一 前言
气象数据是个典型的时序数据,例如自动站监测风、温、湿、压等数据,每分钟都有新监测数据,数据只有插入和查询,没有修改操作,数据量大,业务上有累计10分钟降水,累计30分钟降水等需求,这样的需求使用时序数据库去存储是合适不过了。
同时自动站本身具有经纬度、高度等空间位置信息,实际业务中监测数据可以根据位置空间插值成等值线面。
PG丰富的插件正好就比较适应气象这样的业务场景,其通过PostGIS插件支持空间数据存储检索分析,通过TimeSacleDB插件支持时序数据存储检索分析。
本文重点介绍如何使用PG的时序数据库插件timescaledb。
二 timescaledb特点
TimeScaleDB是基于PostgreSQL的时序数据库插件,用户可以通过sql就可以进行时序数据的统计分析,入门非常简单。截至目前(2021-07-14)TimeScaleDB新版本是2.3.0,该版本特点是后一版支持PG11的版本,版支持分布式的版本,该版本是个里程碑版本。
虽然PG内置了range分区、list分区、hash分区,带时间类型数据通常通过时间的range分区去优化,再根据list、hash创建二级分区优化查询,然后各种优化数据过期也要自己写job等。就和比赛分专业与业余一样,时序数据库应该就是时间类型数据应用的专业赛道,其提供大量的管理查询分析工具在功能上性能上进行扩展和优化。简单列举下timescaledb特点便可以知道时序数据库与分区表的差异:
- 支持关系表一键转换成时序数据表(超表)。
- 时序数据大,可以支持超表的分布式管理,节点增删改等(新增)。
- 时序数据大,可以支持数据压缩。
- 物化视图支持数据的连续聚合,如逐时数据的统计。
- 自定义设置数据保留策略,过期数据自动删除。
- 内置特殊的自定义函数用于时序超表的查询和统计。
- 时序数据库的元数据管理和查看函数等方便用户管理。
在实际使用前,入门还是要写一下安装步骤的。
三 插件安装
- 安装PG
源码安装,注意.configure带上 --with-openssl
安装教程:
- 安装timecaledb
# 下载源码
wget https://github.com/timescale/timescaledb/archive/refs/tags/2.3.1.tar.gz
# 解压
tar -zxvf 2.3.1.tar.gz
# 进入目录编译
cd timescaledb-2.3.1
# source pg环境变量,以获取pg_config
source /home/postgres/.bashrc
# 编译
./bootstrap -DREGRESS_CHECKS=OFF
make -j 4
make install- 修改postgresql.conf
vi $PGDATA/postgresql.conf
# 修改配置文件
shared_preload_libraries = 'timescaledb'修改完毕后,重启pg服务,创建测试数据库,在数据库中创建扩展:
postgres=# create database aa;
CREATE DATABASE
postgres=# \c aa
You are now connected to database "aa" as user "postgres".
aa=# create extension timescaledb;
WARNING:
WELCOME TO
_____ _ _ ____________
|_ _(_) | | | _ \ ___ \
| | _ _ __ ___ ___ ___ ___ __ _| | ___| | | | |_/ /
| | | | _ ` _ \ / _ \/ __|/ __/ _` | |/ _ \ | | | ___ \
| | | | | | | | | __/\__ \ (_| (_| | | __/ |/ /| |_/ /
|_| |_|_| |_| |_|\___||___/\___\__,_|_|\___|___/ \____/
Running version 2.3.1
For more information on TimescaleDB, please visit the following links:
1. Getting started: https://docs.timescale.com/timescaledb/latest/getting-started
2. API reference documentation: https://docs.timescale.com/api/latest
3. How TimescaleDB is designed: https://docs.timescale.com/timescaledb/latest/overview/core-concepts
Note: TimescaleDB collects anonymous reports to better understand and assist our users.
For more information and how to disable, please see our docs https://docs.timescale.com/timescaledb/latest/how-to-guides/configuration/telemetry.
