业务有成百上千张表,每张表有上百个列。
在如下场景中:每张表的数据量都不多(几亿几十亿),但是表数量特别多(几十张甚至几百张表)
如果为每个表都创建一个物理表,则会造成资源的浪费。同时存在如下问题:
每张物理表都需要维护自己的BUFFER,极易OOM,导入性能太差。
每张物理表都需要单独开个线程去维护。
每张物理表生成的索引都很小,但由于文件数量太多,频繁合并索引会导致namenode非常繁忙。
等等,总之小表数量过多,会存在诸多问题。
在搜索时,如果需要根据关键字搜索含有该关键字的所有字段对应的所有表的对应记录,采用物理表意味着每张表都需要写一个sql,若查询过滤条件拼了N个OR查询,则会导致SQL语句很长,同时并发性能也会很差。
映射表简介
如今LSQL的映射表帮我们解决上述问题。对于资源汇聚类型的搜索可以一条sql就搞定,既兼容原先的表结构,业务其他部分也依然可以单表查询。
映射表是建立在物理表的基础上的。一张物理表上面可以放很多映射表,这些表统一管理,统一心跳,统一一个索引,对外部用户来说对映射表的查询和对物理表的查询,在使用上不存在区别。
有了映射表以后,原先需要为那些小业务分别创建表,单独搭建集群的问题也可以得到解决。规模不大的业务,可以共享同一个集群,共享同一个物理表,业务和业务之间是图表隔离。
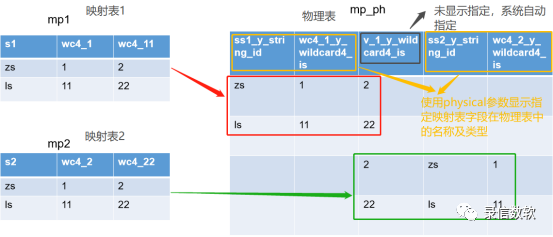
映射表并不真实存储数据,如下图所示,映射表通过映射将数据存储在其对应的物理表中。
基本用法

创建映射表

创建LSQL映射表的方法,与创建物理表区别不大。
创建LSQL映射表要使用create mapping语法(物理表的语法为create table)
例子1如下:
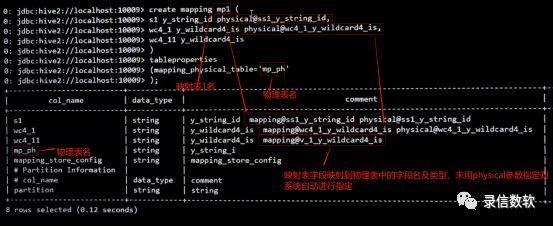
create mapping mp1(s1 y_string_id physical@ss1_y_string_id, /*显示置顶映射到物理表中的字段,如果没设置physical,则由系统指定*/wc4_1 y_wildcard4_is physical@wc4_1_y_wildcard4_is,wc4_2 y_wildcard4_is)tableproperties(mapping_physical_table=’mp_ph’ /*映射到哪张表里去*/);注:
create mapping:创建映射表固定语法
mp1:要创建的映射表名
s1 y_string_id:映射表中字段名、字段数据类型
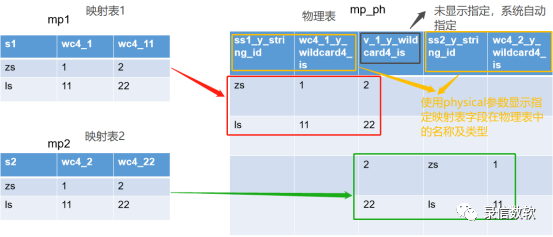
physical@ss1_y_string_id:通过physical参数来指定当前映射表字段在其物理表中的映射字段名字,如physical@s1s_y_string_id,表示将当前字段映射到ss1_y_string_id 的字段里,这个字段本质上是一个动态列(物理表里无法预先知道映射表的字段名称,故只能采用动态列),ss1是字段名字,y_string_id是映射字段的数据类型,,这里的数据类型必须采用y_开头的类型,目前不支持简写
mapping_physical_table:设定映射到哪张物理表去时的固定语法
mp_ph:映射表所映射到的物理表名(物理表无需事先创建)
创建映射表1基本用法详情图如下:
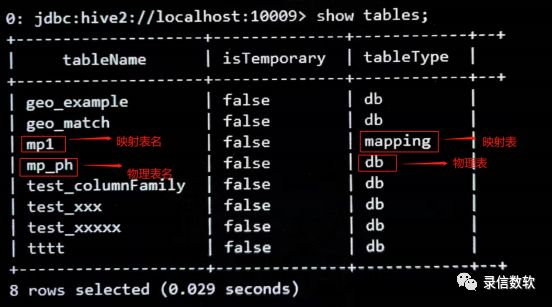
创建完成后会生成两张表(映射表、物理表),如下图所示:
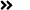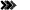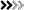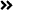
创建映射表例子2如下:
create mapping mp2(s2 y_string_id physical@ss2_y_string_id, /*显示置顶映射到物理表中的字段,如果没设置physical,则由系统指定*/wc4_2 y_wildcard4_is physical@wc4_2_y_wildcard4_is,wc4_22 y_wildcard4 _is )tableproperties(mapping_physical_table=’mp_ph’ /*映射到哪张表里去*/);例子2创建详情如下图所示:

