👆戳蓝字“守护石”关注
首先我们应该更具体的理解这样一个现象,为什么流行的技术框架会被淘汰。谈到淘汰,常见两种情况:
:应用模式被淘汰了,例如:BB机,功能机,终被智能机淘汰,胶卷被数码相机淘汰,即便诺基亚的功能机做得再完美,也会被淘汰。软件方面例如:终端的字处理,邮件收发等应用软件被视窗应用软件淘汰。
第二:技术升级,新技术弥补了老技术的缺陷,并且引入了更多有优势的功能。例如:Springframework的横空出世,配合Hibernate,在具有同样功效的情况下,解决了EJB的部署复杂,体态臃肿,计算效率低,用灵活性,面向程序员的友好性,淘汰了曾经企业级经典的EJB。
那么对于Hadoop分布式文件系统(HDFS),我们要讨论它的淘汰可能性,淘汰时间,首先我们就要看它为什么要被淘汰的因素。从模式上,分布式文件系统是大数据存储技术极为重要的一个领域,我们还看不到分布式文件系统有被淘汰的任何理由,那么我就再看技术升级是否有淘汰它的可能性。
谈技术升级,首先要看HDFS的缺点,然后再看这种缺点的解决办法,是否会带来新的技术框架,然后让HDFS埋进历史的垃圾堆。
HDFS的缺点,我们在研究和使用过程中,主要发现有三个问题:
部署复杂
元数据的内存瓶颈
默认副本数占用存储空间
HDFS为集中式协调架构,namenode若是单节点,部署并不复杂,但是namenode作为单节点无法可靠的运行在生产环境,必须对namenode实现双机HA,那么部署复杂度就变得极高,这时候需要在namenode,datanode的基础上再引入namenode active,namenode standby的概念,需要引入QJM的元数据共享存储并基于Paxos做一致性协调,另外需要引入ZKFC和ZooKeeper,解决主备选举,健康探测,主备切换等操作。
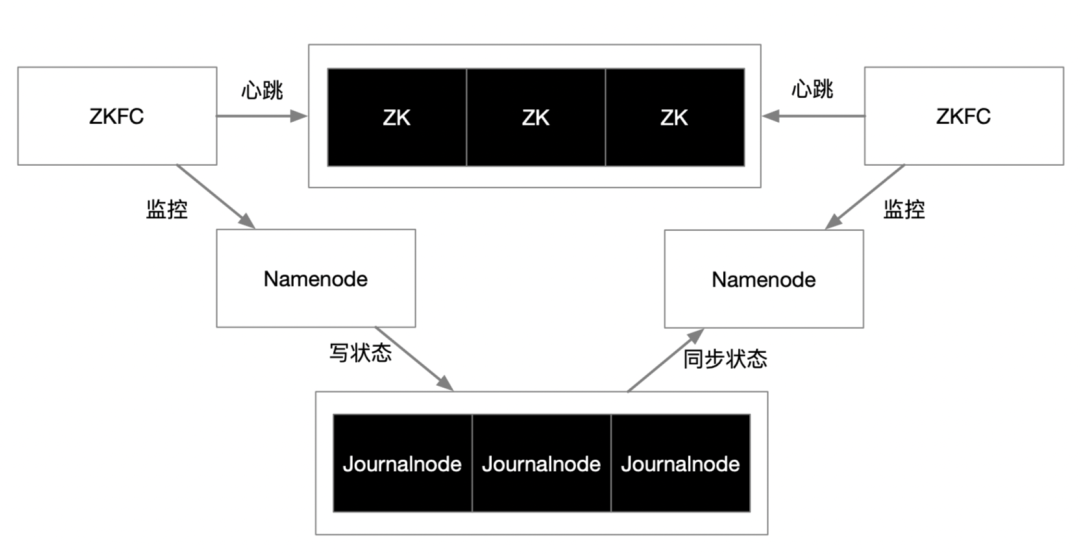
复杂的HDFS HA架构
因此HDFS的部署复杂度完全是因为namenode HA导致的。这是集中式管理的分布式架构一个原生问题,如果在这个地方进行优化的话,那么就是简化QJM,ZKFC,ZooKeeper的多组服务,用一组服务来代替,但是namenode和datanode的分布式数据块的读写,复制,恢复机制,目前看非常成熟,高效,这是核心问题,并不是缺点,不需要更具颠覆性的优化。