CREATE EXTENSION四 业务场景测试
场景介绍:2500个自动站,每个站点每分钟会有一个降水监测数据,数据库要求数据保留7天,业务查询时,可查询近10分钟累计降水量,近30分钟累计降水量,1h内累计降水量,3h内累计降水量,6h内累计降水量,12h内累计降水量。
构造站点数据:
create table t_aws(
id text primary key, --站点id
name text not null, --站点名称
level text not null, --站点级别
alti numeric not null, --站点高度
geom geometry(Point, 4326) --站点位置
);
--创建空间索引
create index t_aws_geom_idx on qxcp.t_aws using gist(geom);
--模拟中国境内站点数据
--插入测试站点数据
do language plpgsql $$
DECLARE
i int;
BEGIN
for i in 1..2500 loop
insert into t_aws(id,name,level,alti,geom) values (
i::text,'a','b',0,ST_SetSrid(
ST_MakePoint(
random()*(135-70)+70,
random()*(55-10)+10
),4326)
);
end loop;
end;
$$;方案一:普通关系表
首先基于普通表做个性能测试,便于之后与时序表查询做对比:
drop table if exists t_aws_min_info;
CREATE TABLE t_aws_min_info (
station_id text not null,--站点id
date_time timestamp without time zone NOT NULL, --数据时间
protuct_id text, --气象产品id
data_value numeric(8,2) --气象产品监测值
);
--建个普通表的索引
create index t_aws_min_info_idx on t_aws_min_info using btree(station_id,date_time);插入测试7天模拟数据:
do language plpgsql $$
DECLARE
i int;
BEGIN
-- 60*24*7
for i in 1..10080 loop
-- 模拟每分钟降水0-10之间
INSERT INTO t_aws_min_info(station_id,date_time,protuct_id,data_value)
select generate_series(1,2500),timestamp '2021-07-14 11:00:00'- (10080-i)*interval '1 minutes',
'pre',random()*10;
raise notice '%',i;
end loop;
end;
$$;查询数据总量:
select count(*) from t_aws_min_info;
count
----------
25200000查询10分钟累计降水量,耗时578ms:
select station_id,sum(data_value) from t_aws_min_info where
date_time>timestamp '2021-07-14 11:00:00' - INTERVAL '10 minutes'
group by station_id; 查询1小时累计降水量,耗时617ms:
select station_id,sum(data_value) from t_aws_min_info where
date_time>timestamp '2021-07-14 11:00:00' - INTERVAL '1 hours'
group by station_id;查询12小时累计降水量,耗时748ms:
select station_id,sum(data_value) from t_aws_min_info where
