TDSQL(Tencent Distributed SQL)是腾讯基于 MySQL 研发的分布式数据库。TDSQL 的总体设计不在本文讨论范围之内,本文说的是如何在 TDSQL 基础上实现一个时态数据库(Temporal Database)。
什么是 Temporal Database?
Temporal 是 SQL:2011 标准中新增的特性。首先定义 Temporal 表:相比普通的表,一张Temporal 表带有 Valid Time 列或 Transaction Time 列(也可以两个都带)。
Valid Time和Transaction Time 都表示一条数据的有效时间段,是一个左闭右开区间 [start, end) ,二者区别在于:Valid Time 是由用户设定的,可以是过去或未来的时间段,比如指定YY年-YY年的利率是 X.XX%;而 Transaction Time 是系统自己维护的,当更新一个记录时无需指定时间戳,系统自动会记录它的时间戳,类似于 MVCC,只不过所有旧版本的数据都要保留。
对 VT 的查询很简单,其实就是个普通的过滤条件,比如 vt CONTAINS '2018-10-30',优化器会把它改写成 vt.start <= '2018-10-30' AND vt.end > '2018-10-30',很简单吧。本文之后不再讨论 VT,只讨论 TT 实现。
如何维护 Transaction Time?
我们先假想一个naive的实现:在 tuple 上加一列 Commit Timestamp,写数据或事务 Commit 的时候填上值。这样做是可以的,只是效率比较低:1. 每次 update 要拷贝一个 tuple,效率低; 2. 多出一个列,tuple 变长了 ; 3. 历史数据跟当前数据混在一起,可能影响scan效率。
TDSQL 的实现巧妙的利用了 InnoDB 本身的 MVCC 机制:利用 undo-log 提供历史读能力。但是 undo-log record 中只有 trx_id,怎样映射到 commit timestamp 呢?很简单,搞一个数组就可以了,因为 trx id 几乎是连续的,通过下标寻址就可以实现map的效果。这个东西在 TDSQL里叫做 transaction log。
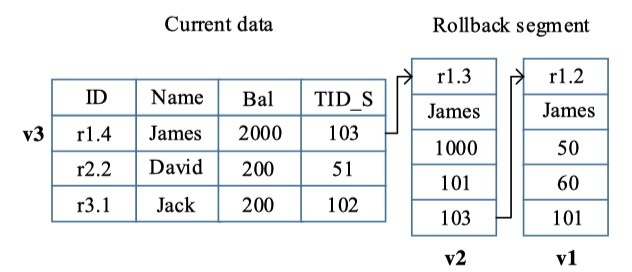
但是,上述的做法仅对近的事务适用。MySQL本身就有purge机制,会清理掉旧版本数据、防止回滚段无限增长。
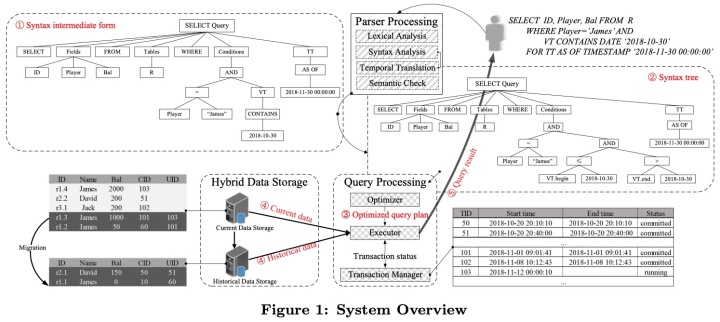
TDSQL的做法是另外搞了个KV存储,专门放历史数据。purge的时候,会将历史版本带上commit时间戳放到KV里保存。这个过程称为 migration。由于 purge过程是后台线程异步进行的,它对性能的影响比较小。
总结一下:
- 尚未purge的版本记录:保存在undo-log中,仅包含有变化的列和 trx id 信息,由 InnoDB 本身维护
- 已purge的版本记录:purge的时候迁移到另外的KV存储中,同时在记录中附带上 commit timestamp 信息
带有 Transaction Time 的查询
有两种查询:
- AS OF 查询:指定一个时间戳进行查询
- FROM TO / BETWEEN AND 查询:指定一个时间段进行查询
其实区别不大,只要能拿到 record 的 version的时间戳,就很容易判断了。
- 尚未purge的版本记录:可以通过 transaction log 将 trx id 映射到 commit timestamp
- 已purge的版本记录:直接拿记录带的 commit timestamp