由于namenode在内存中记录了所有数据块(block 默认128M)的信息,索引了数据块与datanode的关系,并且构建了文件系统树,因此可想而知namenode的元数据内存区是大量占用内存,这是没有上限的。对于较大型数据存储项目,例如上百个datanode节点和上千万个数据块的容量来说,元数据在namenode的内存大概能控制在32G以内,这是还没问题的,但是对于构建海量数据中心的超大型项目,这个问题就好像达摩克斯之剑,首先堆内存超过临界范围导致的内存寻址性能问题不说,一旦namenode内存超限到单机内存可承载的物理上大承受范围,整个hdfs数据平台将面临停止服务。
这个问题的本质还是Google设计GFS时候采用粗放的实用主义,先把元数据都交给主节点在内存中节制,超大问题以后再解决。目前Google的GFS2设计上,已经将元数据在内存中迁移至了BigTable上,那么问题就来了:“BigTable基于GFS,而GFS2的元数据基于BigTable”?有点鸡生蛋还是蛋生鸡的自相矛盾。是的,看似矛盾实质上是架构的嵌套复用,可以这么去解读:GFS2是基于<基于GFS的BigTable的元数据存储>的下一代GFS架构。用BigTable的k-v存储模型放GFS2的元数据,虽然没有内存高效,但是够用,而且可以无限存储,用BigTable专门存储元数据形成的k-v记录终保存成GFS数据块,因此在GFS的元数据内存中只需少量的内存占用,就能支撑天量的真正应用于数据块存储的GFS2元数据。
基于GFS2的设计思想,我相信下一代HDFS应该也是这样的方案去解决元数据的内存瓶颈问题,也就是基于<基于HDFS的HBase的元数据存储>的下一代HDFS架构。那么HDFS的元数据瓶颈问题将被彻底解决,很难看到比这更具优势的替代性技术框架了。
如下图所示:
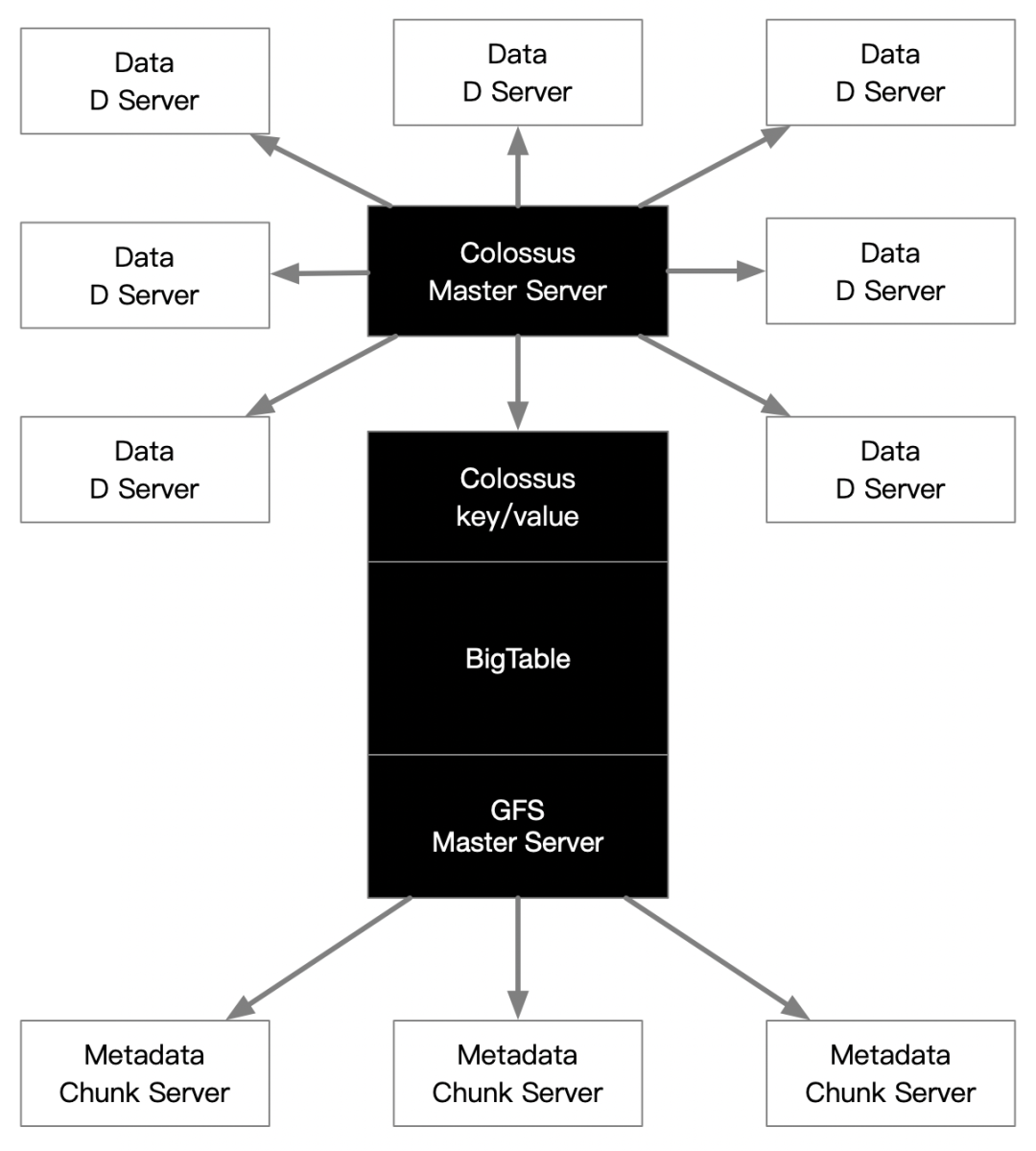
GFS V2假想图