因上述映射表在创建时映射的物理表和例子1中是同一张物理表,因此在创建完成后只会新生成一张表(映射表),如下图所示:

mp1(映射表1)、mp2(映射表2)、mp_ph(物理表)三张表详情如下图所示:

由上可知,映射表真实底层存储情况如下图所示(图中数据为模拟数据):

数据导入

(1) 原始数据(路径:/wyh/mp.log)如下图所示:

(2) 向映射表中导入数据的方法与物理表中导入数据的方法完全一样。示例如下:
./load.sh -t mp1 -tp txt -local -f /wyh/mp.log -sp , -fl s1,wc4_1,wc4_11(3) 导入数据后对映射表、物理表做全表查询:
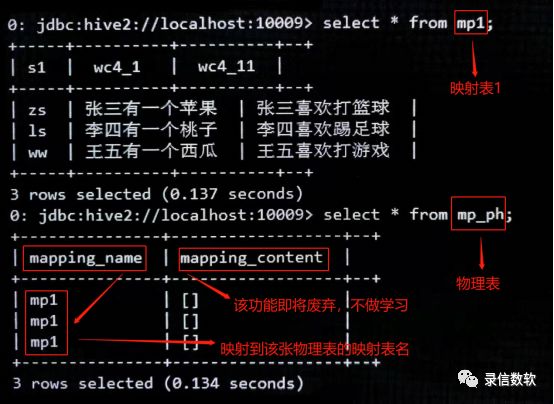

查询方法

查询显示指定的物理表字段名及系统自动指定的物理表字段名:

映射表汇聚
将表中已有的字段中的数据汇聚到一个新的字段中进行存储的机制,用以解决数据搜索过程中不知道位置的问题的方法叫做汇聚存储。
自定义汇聚表示用户可以自行定义汇聚列,包括汇聚列名字、需要汇聚的字段和是否汇聚字段的字段名。
汇聚存储可以解决搜索的内容不知道在表的哪个字段中,可以做到全表匹配。再结合分词数据类型即可做到全文检索的特性。

