delimiter $
create procedure myproc1()
begin ## 下面只有一条语句,begin end 可以省略
insert into t_user values(null, 'Jas'),(null, 'Joy');
end $
delimiter ;
调用,并查看结果: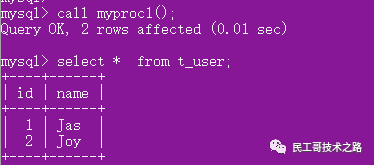
只有一个 in 参数的存储过程
drop procedure if exists myproc2;
delimiter $
create procedure myproc2(in userId int)
begin
select name from t_user where id = userId;
end $
delimiter ;
调用,并查看结果:
包含 in 参数和 out 参数的存储过程
drop procedure if exists myproc3;
delimiter $
create procedure myproc3(in userId int, out username varchar(20))
begin
select name into username # 将查询到的用户名赋值给 username
from t_user where id = userId;
end $
delimiter ;
调用,并查看结果: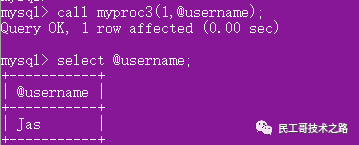
创建存储过程 myproc3,包含一个in参数和一个out参数 ; 调用时,传入删除的id 和 全局变量 @username ; select @username 输出结果。
包含 inout 参数的存储过程
drop procedure if exists myproc4;
delimiter $
create procedure myproc4(inout a int)
begin
set a = a * 2;
end $
delimiter ;
调用存储过程,并查询结果:
附:根据 时间 修改 状态:
delimiter $$
use `exam9` $$ ## exam9 是数据库
drop procedure if exists `updateStatus` $$ ## 如果存在,就删除
create procedure `updateStatus`()
begin
update exam set `status`="已结束" where `status` != "已结束" and (now() - endtime)> ;
update exam set `status`="正在答题" where `status` != "已结束" and ( now() - starttime)>=
and (now() - endtime)<=;
update haulinfo set bigstatus="已结束" where bigstatus != "已结束" and (curdate() - bigenddate)>;
update haulinfo set bigstatus="进行中" where (curdate() - bigenddate)<= and (curdate() - bigbegindate)>=;
update exam set bigstatus=(select bigstatus from haulinfo where bigid=exam.bigid);
end $$
delimiter ;
区别:
存储过程的优点:
存储过程 就是把经常使用的 sql语句 或 业务逻辑封装起来,预编译保存在数据库中,当需要的时候从数据库中直接调用,省去了编译的过程; 提高了运行速度; 同时降低网络数据传输量( 不用传一堆sql代码快,而是传一个存储过程名字和几个参数)。
存储过程 与 函数 的区别
一般来说,存储过程实现的功能要复杂一点,而函数的实现的功能针对性比较强。 存储过程可以有返回值也可以没有返回值,而自定义函数必须要返回值,且返回值有且只有一个。 存储过程一般是作为一个独立的部分来执行,而函数可以作为查询语句的一个部分来调用,因此它可以在查询语句中位于 from关键字的后面。 SQL 语句中不可用存储过程,而可以使用函数。
二、自定义函数 udf(user-defined function )
自定义函数 就像是 abs() 、 concat() 内建函数一样去扩展 mysql 。
所以,udf 是对 mysql 功能的一个扩展。
自定义函数 udf
创建 udf
drop function if exists [函数名];
delimiter [结束标记]
create function [函数名]([参数1], [参数2] ...) returns [返回值类型]
begin
[方法体]
return [返回值];
end [结束标记]
delimiter ;
参数,其格式为param_name type,如username varchar(20) 。
删除 udf: drop function [函数名]
3udf : select [函数名](param_value, ...)