副本数默认为3大的问题就是占空间,这几乎是所有传统分布式文件系统(DFS)的通病。因此HDFS集群的默认空间利用率只有33.3%,这么低的利用率显然不符合一些场景,例如长期的冷数据备份,那么有没有更好的方式呢?是有的,目前比较成熟的方案就是纠删码技术,类似raid5,raid6,HDFS 3.0版本以后支持这种模式,叫做Erasure Coding(EC)方案。
HDFS是怎么通过EC方案解决磁盘利用率的问题呢?我们先聊点比较硬的原理,说说EC方案之一的条形布局:
首先数据文件写的时候会向N个节点的块(Block)依次写入,N个Block会被切成多组条(stripe 1... stripe n),如果分布式环境有五个存储节点(DataNode),那么就把stripe切成3个单元(cell),然后再根据这3个cell计算出2个校验cell,然后这5个cell(3个data+2个parity)分别写入5个Block中。数据条就这么依次轮巡的方式,将校验块的位置轮换存储在不同Block上,直至写满,这样校验块的分布可以更均匀。
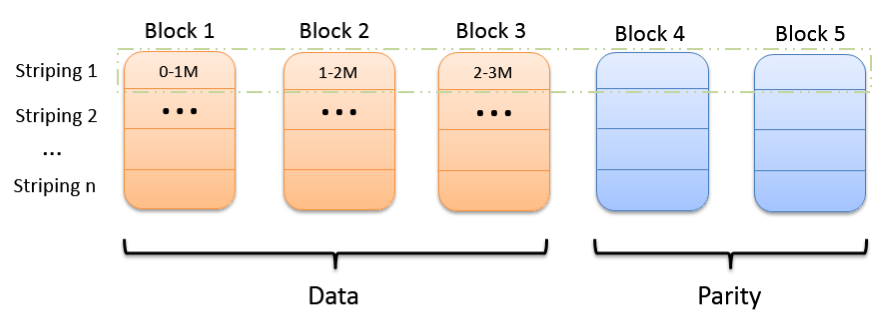
HDFS EC Striping Layout
其次再说取数据,取数据每次只从3个DataNode中各取出1个cell,如果这3个cell都是数据cell,那么就成功拿到一组数据条stripe,如果有一个cell是校验cell,那么就能通过校验cell和另外2个数据cell计算出第3个数据cell,完成数据条stripe的组合。这种情况下,即便是5个datanode节点有2个datanode宕机了,另外3个datanode也能通过校验码计算完成剩余2个节点的数据,这就是利用纠删码技术实现数据冗余的原理。
通过这种方式,我们就比传统2副本50%,3副本33.3%的多副本模式要省空间,EC中2+1可以达到66.7%的磁盘利用率,例子是3+2可以达到60%的磁盘利用率
但是其问题是特别消耗CPU计算,上面那种读取情况,五分之三的读取数据条时间都要进行校验码计算。因此可以利用Intel CPU推出的ISA-L底层函数库专门用于提升校纠删码算法的编解码性能。通常情况下,纠删码用于冷数据的冗余,也就是不经常访问,但又必须联机存储以备查询的数据。除了磁盘利用率,多副本方式用空间换效率的方式肯定是好,没什么问题。