创建带有汇聚功能的映射表

汇聚例子如下:
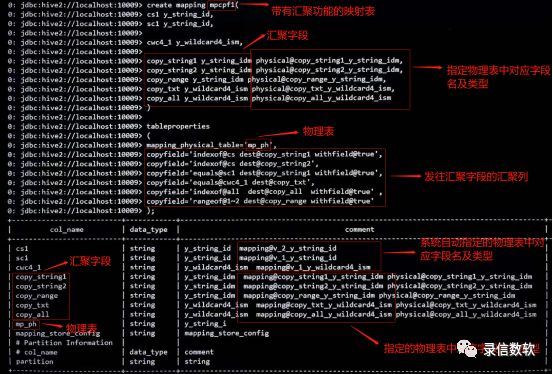
create mapping macpf1(cs1 y_string_id,sc1 y_string_id,
cwc4_1 y_wildcard4_ism,
copy_string1 y_string_idm physical@copy_string1_y_string_idm,copy_string2 y_string_idm physical@copy_string2_y_string_idm,copy_range y_string_idm physical@copy_range_y_string_idm,copy_txt y_wildcard4_ism physical@copy_txt_y_wildcard4_ism,copy_all y_wildcard4_ism physical@copy_all_y_wildcard4_ism)tableproperties (mapping_physical_table=’mp_ph’,/*映射到哪张表里去*//*汇聚1:汇聚字段名称包含cs的数据(cs1),withfield@true表示含有原始字段的名称*/copyfield='indexof@cs dest@copy_string1 withfield@true',/*汇聚2:汇聚字段名称包含cs的字段的数据(cs1),不含原始字段的名称*/copyfield='indexof@cs dest@copy_string2',/*汇聚3:汇聚字段’sc1’中的数据(copy_string1在汇聚1中已做汇聚,可以继续对其添加汇聚数据,不会对之前的内容造成覆盖),withfield@true表示含有原始字段的名称*/copyfield='equals@sc1 dest@copy_string1 withfield@true',/*汇聚4:汇聚’cwc4_1’中的数据,不含原始字段的名称*/copyfield='equals@cwc4_1 dest@copy_txt',/*汇聚5:汇聚所有字段中的数据,withfield@true表示含有原始字段的名称*/copyfield='indexof@all dest@copy_all withfield@true',/*汇聚6:汇聚第1~2个字段中的数据(cs1、sc1),withfield@true表示含有原始字段的名称*/copyfield='rangeof@1~2 dest@copy_range withfield@true');注:
cs*、sc*、cwc4*:代表原始字段。
copy_*:代表要发往目标汇聚字段。
copyfield:代表字段数据汇聚关键字。
withfield@:true代表汇聚字段含有原始的字段名称,该关键字不声明则代表汇聚字段不含原始字段名称。
indexof@:可以使用all关键字匹配所有字段,也可以用字段模糊匹配,比如:cs,匹配含有cs字符的字段。
dest@:代表汇聚的数据发往哪个目标字段中的关键字。
equals@:代表需要进行汇聚的明确的字段名称的关键字。

数据导入

(1) 原始数据(路径:/wyh/mpcpf.log):

(2) 向映射表中导入数据的方法与物理表中导入数据的方法完全一样。示例如下:
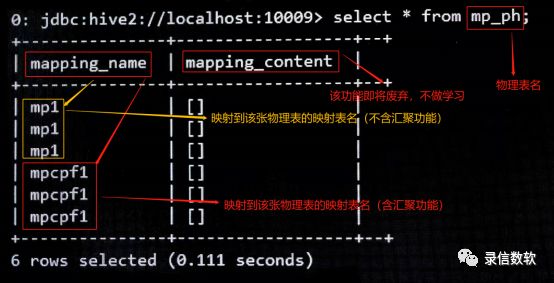
./load.sh -t mpcpf1 -tp txt -local -f /wyh/mpcpf.log -sp , -fl cs1,sc1,cwc4_1(3) 导入数据后对映射表、物理表做全表查询:

注:创建表时进行汇聚时未声明withfield@true的汇聚内容,在查询时只展示字段值,如["zs"]的形式,若声明withfield@true关键字,展示形式为原始字段名称@字段值,如["cs1@zs"]的形式。

查询方法

(1) 查看每张表的数据量(对物理表做查询):
select count(*) from mp_ph;select mapping_name,count(*) from mp_ph group by mapping_name;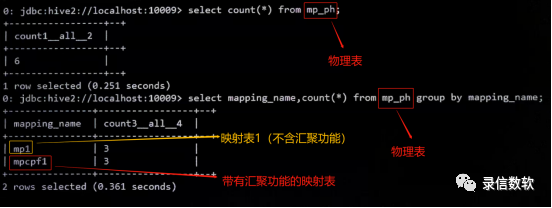
(2) 指定字段查询(显示指定及系统自动指定):
select cs1,sc1,cwc4_1 from mpcpf1;select v_2_y_string_id,v_1_y_string_id,v_1_y_wildcard4_ism from mp_ph where mapping_name=’mpcpf1’;
select copy_string1,copy_string2,copy_range,copy_txt,copy_all from mpcpf1;select copy_string1 y_string_idm,copy_string2 y_string_idm,copy_range y_string_idm,copy_txt y_wildcard4_ism,copy_all y_wildcard4_ismfrom mp_ph where mapping_name=’mpcpf1’;
(3) 汇聚字段查询(对映射表做查询,解决待查询的数据不知道属于哪个字段的问题):
select * from mpcpf1;select * from mpcpf1 where copy_all = ‘早餐’;
select * from mpcpf1;select * from v_2_y_string_id,v_1_y_string_id,v_1_y_swildcard4_ism,copy_string1_y_string_idm,copy_string2_y_string_idm,copy_range_y_string_idm,copy_txt_y_swildcard4_ism,copy_all_y_swildcard4_ism from mp_ph where mapping_name=’mpcpf1’ and copy_all_y_swildcard4_ism=’早餐’;