示例
t_user 表中的数据:
无参数的自定义函数
查询 t_user 中的数据行数,并返回。
drop function if exists myfun1;
delimiter $
create function myfun1() returns int
begin
declare sum int default ; # 定义局部变量 sum,默认值为 0
select count(*) into sum # 将查询的结果赋值给 sum
from t_user;
return sum;
end $
delimiter ;
调用结果:
有参数的自定义函数
drop function if exists myfun2;
delimiter $
create function myfun2(userId int) returns varchar(20)
begin
set @username=''; # 定义系统会话变量
select name into @username # 将用户名赋值给 username
from t_user
where id = userId;
return @username;
end $
delimiter ;
查看结果:
复合结构
语法格式
delimiter //
create function if exist deleteById(uid smallint unsigned) returns varchar(20)
begin
delete from t_order where id = uid;
return (select count (id) from son);
end //
delimiter ;
delimiter 修改默认的结束符
delimiter // 表示 将默认的结束符由 ; 改为 // ,以后的sql语句都要以 // 作为结尾 。
returns 声明返回值类型
returns varchar(20) 声明 返回值 是 20位长度的字符串 。
returns int 声明返回值 int 。
reurn 定义 返回值
reurn 语句 也包含在begin...end 中。
declare 定义局部变量
declare var_name[,varname]...date_type [default value];
简单来说就是:
declare 变量1[,变量2,... ]变量类型 [default 默认值]
这些变量的作用范围是在begin…end程序中,而且定义局部变量语句必须在begin…end的行定义
示例:
delimiter //
create function addNum(x smallint unsigned, y smallint unsigned) returns smallint
begin
declare a, b smallint unsigned default 10; ### 定义局部变量
set a = x, b = y;
return a+b;
end //
delimiter ;
上边的代码只是把两个数相加,当然,没有必要这么写,只是说明局部变量的用法,还是要说明下:这些局部变量的作用范围是在 begin...end 程序中
变量
系统变量
全局变量 (global)
作用域:针对于所有会话(连接)有效,但不能跨重启。重启后,配置失效。
# 查看所有全局变量
show global variables;
# 查看满足条件的部分系统变量
show global variables like '%char%';
# 查看指定的系统变量的值
select @@global.autocommit;
# 为某个系统变量赋值
set @@global.autocommit=;
set global autocommit=;
会话变量(默认 session )
作用域:针对于当前会话(连接)有效
系统变量,如果不加 global 和 session ,则默认就是 session 。
# 查看所有会话变量
show session variables; ## 等价于 show variables;
# 查看满足条件的部分会话变量
show session variables like '%char%';
# 查看指定的会话变量的值
select @@autocommit;
select @@session.tx_isolation;
# 为某个会话变量赋值
set @@session.tx_isolation='read-uncommitted';
set session tx_isolation='read-committed';
自定义变量
用户变量 (全局的变量)
作用域: 用户变量 在当前连接(即当前会话)中都有效。
用户变量的特点:
不需要声明,直接使用, 前后数据类型可以不一样。
示例:
同一个用户变量,前后可以接收不同类型的赋值。
age 是 int
name 是varchar(20)
set @tmpVal = age; ## 将age的值赋给 @tmpVal
set @tmpVal = name; ## 将name的值赋给 @tmpVal
声明并初始化:
set @变量名=值;
set @变量名:=值;
select @变量名:=值;
赋值:
## 方式一:一般用于赋简单的值
set 变量名=值;
set 变量名:=值;
select 变量名:=值;
## 方式二:一般用于赋表 中的字段值
select 字段名或表达式 into 变量
from 表;
使用:
select @变量名;
局部变量
作用域: 局变变量在 begin end 语句中有效,超过范围即失效。
声明:
declare 变量名 类型 【default 值】;
declare name varchar(20) ;
declare num int default ;
局部变量 必须在 begin end 的行 。
赋值:
# 方式一:一般用于赋简单的值
set 变量名=值;
set 变量名:=值;
select 变量名:=值;
# 方式二:一般用于赋表 中的字段值
select 字段名或表达式 into 变量
from 表;
使用:
select 变量名
用户变量与 局部变量的区别:

事务和回滚点
事务
set autocommit=; ## 1、取消自动提交
start transaction; ## 2、开启事务
要执行的操作
commit; ## 3、提交事务
rollback; ## 4、回滚事务
存储过程和函数使用事务的格式:
begin
set autocommit=; ## 取消自动提交
start transaction; ## 开启事务
要执行的操作
commit; ## 提交事务
end ;
保存点
在事务中,设置保存点,当回滚时,能回滚到这个保存点,但是保存点之前的执行不会回滚。
set autocommit=; ## 取消自动提交
start transaction;
..... ## SQL语句
savepoint aa; ## 设置保存点,aa 是自定义的名称,保持
..... ## SQL语句
rollback to aa ## 回滚到保存点。 但是保存点前面执行的SQL执行依然有效。
流程控制
存储过程 和 函数 中可以使用 流程控制语句 来 控制SQL 的执行。
mysql中可以使用 if 、case 、loop、leave、iterate 、repeat和 while 语句 来进行流程控制。
每个流程中可能包含一个单独语句,或者是使用 begin...end 构造的复合语句,构造可以被嵌套。
if 函数
语法:
if(条件,值1,值2)
如果条件成立,则返回 值1,否则返回 值2
特点:可以用在任何位置。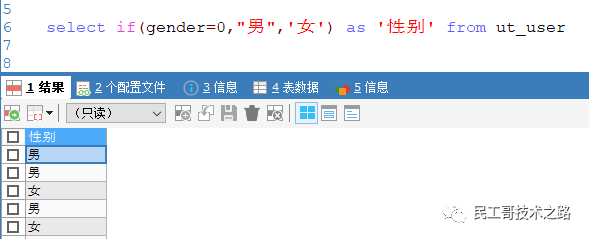
if 条件判断
根据是否满足条件,将执行不同的语句。
特点:
与 if 函数 的不同,这个if 条件只能用在 begin end 中 !!