date_time>timestamp '2021-07-14 11:00:00' - INTERVAL '12 hours'
group by station_id;方案二:时序数据表
构造自动站分钟级别监测数据:
drop table if exists t_aws_min_info;
CREATE TABLE t_aws_min_info (
station_id text not null,--站点id
date_time timestamp without time zone NOT NULL, --数据时间
protuct_id text, --气象产品id
data_value numeric(8,2) --气象产品监测值
);
create index t_aws_min_info_idx on t_aws_min_info using btree(station_id);将关系表转换成时序数据库的超表:
SELECT create_hypertable('t_aws_min_info', 'date_time');模拟数据,sql同上文。
查询10分钟累计降水量,sql同上文,耗时12ms。
查询1小时累计降水量,sql同上文,耗时50ms。
查询12小时累计降水量,sql同上文,耗时220ms。
简单小结:
- 很明显相比普通关系表,时序数据表性能更优。
- 数据量很大的时候,时序表查询耗时也会递增。
在某些业务场景中,如逐小时统计,可采用时序数据库的Continuous Aggregates功能,使用物化视图加速快速获取统计结果,该视图会根据数据自动刷新。(有点像流式数据库的实时统计,不过流式数据库是根据规则自动统计出来的,不是物化视图,也不要刷新)
- 时间字段是有序递增的,而不能是零散的。
测试数据起始时间是从7天前开始,数据时间是递增的,符合传感器接入数据的特点。如果改下测试数据,随机生成时间字段,时间是无序的,时序统计的时候耗时会很大,普通关系表如果对时间字段建立索引,时间是递增还是无序应该差不多。所以时序数据库并不是时间字段分区和时间字段索引,是更符合物联网场景那种连续时刻数据的短期数据接入。
补充说明下,时序数据库的时间一定是有序的,不是离散的,timescaledb提供的last和first函数就能说明,这两个函数不使用索引,而是对它们的数据组执行顺序扫描。它们主要用于groupby aggregate中的有序选择,而不是用于替代ORDER BY time DESC LIMIT 1子句来查找新值。
例如我们对时序表,查询近10分钟类新的降雨量信息:
select station_id,last(data_value,date_time) from
t_aws_min_info where
date_time > timestamp '2021-07-14 11:00:00' - INTERVAL '10 minutes'
GROUP BY station_id;五 结果可视化
我们有站点空间数据,使用PostGIS存储,有时序数据使用TimeScaleDB存储,当我们需要把统计分析结果的数据可视化到地图上时候就非常容易了:
with analyseResult as (select station_id,sum(data_value) as pre_12h
from t_aws_min_info where
date_time>timestamp '2021-07-14 11:00:00' - INTERVAL '12 hours'
group by station_id) select a.*,b.pre_12h from qxcp.t_aws a,
analyseResult b where a.id=b.station_id;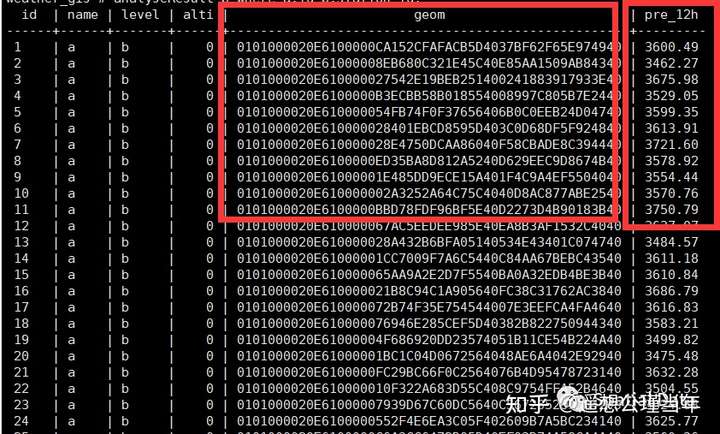
查询速度非常快,结果有图形,也有统计结果属性值,熟悉WebGIS的朋友应该很容易就知道拿到这样的数据如何处理,例如根据空间图形点和统计结果插值成格网,格网再以等值线面形式可视化即可,本文数据是测试数据,效果不好,但终显示结果类似下图:
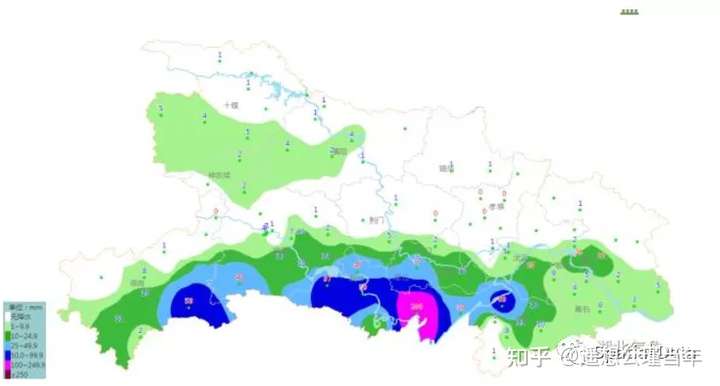
累计降水量
来源 https://zhuanlan.zhihu.com/p/396384316