if 语法:
if 表达式1 then 语句1;
elseif 表达式2 then 语句2;
...
else 语句n;
end if;
参数说明:
特点:只能用在 begin end 中 !!
注意: mysql还有一个if()函数,不同于这里描述的 if 语句。
if 示例:
if age>20 then
set @count1=@count1+1;
elseif age=20 then
set @count2=@count2+1;
else
set @count3=@count3+1;
end if;
说明:
根据age与20的大小关系来执行不同的set语句。 如果age值大于20,那么将count 1的值加1; 如果age值等于20,那么将count 2的值加1; 其他情况将 count3 的值加 1 。 后,if 语句都需要使用 end if来结束。
case when 条件判断
case when 也用来进行条件判断,其可以实现 比 if 更复杂的条件判断。
case when 语法:
类似于 switch
case 表达式
when 值1 then 结果1或语句1 ## 如果是语句,需要加分号
when 值2 then 结果2或语句2 ## 如果是语句,需要加分号
...
else 结果n或语句n ## 如果是语句,需要加分号
end 【case】 ## 如果是放在begin end中,则结尾处需要加上case,如果放在select后面不需要
说明:
如果是在 begin end中,则需要在每个 语句后面加 分号,case 结尾处加case;如果放在 select 后面,则每个语句后面不需要加分号, case 结尾处不需要加 case。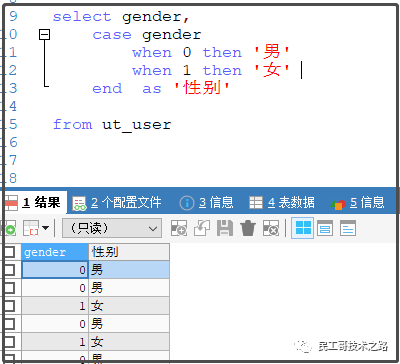
case when 语法2:
case
when 表达式1 then 结果1或语句1 ## 如果是语句,需要加分号
when 表达式2 then 结果2或语句2 ## 如果是语句,需要加分号
...
else 结果n或语句n ## 如果是语句,需要加分号
end 【case】 ## 如果是放在begin end中,则结尾处需要加上case,如果放在select后面不需要
说明:
语法1 的when 后面是值, 语法2 的when 后面是 表达式,可以进行区间的判断,
这个两个语法大的区别。
示列:

loop 循环
loop 可以使某些特定的语句重复执行,实现一个简单的循环。
但是 loop 本身没有停止循环的语句,必须使用 leave、iterate 等才能停止循环。
loop 语法:
[begin_label:] loop
statement_list
end loop [end_label]
参数说明:
1.begin_label 、end_label 分别表示 循环开始 和 结束的标志,这两个标志必须相同,而且都可以省略; 2.statement_list 表示需要循环执行的语句。
loop 示例
add_num: loop
set @count=@count+1;
end loop add_num ;
说明:
循环执行 count 加1的操作。 因为没有跳出循环的语句,这个循环成了一个死循环。 loop 循环都以 end loop结束。
leave 跳出循环(break)
leave 用于跳出循环。leave 用于 loop、repeat、while ,中断 并跳出循环。
leave 语法:
leave label
参数说明:
label 表示 循环的标志。
leave 示例:
add_num: loop
set @count=@count+1;
if @count=100 then
leave add_num ;
end loop add_num ;
循环执行 count 加1的操作。当 count 的值等于100时,则leave语句跳出循环。
iterate 跳出本次循环(continue)
iterate 也是跳出循环。但是,iterate 语句是跳出本次循环,然后直接进入下一次循环。
iterate 用于 loop、repeat、while 语句跳过本次循环。
iterate 语法:
iterate label
参数说明:
label 表示循环的标志。
iterate 示例:
add_num: loop
set @count=@count+1;
if @count=100 then
leave add_num ;
else if mod(@count,3)= then
iterate add_num;
select from employee ;
end loop add_num ;
说明:
循环执行 count 加1的操作。 当 count 值为100时结束循环。 如果 count 的值能够整除3,则跳出本次循环,不再执行下面的select语句。
leave 和 iterate 的区别
相同点:
leave 和 iterate 都用来跳出循环语句,但两者的功能是不一样的。
不同点:
leave 是跳出整个循环,然后执行循环后面的程序。 iterate 是跳出本次循环,然后进入下一次循环。
repeat (先)循环
repeat 是有条件控制的循环。当满足特定条件时,就会跳出循环语句。
repeat 语法:
repeat
statement_list
until search_condition # until 后面没有分号(;),否则 报错
end repeat;
参数说明:
1.statement_list 表示 循环的执行语句; 2.search_condition 表示 结束循环的条件,满足该条件时循环结束。
repeat 示例:
repeat
set @count=@count+1;
until @count=100
end repeat ;
循环执行count 加1的操作。
当 count 值为10 0时 结束循环。
repeat循环都用end repeat结束。
while (先判断,再)循环
while 也是有条件控制的循环语句。但while 和 repeat 是不一样的。
while 是当满足条件时,执行循环内的语句。
while 语法:
while search_condition do
statement_list
end while ;
参数说明:
1.search_condition 表示 循环执行的条件,满足该条件时循环执行; 2.statement_list 表示 循环的执行语句。
while 示例:
while @count<100 do
set @count=@count+1;
end while ;
循环执行count 加1的操作。 如果 count 值小于100时执行循环; 如果 count 值等于100了,则跳出循环。 while 循环需要使用end while 来结束。
循环示例
loop 循环的示例
delimiter $$
drop procedure if exists `sp_testloop` $$
create procedure `sp_testloop`(
in p_number int, #要循环的次数
in p_startid int #循环的起始值
)
begin
declare v_val int default ;
set v_val=p_startid;
loop_label: loop #循环开始
set v_val=v_val+1;
if(v_val>p_number)then
leave loop_label; # 终止循环
end if;
end loop;
select concat('testloop_',v_val) as tname;
end $$
delimiter ;
call sp_testloop(1000,);
while循环的示例
delimiter $$
drop procedure if exists `sp_test_while`$$
create procedure `sp_test_while`(
in p_number int, #要循环的次数
in p_startid int #循环的起始值
)
begin
declare v_val int default ;
set v_val=p_startid;
outer_label: begin #设置一个标记
while v_val<=p_number do
set v_val=v_val+1;
if(v_val=100)then
leave outer_label; #满足条件,终止循环,跳转到 end outer_label标记
end if;
end while;
select '我是while外,outer_label内的SQL';## 这句SQL在outer_label代码块内,所以level后,这句SQL将不会执行;
#只要是在outer_label代码块内 任意位置 Leave outer_label,那么Leave后的代码将不再执行
end outer_label;
select concat('test',v_val) as tname;
end$$
delimiter ;
call sp_test_while(1000,);
repeat 循环的示例
delimiter $$
drop procedure if exists `sp_test_repeat`$$
create procedure `sp_test_repeat`(
in p_number int, #要循环的次数
in p_startid int #循环的起始值
)
begin
declare v_val int default ;
set v_val=p_startid;
repeat #repeat循环开始
set v_val=v_val+1;
until v_val > p_number #终止循环的条件,注意这里不能使用';'分号,否则报错
end repeat; #循环结束
select concat('test',v_val) as tname;
end$$
delimiter ;
call sp_test_repeat(1000,);
来源:https://xiaojin21cen.blog.csdn.net/ article/details/105596615
